CTR学习笔记&代码实现4-深度ctr模型 NFM/AFM
这一节我们总结FM另外两个远亲NFM,AFM。NFM和AFM都是针对Wide&Deep 中Deep部分的改造。上一章PNN用到了向量内积外积来提取特征交互信息,总共向量乘积就这几种,这不NFM就带着element-wise(hadamard) product来了。AFM则是引入了注意力机制把NFM的等权求和变成了加权求和。
以下代码针对Dense输入感觉更容易理解模型结构,针对spare输入的代码和完整代码
https://github.com/DSXiangLi/CTR
NFM
NFM的创新点是在wide&Deep的Deep部分,在Embedding层和全联接层之间加入了BI-Pooling层,也就是Embedding两两做element-wise乘积得到 \(N*(N-1)/2\)个 \(1*K\)的矩阵然后做sum_pooling得到最终\(1*k\)的矩阵。
Deep部分的模型结构如下

和其他模型的联系
NFM不接全连接层,直接weight=1输出就是FM,所以NFM可以在FM上学到更高阶的特征交互。
有看到一种说法是DeepFM是FM和Deep并联,NFM是把FM和Deep串联,也是可以这么理解,但感觉本质是在学习不同的信息,把FM放在wide侧是帮助学习二阶‘记忆特征’,把FM放在Deep侧是帮助学习高阶‘泛化特征’。
NFM和PNN都是用向量相乘的方式来帮助全联接层提炼特征交互信息。虽然一个是element-wise product一个是inner product,但区别其实只是做sum_pooling时axis的差异。 IPNN是在k的axis上求和得到\(N^2\)个scaler拼接成输入, 而NFM是在\(N^2\)的axis上求和得到\(1*K\)的输入。
下面这个例子可以比较直观的比较一下FM,NFM,IPNN对Embedding的处理(为了简单理解给了Embedding简单数值)
NFM几个想吐槽的点
- 和FNN,PNN一样对低阶特征的提炼比较有限
- 这个sum_pooling同样会存在信息损失,不同的特征交互对Target的影响不同,等权加和一定不是最好的方法,但也算是为特征交互提供了一种新方法
代码实现
@tf_estimator_model
def model_fn_dense(features, labels, mode, params):
dense_feature, sparse_feature = build_features()
dense = tf.feature_column.input_layer(features, dense_feature)
sparse = tf.feature_column.input_layer(features, sparse_feature)
field_size = len( dense_feature )
embedding_size = dense_feature[0].variable_shape.as_list()[-1]
embedding_matrix = tf.reshape( dense, [-1, field_size, embedding_size] ) # batch * field_size *emb_size
with tf.variable_scope('Linear_output'):
linear_output = tf.layers.dense( sparse, units=1 )
add_layer_summary( 'linear_output', linear_output )
with tf.variable_scope('BI_Pooling'):
sum_square = tf.pow(tf.reduce_sum(embedding_matrix, axis=1), 2)
square_sum = tf.reduce_sum(tf.pow(embedding_matrix, 2), axis=1)
dense = tf.subtract(sum_square, square_sum)
add_layer_summary( dense.name, dense )
dense = stack_dense_layer(dense, params['hidden_units'],
