Python模块---制作属于自己的有声小说
操作环境
Python版本: anaconda3 python3.7.4
操作系统: Ubuntu19.10
编译器: pycharm社区版
用到的模块: pyttsx3,requests
pysstx3模块介绍
pyttsx3官网地址
pyttsx3(Text to Speech)是一个语音转换模块,它可以在离线的环境下工作,支持多个引擎,而且兼容于Python2和Python3.
首先下载pyttsx3模块
pip install pyttsx3
(Windows系统)若你没有安装pywin32模块,则还需安装此模块作为pyttsx3模块的依赖
安装pywin32
pip install pywin32
这个模块很奇怪,下载的过程中经常会报错,试了几台电脑和不同操作系统的结果也是一样,在检查网络和其他因素无误后多试几次就可以成功安装此模块.
安装成功提示如下图

注意:这个模块运行必须在python3.7.4版本及以下才可以运行,否则会由于版本过高报错
如果不知道自己的Python版本是多少,可以再终端输入,输出的第一行就是目前使用的Python版本号
测试pyttsx3库
根据官网给出的简单示范,我们可以测试一下是否可以使用本模块
测试代码:
import pyttsx3
engine = pyttsx3.init()
engine.say("I will speak this text")
engine.runAndWait()
若可以听到一个男声快速的说了一遍我们引用的句子,则证明本模块安装已经成功
自定义修改朗读的语调、音色等参数
也是参照官方文档,将这些参数调整成一个比较舒服的状态
import pyttsx3
engine = pyttsx3.init() # 创建对象
""" 语速 """
rate = engine.getProperty('rate') # 获取当前语速(默认值)
print (rate) # 打印当前语速(默认值)
engine.setProperty('rate', 175) # 设置一个新的语速
"""音量"""
volume = engine.getProperty('volume') # 获取当前的音量 (默认值)(min=0 and max=1)
print (volume) # 打印当前音量(默认值)
engine.setProperty('volume',1.0) # 设置一个新的音量(0 < volume < 1)
"""音色"""
voices = engine.getProperty('voices') # 获取当前的音色信息
engine.setProperty('voice', voices[0].id) # 改变中括号中的值,0为男性,1为女性
engine.say("Hello World!")
engine.runAndWait()
engine.stop()
在Windows系统中,这一段代码已经可以通过pyttsx3模块说出中文了,但是在Linux操作系统中,还需要修改一个参数
engine.setProperty('voice','zh') //将音色中修改音色的语句替换
开始制作有声小说
