Redis学习二:Redis高并发之主从模式
申明
本文章首发自本人公众号:壹枝花算不算浪漫,如若转载请标明来源!
感兴趣的小伙伴可关注个人公众号:壹枝花算不算浪漫
22.jpg
前言
前面已经学习了Redis的持久化方式,接下来开始学习Redis主从架构的原理,来看看Redis如何利用主从架构来保证高并发的。
Redis如何支持高并发
单机的redis一般QPS不会超过超过10万+,一般单机QPS都在几万左右,如果需要支撑高并发,我们可以将Redis做成主从架构来支持读写分离。
主从架构 -> 读写分离 -> 支撑10万+读QPS
主从架构的核心原理
当启动一个slave node的时候,它会发送一个PSYNC命令给master node
如果这是salve node重复你给你连接master node,那么master node仅仅会复制给slave部分缺失的数据;否则如果是slave node第一次连接master node,那么会触发一次full resynchronization
开始full resynchronization的时候,master会启动一个后台线程,开始生成一份RDB快照文件,同时还会将从客户端收到的所有写命令缓存在内存中。
RDB文件生成完毕之后,master将这个RDB发送给slave,salve会先写入本地磁盘,然后再从本地磁盘加载到内存中。
接着master会将内存中缓存的写命令发送给slave,slave也会同步这些数据。
主从复制断点续传
slave node如果跟master node有网络故障,断开了连接,会自动重连。
从redis 2.8之后,就支持主从复制的断点续传,如果主从复制过程中,网络连接断掉了,那么可以接着上次复制的地方,继续复制下去,而不是从头开始复制一份
master node会在内存中创建一个backlog,master和slave都会保存一个replica offset还有一个master id,offset就是保存在backlog中的。如果master和slave网络连接断掉了,slave会让master从上次的replica offseet开始继续复制
但是如果没有找到对应的offset,那么就会执行一次full resynchronization
无磁盘化复制
master在内存中直接创建rdb,然后发送给slave,不会在自己的本地落地磁盘了
// 默认不使用diskless同步方式,可以改成yes
repl-diskless-sync yes
// 无磁盘diskless方式在进行数据传递之前会有一个时间的延迟,以便slave端能够进行到待传送的目标队列中,这个时间默认是5秒
repl-diskless-sync-delay 5
过期key处理
slave不会过期key,只会等待master过期key。如果master过期了一个key,或者通过LRU淘汰了一个key,那么会模拟一条del命令发送个slave。
以上的执行流程如图:
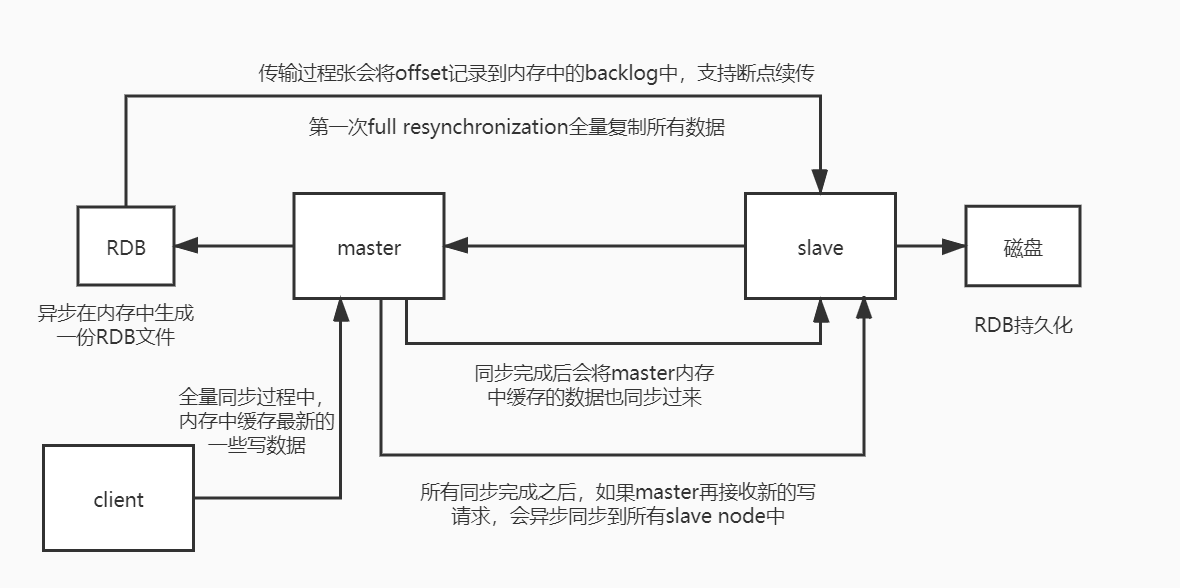 image.jpg
image.jpg
复制的完整流程
- slave node在redis.conf中的slaveof配置master的host信息,slave node启动,仅仅是保存了master node信息,此时复制流程并未开始
- slave node内部有个定时任务,每秒检查是否有新的master node需要连接和复制,如果发现,就跟master node建立socket网络连接
- slave node发送ping的命令给master node
- 口令认证,如果master设置了requiresspass,那么slave node必须发送masterauth的口令过去认证