dropout_rate = params['dropout_rate'], batch_norm = params['batch_norm'],
mode = mode, add_summary = True)
with tf.variable_scope('output'):
y = linear_output + dense
add_layer_summary( 'output', y )
return y
AFM
AFM和NFM同样使用element-wise product来提取特征交互信息,和NFM直接等权重做pooling不同的是,AFM增加了一层Attention Layer来学习pooling的权重。
Deep部分的模型结构如下
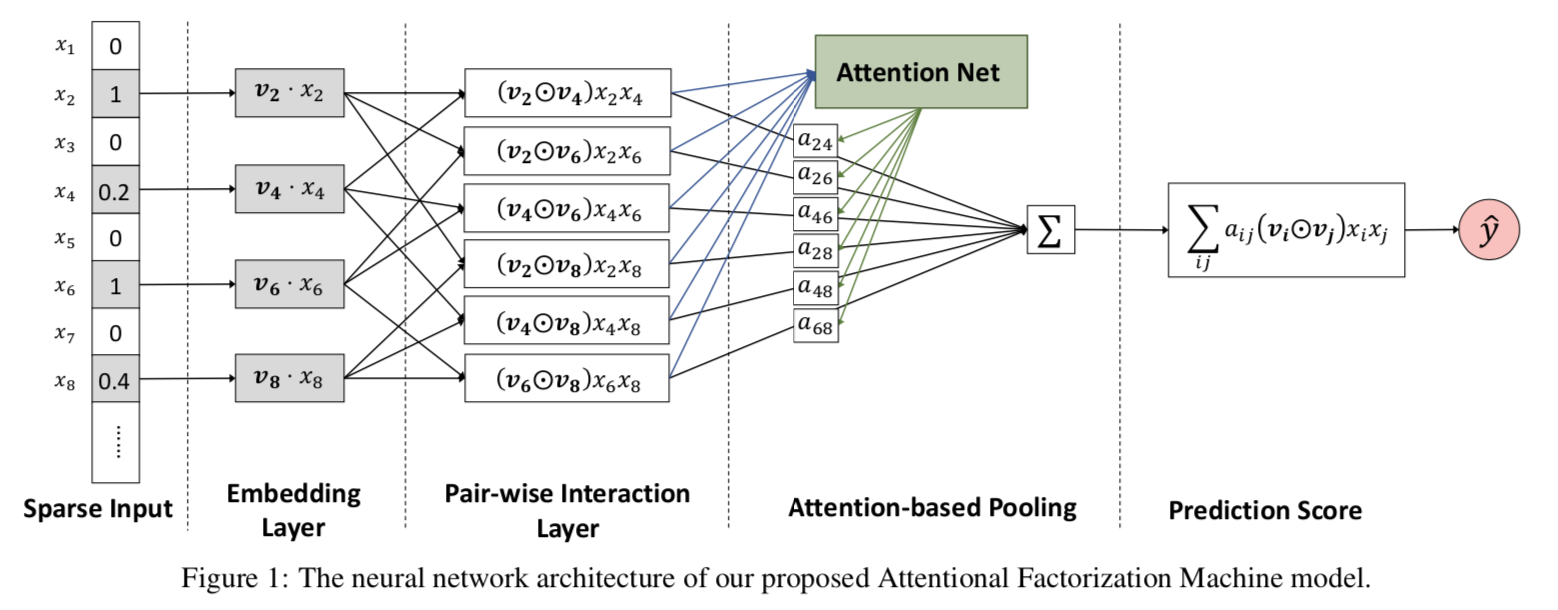
注意力部分是一个简单的全联接层,输出的是\(N(N-1)/2\)的矩阵,作为sum_pooling的权重向量,对element-wise特征交互向量进行加权求和。加权求和的向量直接连接output,不再经过全联接层。如果权重为1,那AFM和不带全联接层的NFM是一样滴。
AFM几个想吐槽的点
- 不带全联接层会导致高级特征表达有限,不过这个不重要啦,AFM更多还是为特征交互提供了Attention的新思路
代码实现
@tf_estimator_model
def model_fn_dense(features, labels, mode, params):
dense_feature, sparse_feature = build_features()
dense = tf.feature_column.input_layer(features, dense_feature) # lz linear concat of embedding
sparse = tf.feature_column.input_layer(features, sparse_feature)
field_size = len( dense_feature )
embedding_size = dense_feature[0].variable_shape.as_list()[-1]
embedding_matrix = tf.reshape( dense, [-1, field_size, embedding_size] ) # batch * field_size *emb_size
with tf.variable_scope('Linear_part'):
linear_output = tf.layers.dense(sparse, units=1)
add_layer_summary( 'linear_output', linear_output )
with tf.variable_scope('Elementwise_Interaction'):
elementwise_list = []
for i in range(field_size):
for j in range(i+1, field_size):
vi = tf.gather(embedding_matrix, indices=i, axis=1, batch_dims=0,name = 'vi') # batch * emb_size
vj = tf.gather(embedding_matrix, indices=j, axis=1, batch_dims=0,name = 'vj')
elementwise_list.append(tf.multiply(vi,vj)) # batch * emb_size
elementwise_matrix = tf.stack(elementwise_list) # (N*(N-1)/2) * batch * emb_size
elementwise_matrix = tf.transpose(elementwise_matrix, [1,0,2]) # batch * (N*(N-1)/2) * emb_size
with tf.variable_scope('Attention_Net'):
# 2 fully connected layer
dense = tf.layers.dense(elementwise_matrix, units = params['attention_factor'], activation = 'relu') # batch * (N*(N-1)/2) * t
