LDA模型笔记
“LDA(Latent Dirichlet Allocation)模型,模型主要解决文档处理领域的问题,比如文章主题分类、文章检测、相似度分析、文本分段和文档检索等问题。
LDA主题模型是一个三层贝叶斯概率模型,包含词、主题、文档三层结构,文档到主题服从Dirichlet分布,主题到词服从多项式分布。它采用了词袋(Bag of Words)的方法,
将每一篇文章视为一个词频向量,每一篇文档代表了一些主题所构成的概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
利用LDA模型对用户参与的话题文本进行分析,得到用户在给定虚拟主题下对每个主题感兴趣的概率分布,从而挖掘出用户的兴趣偏好。“
摘自《基于社交关系和影响力的在线社交网络用户兴趣偏好获取方法研究》
对LDA的理解,可参考:主题模型-LDA浅析
我对LDA的理解主要是抓住公式:

和图
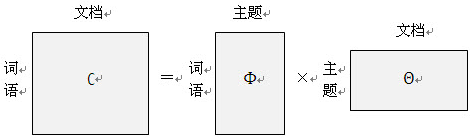
其中“给定一系列文档,通过对文档进行分词,计算各个文档中每个单词的词频就可以得到左边这边”文档-词语”矩阵。主题模型就是通过左边这个矩阵进行训练,学习出右边两个矩阵。“
左边的矩阵就是每一个词语在每篇文章中出现的频率的矩阵,“学习出右边两个矩阵“,如何学习?其实就是矩阵分解,把左边的矩阵分解为右边的两个矩阵,可以采用SVD等矩阵分解方法,得到右边的两个矩阵之后,主要是如何利用这两个矩阵?其中“文档-主题“矩阵,单看其中的一列,就是某个文档的内容讲的是各个主题的概率,例如,文档1属于主题1的概率是0.1,属于主题2的概率是0.5,属于主题3的概率是0.8,...这其中概率最大的那个主题topic X,我们就可以认为,这个文档就属于主题topic X。由此,因为我们可以通过此方法判断文档的主题类型,所以我们就能判断两个不同的文档是否属于相同的主题,也就是可以达到文档归类的目的。
至于图中,“主题-词语“矩阵、"文档-主题"矩阵中的主题到底是啥,是不可知的,这其实也是可以理解的,因为任何一个词语都有可能出现在关于任何一个主题的文章中。
其他:
LDA模型笔记的更多相关文章
- 机器学习-LDA主题模型笔记
LDA常见的应用方向: 信息提取和搜索(语义分析):文档分类/聚类.文章摘要.社区挖掘:基于内容的图像聚类.目标识别(以及其他计算机视觉应用):生物信息数据的应用; 对于朴素贝叶斯模型来说,可以胜任许 ...
- lda模型的python实现
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,最近看了点资料,准备使用python实现一下.至于数学模型相关知识,某度一大堆,这里也给出之前参考过的一个挺详细 ...
- LDA模型了解及相关知识
什么是LDA? LDA是基于贝叶斯模型的,涉及到贝叶斯模型离不开“先验分布”,“数据(似然)”和"后验分布"三块.贝叶斯相关知识:先验分布 + 数据(似然)= 后验分布. 贝叶斯模 ...
- 转:关于Latent Dirichlet Allocation及Hierarchical LDA模型的必读文章和相关代码
关于Latent Dirichlet Allocation及Hierarchical LDA模型的必读文章和相关代码 转: http://andyliuxs.iteye.com/blog/105174 ...
- 文本主题抽取:用gensim训练LDA模型
得知李航老师的<统计学习方法>出了第二版,我第一时间就买了.看了这本书的目录,非常高兴,好家伙,居然把主题模型都写了,还有pagerank.一路看到了马尔科夫蒙特卡罗方法和LDA主题模型这 ...
- 大佬整理出来的干货:LDA模型实现—Python文本挖掘
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取htt ...
- 计算LDA模型困惑度
http://www.52nlp.cn/lda-math-lda-%E6%96%87%E6%9C%AC%E5%BB%BA%E6%A8%A1 LDA主题模型评估方法--Perplexity http:/ ...
- 《C#并行编程高级教程》第9章 异步编程模型 笔记
这个章节我个人感觉意义不大,使用现有的APM(异步编程模型)和EAP(基于时间的异步模型)就很够用了,针对WPF和WinForm其实还有一些专门用于UI更新的类. 但是出于完整性,还是将一下怎么使用. ...
- LDA模型数据的可视化
""" 执行lda2vec.ipnb中的代码 模型LDA 功能:训练好后模型数据的可视化 """ from lda2vec import p ...
随机推荐
- VMware15.5.0安装MacOS10.15.0系统 安装步骤(下)
VMware15.5.0安装MacOS10.15.0系统安装步骤(下)超详细! 接上文第5条如果没看过上篇的话传送门:https://www.cnblogs.com/Top-chen/p/128024 ...
- js 跳出循环
js 循环主要有 for while 主要有三种方式 :break continue return break是跳出当前整个循环语句,循环终止会继续执行该循环之后的代码 而continue是跳过当前循 ...
- POJ3734(矩阵快速幂)
\(假设现在到第i个积木\) \(红绿恰都是偶数a种方案,恰都是奇数为b种方案,一奇一偶为c种方案\) \(由此考虑i+1个积木的情况\) Ⅰ.一奇一偶的方案 \(如果第i层恰是奇数的情况,那么本次只 ...
- spring中bean的常用属性
一.scop scope用来配置bean对象是否是单例模式.单例模式是java的二十三种设置模式之一,指在这个项目运行过程中一 个类的对象只会实例化一次.一般,工厂类的对象都是单例模式.非单例模式叫多 ...
- 基于C语言的Q格式使用详解
用过DSP的应该都知道Q格式吧: 目录 1 前言 2 Q数据的表示 2.1 范围和精度 2.2 推导 3 Q数据的运算 3.1 0x7FFF 3.2 0x8000 3.3 加法 3.4 减法 3.5 ...
- Javascript模块化编程-require.js
转自:https://www.cnblogs.com/digdeep/p/4607131.html Javascript模块化编程(一):模块的写法 随着网站逐渐变成"互联网应用程序&quo ...
- .Net Core3.0 WebApi 项目框架搭建 二:API 文档神器 Swagger
.Net Core3.0 WebApi 项目框架搭建:目录 为什么使用Swagger 随着互联网技术的发展,现在的网站架构基本都由原来的后端渲染,变成了:前端渲染.后端分离的形态,而且前端技术和后端技 ...
- 我的.emacs配置
我不是大神,使用vim和emacs只是兴趣,打发空闲时间. 上代码: ;; Added by Package.el. This must come before configurations of ; ...
- 初识JAVA(学习记录)
Java 1.1Java简介 Java是一种跨平台的,面向对象的程序设计语言.无论是电脑还是手机,到处都运行着JAVA开发的应用程序:JAVA程序可以在任何计算机.操作系统以及支持JAVA的硬件设备上 ...
- 【雕爷学编程】Arduino动手做(46)---电阻应变片传感器
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的.鉴于本人手头积累了一些传感器和模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的,这里 ...