通过刚才对pyttsx模块的讲解,我们已经可以了解到该模块的基本原理以及各个参数所代表的含义,接下来我们就以pyttsx3模块为基础构建一个简单的有声小说.
基本思路
使用爬虫requests模块将小说文本从从网上下载到本地,并将内容保存在一个文本文件中,然后打开文本文件,调用pyttsx3模块对文字进行识别,并朗读出来.
操作步骤
首先找到一个小说网站(我选择的是新笔趣阁小说网 因为这个网站没有设置反爬机制 比较适合我们练手)
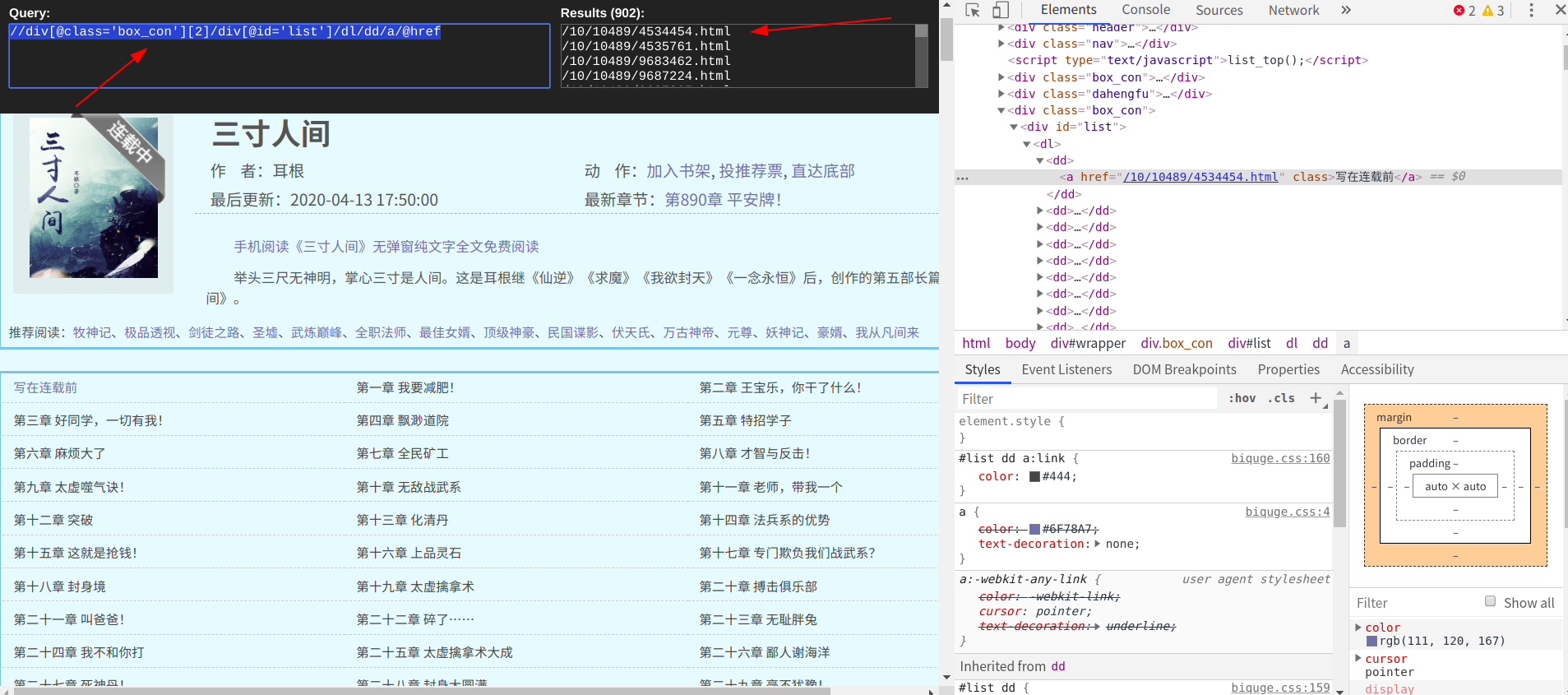
然后随便找到一个小说,进入它的目录页,借助谷歌浏览器的插件xpath helper利用xpath语法提取到每一章小说
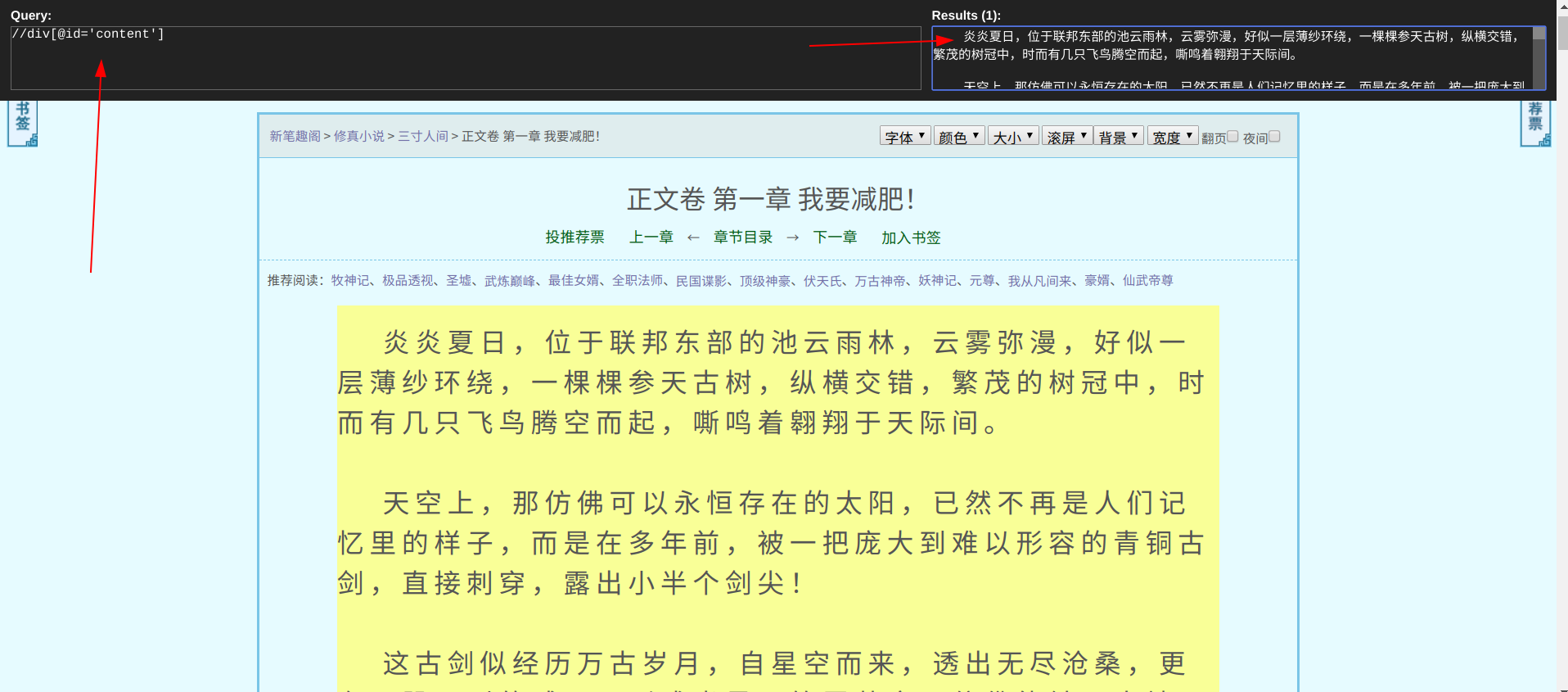
点进小说的内容页,同样利用插件提取到内容
然后就可以开始构建爬取小说的代码了
为了节省时间,我先简单的爬取一个章节
import requests
from lxml import etree
def main():
#小说的详情页
url = 'http://www.xbiquge.la/10/10489/'
#请求内容
response = requests.get(url).text
#转化成xpath语法可以提取的形式
html = etree.HTML(response)
#提取小说内容页的网址
data = html.xpath("//div[@class='box_con'][2]/div[@id='list']/dl/dd/a/@href")
#为了节省时间,先只提取一个章节的内容
sound = data[1]
#构造小说内容页的网址
new_url = 'http://www.xbiquge.la' + str(sound)
#请求
response_1 = requests.get(new_url).content
html_1 = etree.HTML(response_1)
data_1 = html_1.xpath("//div[@id='content']/text()")
#用replace方法将提取到文本中的\xa0替换掉
noval = str(data_1).replace('\\xa0', '')
#替换掉\r
noval_1 = noval.replace("\\r',", '')
#将爬取到的小说内容存储到文本文件中
with open('xiaoshuo.txt','w') as f:
f.write(noval_1)
if __name__ == '__main__':
main()
运行完成之后,就可以发现当前文件夹下多出了一个名为xiaoshuo.txt的文件,这就是我们爬取到的小说内容
导入有声阅读模块
def say(filename='xiaoshuo.txt'):
with open(filename, 'r') as f:
line = f.read()
engine = pyttsx3.init()
engine.setProperty('volume',1.0)
engine.setProperty('rate', 175)