- master node第一次执行全量复制,将所有数据发送给slave node
- master node后续持续将写命令,异步复制给slave node
具体流程如下:(以下内容参考自:
https://blog.csdn.net/houjixin/article/details/27680183)
全量复制
全备份过程中,在slave启动时,会向其master发送一条SYNC消息,master收到slave的这条消息之后,将可能启动后台进程进行备份,备份完成之后就将备份的数据发送给slave,初始时的全同步机制是这样的:
- slave启动后向master发送同步指令SYNC,master接收到SYNC指令之后将调用该命令的处理函数syncCommand()进行同步处理;
- 在函数syncCommand中,将调用函数rdbSaveBackground启动一个备份进程用于数据同步,如果已经有一个备份进程在运行了,就不会再重新启动了。
- 备份进程将执行函数rdbSave()完成将redis的全部数据保存为rdb文件。
- 在redis的时间事件函数serverCron(redis的时间处理函数是指它会定时被redis进行操作的函数)中,将对备份后的数据进行处理,在serverCron函数中将会检查备份进程是否已经执行完毕,如果备份进程已经完成备份,则调用函数backgroundSaveDoneHandler完成后续处理。
- 在函数backgroundSaveDoneHandler中,首先更新master的各种状态,例如,备份成功还是失败,备份的时间等等。然后调用函数updateSlavesWaitingBgsave,将备份的rdb数据发送给等待的slave。
- 在函数updateSlavesWaitingBgsave中,将遍历所有的等待此次备份的slave,将备份的rdb文件发送给每一个slave。另外,这里并不是立即就把数据发送过去,而是将为每个等待的slave注册写事件,并注册写事件的响应函数sendBulkToSlave,即当slave对应的socket能够发送数据时就调用函数sendBulkToSlave(),实际发送rdb文件的操作都在函数sendBulkToSlave中完成。
- sendBulkToSlave函数将把备份的rdb文件发送给slave。
上述函数调用过程如下图1所示:
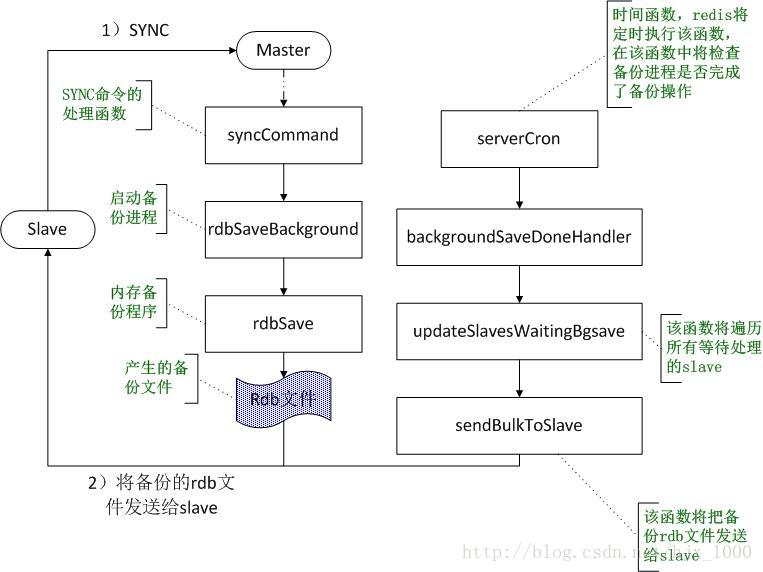 image.png
image.png
数据修改操作的同步
Redis的正常部署中一般都是一个master用于写操作,若干个slave用于读操作,另外定期的数据备份操作也是单独选址一个slave完成,这样可以最大程度发挥出redis的性能。在部署完成,各master\slave程序启动之后,首先进行第一阶段初始化时的全同步操作,全同步操作完成之后,后续所有写操作都是在master上进行,所有读操作都是在slave上进行,因此用户的写操作需要及时扩散到所有的slave以便保持数据最大程度上的同步。Redis的master-slave进程在正常运行期间更新操作(包括写、删除、更改操作)的同步方式如下:
master接收到一条用户的操作后,将调用函数call函数来执行具体的操作函数(此过程可参考另一文档《redis命令执行流程分析》),在该函数中首先通过proc执行操作函数,然后将判断操作是否需要扩散到各slave,如果需要则调用函数propagate()来完成此操作。
propagate()函数完成将一个操作记录到aof文件中或者扩散到其他slave中;在该函数中通过调用feedAppendOnlyFile()将操作记录到aof中,通过调用replicationFeedSlaves()将操作扩散到各slave中。