add_layer_summary( dense.name, dense )
attention_weight = tf.layers.dense(dense, units=1, activation = 'softmax') # batch *(N*(N-1)/2) * 1
add_layer_summary( attention_weight.name, attention_weight)
with tf.variable_scope('Attention_pooling'):
interaction_output = tf.reduce_sum(tf.multiply(elementwise_matrix, attention_weight), axis=1) # batch * emb_size
interaction_output = tf.layers.dense(interaction_output, units=1) # batch * 1
with tf.variable_scope('output'):
y = interaction_output + linear_output
add_layer_summary( 'output', y )
return y
CTR学习笔记&代码实现系列
https://github.com/DSXiangLi/CTR
CTR学习笔记&代码实现1-深度学习的前奏LR->FFM
CTR学习笔记&代码实现2-深度ctr模型 MLP->Wide&Deep
CTR学习笔记&代码实现3-深度ctr模型 FNN->PNN->DeepFM
资料
- Jun Xiao, Hao Ye ,2017, Attentional Factorization Machines - Learning the Weight of Feature Interactions via Attention Networks
- Xiangnan He, Tat-Seng Chua,2017, Neural Factorization Machines for Sparse Predictive Analytics
- https://zhuanlan.zhihu.com/p/86181485
CTR学习笔记&代码实现4-深度ctr模型 NFM/AFM的更多相关文章
- CTR学习笔记&代码实现3-深度ctr模型 FNN->PNN->DeepFM
这一节我们总结FM三兄弟FNN/PNN/DeepFM,由远及近,从最初把FM得到的隐向量和权重作为神经网络输入的FNN,到把向量内/外积从预训练直接迁移到神经网络中的PNN,再到参考wide& ...
- CTR学习笔记&代码实现5-深度ctr模型 DeepCrossing -> DCN
之前总结了PNN,NFM,AFM这类两两向量乘积的方式,这一节我们换新的思路来看特征交互.DeepCrossing是最早在CTR模型中使用ResNet的前辈,DCN在ResNet上进一步创新,为高阶特 ...
- CTR学习笔记&代码实现6-深度ctr模型 后浪 xDeepFM/FiBiNET
xDeepFM用改良的DCN替代了DeepFM的FM部分来学习组合特征信息,而FiBiNET则是应用SENET加入了特征权重比NFM,AFM更进了一步.在看两个model前建议对DeepFM, Dee ...
- CTR学习笔记&代码实现2-深度ctr模型 MLP->Wide&Deep
背景 这一篇我们从基础的深度ctr模型谈起.我很喜欢Wide&Deep的框架感觉之后很多改进都可以纳入这个框架中.Wide负责样本中出现的频繁项挖掘,Deep负责样本中未出现的特征泛化.而后续 ...
- CTR学习笔记&代码实现1-深度学习的前奏LR->FFM
CTR学习笔记系列的第一篇,总结在深度模型称王之前经典LR,FM, FFM模型,这些经典模型后续也作为组件用于各个深度模型.模型分别用自定义Keras Layer和estimator来实现,哈哈一个是 ...
- GIS案例学习笔记-明暗等高线提取地理模型构建
GIS案例学习笔记-明暗等高线提取地理模型构建 联系方式:谢老师,135-4855-4328,xiexiaokui#qq.com 目的:针对数字高程模型,通过地形分析,建立明暗等高线提取模型,生成具有 ...