engine.setProperty('voice', 'zh')
engine.say(line)
engine.runAndWait()
最后再设置一个可以选择章节的接口传入主函数,运行程序即可听到有声小说的内容
完整代码
import requests
from lxml import etree
import pyttsx3
def main(a):
#小说的详情页
url = 'http://www.xbiquge.la/10/10489/'
#请求内容
response = requests.get(url).text
#转化成xpath语法可以提取的形式
html = etree.HTML(response)
#提取小说内容页的网址
data = html.xpath("//div[@class='box_con'][2]/div[@id='list']/dl/dd/a/@href")
#为了节省时间,先只提取一个章节的内容
sound = data[int(a)]
#构造小说内容页的网址
new_url = 'http://www.xbiquge.la' + str(sound)
#请求
response_1 = requests.get(new_url).content
html_1 = etree.HTML(response_1)
data_1 = html_1.xpath("//div[@id='content']/text()")
#用replace方法将提取到文本中的\xa0替换掉
noval = str(data_1).replace('\\xa0', '')
#替换掉\r
noval_0 = noval.replace("\\r',", '')
noval_1 = noval_0.replace('[', '')
#将爬取到的小说内容存储到文本文件中
with open('xiaoshuo.txt','w') as f:
f.write(noval_1)
def say(filename='xiaoshuo.txt'):
with open(filename, 'r') as f:
line = f.read()
engine = pyttsx3.init()
engine.setProperty('volume',1.0)
engine.setProperty('rate', 175)
engine.setProperty('voice', 'zh')
engine.say(line)
engine.runAndWait()
if __name__ == '__main__':
a = input('输入想要朗读的章节(数字):')
main(a)
say()
等你运行完这个程序,你就会发现机器人的声音实在是太难听了.如果想要做更加清晰的有声小说,可以调用百度人工智能的api接口来实现这个功能
Python模块---制作属于自己的有声小说的更多相关文章
- Python实战:下载鬼灵报告有声小说
在家无聊,想看看小说,不过看的眼睛痛,就想着下个有声小说来听听.但风上找到的都是要一集一集下,还得重命名,122集啊,点到什么时候. 写个批处理下载的脚本.记录下过程. 一.老套路了,找到下载URL. ...