函数feedAppendOnlyFile()中主要保存操作到aof文件,在该函数中首先将操作转换成redis内部的协议格式,并以字符串的形式存储,然后将字符串存储的操作追加到aof文件后。
函数replicationFeedSlaves()主要将操作扩散到每一个slave中;在该函数中将遍历自己下面挂的每一个slave,以此对每个slave进行如下两步的处理:将slave的数据库切换到本操作所对应的数据库(如果slave的数据库id与当前操作的数据id不一致时才进行此操作);将命令和参数按照redis的协议格式写入到slave的回复缓存中。写入切换数据库的命令时将调用addReply,写入命令和参数时将调用addReplyMultiBulkLen和addReplyBulk,函数addReplyMultiBulkLen和addReplyBulk最终也将调用函数addReply。
在函数addReply中将调用prepareClientToWrite()设置slave的socket写入事件处理函数sendReplyToClient(通过函数aeCreateFileEvent进行设置),这样一旦slave对应的socket发送缓存中有空间写入数据,即调用sendReplyToClient进行处理。
函数sendReplyToClient()的主要功能是将slave中要发送的数据通过socket发出去。
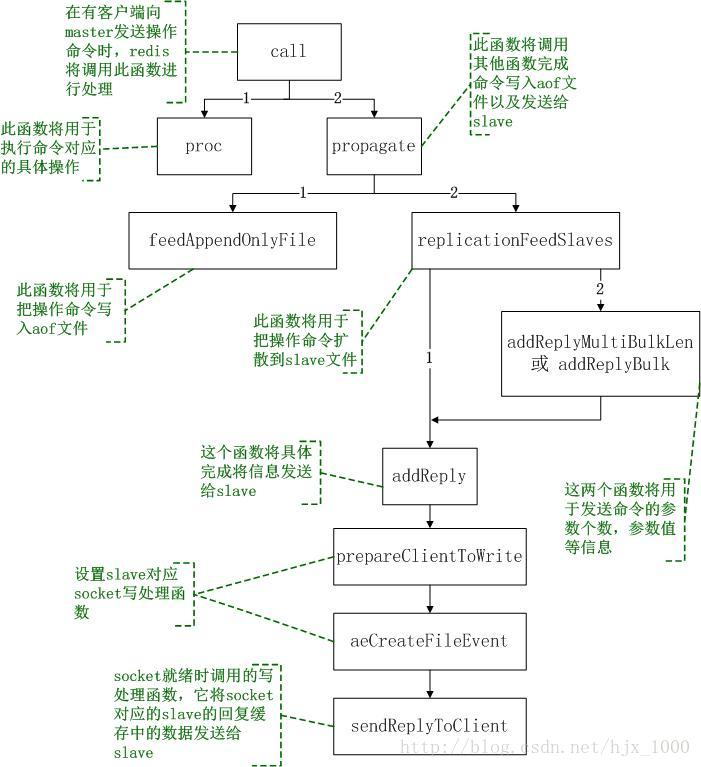 image.png
image.png
数据同步相关核心机制
第一次slave连接master的时候,执行的是全量复制,这个过程中有些细节的机制
master和slave都会维护一个offset
master会在自身不断累加offset,slave也会在自身不断累加offset。slave每秒都会上报自己的offset给master,同时master也会保存每个slave的offset。
offset并不是只用在全量复制中,主要是master和slave都要知道各自的数据offset,才能知道互相之间数据不一致的情况
backlog机制
master node有一个backlog,默认大小是1M,master node给slave node复制数据时,也会将数据backlog中同步写一份,backlog主要是用来做全量复制中断时候的增量复制
master run id
在redis中执行info server命令,可以看到master run id,如果根据host+ip定位master node,是不准确的,如果master node重启或者数据出现了变化,那么slave node应该根据不同的run id区分,run id不同就做全量复制。
如果需要不更改run id重启redis,可以使用redis-cli debug reload命令psync命令
从节点使用psync从master node进行复制,psync runid offset,master node会根据自身的情况返回响应信息,可能是FULLRESYNC runid offset触发全量复制,可能是CONTINUE触发增量复制
heatbeat机制
主从节点互相都会发送heartbeat信息,master默认每隔10秒发送一次heartbeat,slave node每隔1秒发送一个heartbeat
Redis学习二:Redis高并发之主从模式的更多相关文章
- Redis——学习之路四(初识主从配置)
首先我们配置一台master服务器,两台slave服务器.master服务器配置就是默认配置 端口为6379,添加就一个密码CeshiPassword,然后启动master服务器. 两台slave服务 ...