- 【PyTorch深度学习】学习笔记之PyTorch与深度学习
第1章 PyTorch与深度学习 深度学习的应用 接近人类水平的图像分类 接近人类水平的语音识别 机器翻译 自动驾驶汽车 Siri.Google语音和Alexa在最近几年更加准确 日本农民的黄瓜智能分 ...
- [原创]java WEB学习笔记44:Filter 简介,模型,创建,工作原理,相关API,过滤器的部署及映射的方式,Demo
本博客为原创:综合 尚硅谷(http://www.atguigu.com)的系统教程(深表感谢)和 网络上的现有资源(博客,文档,图书等),资源的出处我会标明 本博客的目的:①总结自己的学习过程,相当 ...
- cips2016+学习笔记︱简述常见的语言表示模型(词嵌入、句表示、篇章表示)
在cips2016出来之前,笔者也总结过种类繁多,类似词向量的内容,自然语言处理︱简述四大类文本分析中的"词向量"(文本词特征提取)事实证明,笔者当时所写的基本跟CIPS2016一 ...
随机推荐
- 1272: 【基础】求P进制数的最大公因子与最小公倍数
1272: [基础]求P进制数的最大公因子与最小公倍数 时间限制: 1 Sec 内存限制: 16 MB 提交: 684 解决: 415 [提交] [状态] [讨论版] [命题人:外部导入] 题目描述 ...
- Mac 开发工具信息的备份
相信大部分程序员都对开发环境的工具都有一些特殊的执念(???),如果在自己不习惯的环境中工作完全无法开展,怎么这个工具没有那个字体难受,我本人就是,换了新的 Mac 电脑后如何快速恢复到之前的开发工具 ...
- Linux操作系统及调用接口
Linux操作系统包含以下各子系统: 系统调用子系统:操作系统的功能调用同一入口: 进程管理子系统:对执行程序进行生命周期和资源管理: 内存管理子系统:对系统的内存进行管理.分配.回收.隔离: 文件子 ...
- LoadRunner从入门到实战学习路线(持续更新中...)
写在前面 我是一个测试工程师,从土木工程行业转行到互联网行业,目前是工作的第三年.平时主要做功能测试,性能测试接触比较少,虽然以前培训的时候学习过一些性能相关的知识,但都是入门初级的知识 ...
- IO 模型知多少
1. 引言 同步异步I/O,阻塞非阻塞I/O是程序员老生常谈的话题了,也是自己一直以来懵懵懂懂的一个话题.比如:何为同步异步?何为阻塞与非阻塞?二者的区别在哪里?阻塞在何处?为什么会有多种IO模型,分 ...
- 安卓开发学习日记 DAY3——TextView,EditView,ImageView
今天学习了一些控件的使用方法,包括TextView,EditView,ImageView 1.TextView,输出一个文本呗 主要属性有 android:id 标志 android:layout_w ...
- 手动搭建I/O网络通信框架4:AIO编程模型,聊天室终极改造
第一章:手动搭建I/O网络通信框架1:Socket和ServerSocket入门实战,实现单聊 第二章:手动搭建I/O网络通信框架2:BIO编程模型实现群聊 第三章:手动搭建I/O网络通信框架3:NI ...
- Byte字节
字节(Byte )是计算机信息技术用于计量存储容量的一种计量单位,作为一个单位来处理的一个二进制数字串,是构成信息的一个小单位.最常用的字节是八位的字节,即它包含八位的二进制数. 中文名 字节 外文名 ...
- iOS 头条一面 面试题
1.如何高效的切圆角? 切圆角共有以下三种方案: cornerRadius + masksToBounds:适用于单个视图或视图不在列表上且量级较小的情况,会导致离屏渲染. CAShapeLayer+ ...
- Android Them+SharedPreferences 修改程序所有view字体颜色、大小和页面背景
有这么一个需求,可以对页面的样式进行选择,然后根据选择改变程序所有字体颜色和页面背景.同时下一次启动程序,当前设置依然有效. 根据需求,我们需要一种快速,方便,有效的方式来实现需求,然后可以通过And ...