- Python模块制作
在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字. 定义自己的模块 比如有这样一个文件test.py,在test.py中定义了函数add def add(a,b): ...
- Python模块---制作新冠疫情世界地图()
目录 pyecharts模块 简介 安装pyecharts 测试pyecharts模块 pyecharts实战:绘制新冠肺炎疫情地图 需求分析 请求数据 提取数据 处理数据 制作可视化地图 设置可视化 ...
- python生成有声小说模拟真人发音
生成有声小说原理 文字是1500字内的生成微软文档说说 用代码实现小说爬取正本 实现每章小说1450字 实现自动剪切后添加封面 实现自动上传 用python代码实现爬取小说,本案列以一本小说为实列代码 ...
- python模块大全
python模块大全2018年01月25日 13:38:55 mcj1314bb 阅读数:3049 pymatgen multidict yarl regex gvar tifffile jupyte ...
- Python模块常用的几种安装方式
Python模块安装方法 一.方法1: 单文件模块直接把文件拷贝到 $python_dir/Lib 二.方法2: 多文件模块,带setup.py 下载模块包,进行解压,进入模块文件夹,执行:pytho ...
- 大话python模块与包
前言 眼看着老掌门年纪越来越大,掌门之位的传承也成了门派中的一件大事.这天,老掌门把小掌门叫到跟前,语重心长地说道:孩子啊,以后你就要继任掌门之位了,我就传授此生所学的绝世功法与你,以后可要悉心学习, ...
- python 模块和包
一,模块 1,什么是模块? 常见的场景: 一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py 的后缀. 但其实 import 加载的模块分为四个通用类别: 1,使用pyt ...
- python模块学习第 0000 题
将你的 QQ 头像(或者微博头像)右上角加上红色的数字,类似于微信未读信息数量那种提示效果. 类似于图中效果: 好可爱>%<! 题目来源:https://github.com/Yixiao ...
随机推荐
- 如何使用Kibana
目录 前言 一.安装 二.加载自定义索引 三.如何搜索数据 四.如何切换中文 五.如何使用控制台 六.可视化图表 七.使用仪表盘 前言 Kibana 是为 Elasticsearch设计的开源分析和可 ...
- const 详解
简单分类: 常变量 const 类型 变量名 或者 类型 const 变量名 常引用 const 类型& 引用名 ...
- Spark入门(六)--Spark的combineByKey、sortBykey
spark的combineByKey combineByKey的特点 combineByKey的强大之处,在于提供了三个函数操作来操作一个函数.第一个函数,是对元数据处理,从而获得一个键值对.第二个函 ...
- 040.集群网络-CNI网络模型
一 CNM网络模型 1.1 网络模型 生产环境中,跨主机容器间的网络互通已经成为基本要求,更高的要求包括容器固定IP地址.一个容器多个IP地址.多个子网隔离.ACL控制策略.与SDN集成等.目前主流的 ...
- Journal of Proteome Research | An automated ‘cells-to-peptides’ sample preparation workflow for high-throughput, quantitative proteomic assays of microbes (解读人:陈浩)
文献名:An automated ‘cells-to-peptides’ sample preparation workflow for high-throughput, quantitative p ...
- 工作流--Activiti
一.工作流 1.工作流介绍 工作流(Workflow),就是通过计算机对业务流程自动化执行管理.它主要解决的是“使在多个参与者 之间按照某种预定义的规则自动进行传递文档.信息或任务的过程,从而实现某 ...
- PHP7内核(六):变量之zval
记得网上流传甚广的段子"PHP是世界上最好的语言",暂且不去讨论是否言过其实,但至少PHP确实有独特优势的,比如它的弱类型,即只需要$符号即可声明变量,使得PHP入手门槛极低,成为 ...
- SVN: Cleanup failed update报错 文件被锁定lock办法,cleanup 失效报错。
按照如下办法即可解决: 下载文件链接: https://pan.baidu.com/s/1Ump1BFihbX8izyAA4by5dA 提取码: ftsd 复制这段内容后打开百度网盘手机App,操作更 ...
- 使用FME裁剪矢量shapefile文件
- 潘粤明的《龙岭迷窟》到底怎么样?我用 Python 得出了一些结论!
对于天下霸唱的鬼吹灯,相信很多小伙伴都知道,它可谓是国内盗墓寻宝系列小说的巅峰之作,最近得知该系列小说的<龙岭迷窟>部分被制作成了网剧,已经于 4 月 1 日开播了,主要演员潘粤明.姜超. ...