- Redis系列(二):Redis的数据类型及命令操作
原文链接(转载请注明出处):Redis系列(二):Redis的数据类型及命令操作 Redis 中常用命令 Redis 官方的文档是英文版的,当然网上也有大量的中文翻译版,例如:Redis 命令参考.这 ...
- Nginx知多少系列之(十四)Linux下.NET Core项目Nginx+Keepalived高可用(主从模式)
目录 1.前言 2.安装 3.配置文件详解 4.工作原理 5.Linux下托管.NET Core项目 6.Linux下.NET Core项目负载均衡 7.负载均衡策略 8.加权轮询(round rob ...
- redis深入学习(二)-----redis配置文件、持久化
redis配置文件 地址 units单位 a 配置大小单位,开头定义了一些基本的度量单位,只支持bytes,不支持bitb 对大小写不敏感 GENERAL通用 1.daemonize 2.pidf ...
- 老司机带你玩转面试(3):Redis 高可用之主从模式
前文回顾 建议前面文章没看过的同学先看下前面的文章: 「老司机带你玩转面试(1):缓存中间件 Redis 基础知识以及数据持久化」 「老司机带你玩转面试(2):Redis 过期策略以及缓存雪崩.击穿. ...
- Redis系列3:高可用之主从架构
Redis系列1:深刻理解高性能Redis的本质 Redis系列2:数据持久化提高可用性 1 主从复制介绍 上一篇<Redis系列2:数据持久化提高可用性>中,我们介绍了Redis中的数据 ...
- Redis学习笔记~Redis主从服务器,读写分离
回到目录 Redis这个Nosql的存储系统一般会被部署到linux系统中,我们可以把它当成是一个数据服务器,对于并发理大时,我们会使用多台服务器充当Redis服务器,这时,各个Redis之间也是分布 ...
- Redis学习二:Redis入门介绍
一.入门概述 1.是什么 Redis:REmote DIctionary Server(远程字典服务器) 是完全开源免费的,用C语言编写的,遵守BSD协议,是一个高性能的(key/value)分布式内 ...
- C#中使用Redis学习二 在.NET4.5中使用redis hash操作
上一篇>> 摘要 上一篇讲述了安装redis客户端和服务器端,也大体地介绍了一下redis.本篇着重讲解.NET4.0 和 .NET4.5中如何使用redis和C# redis操作哈希表. ...
随机推荐
- macOS开发:调整NSImage尺寸大小
原文链接 extension NSImage { func resize(_ to: CGSize, isPixels: Bool = false) -> NSImage { var toSiz ...
- Vue + element从零打造一个H5页面可视化编辑器——pl-drag-template
pl-drag-template Github地址:https://github.com/livelyPeng/pl-drag-template 前言 想必你一定使用过易企秀或百度H5等微场景生成工具 ...
- 我们是怎么实现Grpc CodeFirst
前言: Grpc默认是ProtoFirst的,即先写 proto文件,再生成代码,需要人工维护proto,生成的代码也不友好,所以出现了Grpc CodeFirst,下面来说说我们是怎么实现Grpc ...
- 深度学习、物联网专家Sunil Kumar Vuppala博士独家专访
介绍 有多种方法可以学习数据科学,机器学习和深度学习概念.您可以观看视频,阅读文章,参加课程,参加会议等.但是有一件事是无法替代的----经验. 我个人从与数据科学专家和行业领袖的交流中学到了很多.他 ...
- Centos7部署k8s[v1.16]高可用[keepalived]集群
实验目的 一般情况下,k8s集群中只有一台master和多台node,当master故障时,引发的事故后果可想而知. 故本文目的在于体现集群的高可用,即当集群中的一台master宕机后,k8s集群通过 ...
- coding++:高并发解决方案限流技术-使用RateLimiter实现令牌桶限流-Demo
RateLimiter是guava提供的基于令牌桶算法的实现类,可以非常简单的完成限流特技,并且根据系统的实际情况来调整生成token的速率. 通常可应用于抢购限流防止冲垮系统:限制某接口.服务单位时 ...
- 第二次实验报告:使用 Packet Tracer 分析应用层协议
个人信息: 姓名:倪晓东 班级:计算1811 学号:201821121020 1 实验目的 熟练使用Packet Tracer工具.分析抓到的应用层协议数据包,深入理解应用层协议,包括语法.语义.时序 ...
- java如何自定义一个线程池
java线程池的一些简单功能,后续会更新,代码不多,很好理解 package com.rbac.thread; import java.util.ArrayList; import java.util ...
- Java 对象容器
一.ArrayList 容器 1.记事本 package booknote; import java.util.ArrayList; public class NoteBook { private A ...
- Mac LaTex中文环境搭建
为了在博客上写公式,折腾了一晚上Mac上的LaTex的环境搭建,本文对步骤进行记录. 系统:Mac OSX 10.10.5 软件准备 1) MacTex 2015 Distribution (Tex的 ...