WEB开发中的字符集和编码
h2:first-child, body>h1:first-child, body>h1:first-child+h2, body>h3:first-child, body>h4:first-child, body>h5:first-child, body>h6:first-child {
margin-top: 0;
padding-top: 0;
}
a:first-child h1, a:first-child h2, a:first-child h3, a:first-child h4, a:first-child h5, a:first-child h6 {
margin-top: 0;
padding-top: 0;
}
h1+p, h2+p, h3+p, h4+p, h5+p, h6+p {
margin-top: 10px;
}
/* LINKS
=============================================================================*/
a {
color: #4183C4;
text-decoration: none;
}
a:hover {
text-decoration: underline;
}
/* LISTS
=============================================================================*/
ul, ol {
padding-left: 30px;
}
ul li > :first-child,
ol li > :first-child,
ul li ul:first-of-type,
ol li ol:first-of-type,
ul li ol:first-of-type,
ol li ul:first-of-type {
margin-top: 0px;
}
ul ul, ul ol, ol ol, ol ul {
margin-bottom: 0;
}
dl {
padding: 0;
}
dl dt {
font-size: 14px;
font-weight: bold;
font-style: italic;
padding: 0;
margin: 15px 0 5px;
}
dl dt:first-child {
padding: 0;
}
dl dt>:first-child {
margin-top: 0px;
}
dl dt>:last-child {
margin-bottom: 0px;
}
dl dd {
margin: 0 0 15px;
padding: 0 15px;
}
dl dd>:first-child {
margin-top: 0px;
}
dl dd>:last-child {
margin-bottom: 0px;
}
/* CODE
=============================================================================*/
pre, code, tt {
font-size: 12px;
font-family: Consolas, "Liberation Mono", Courier, monospace;
}
code, tt {
margin: 0 0px;
padding: 0px 0px;
white-space: nowrap;
border: 1px solid #eaeaea;
background-color: #f8f8f8;
border-radius: 3px;
}
pre>code {
margin: 0;
padding: 0;
white-space: pre;
border: none;
background: transparent;
}
pre {
background-color: #f8f8f8;
border: 1px solid #ccc;
font-size: 13px;
line-height: 19px;
overflow: auto;
padding: 6px 10px;
border-radius: 3px;
}
pre code, pre tt {
background-color: transparent;
border: none;
}
kbd {
-moz-border-bottom-colors: none;
-moz-border-left-colors: none;
-moz-border-right-colors: none;
-moz-border-top-colors: none;
background-color: #DDDDDD;
background-image: linear-gradient(#F1F1F1, #DDDDDD);
background-repeat: repeat-x;
border-color: #DDDDDD #CCCCCC #CCCCCC #DDDDDD;
border-image: none;
border-radius: 2px 2px 2px 2px;
border-style: solid;
border-width: 1px;
font-family: "Helvetica Neue",Helvetica,Arial,sans-serif;
line-height: 10px;
padding: 1px 4px;
}
/* QUOTES
=============================================================================*/
blockquote {
border-left: 4px solid #DDD;
padding: 0 15px;
color: #777;
}
blockquote>:first-child {
margin-top: 0px;
}
blockquote>:last-child {
margin-bottom: 0px;
}
/* HORIZONTAL RULES
=============================================================================*/
hr {
clear: both;
margin: 15px 0;
height: 0px;
overflow: hidden;
border: none;
background: transparent;
border-bottom: 4px solid #ddd;
padding: 0;
}
/* TABLES
=============================================================================*/
table th {
font-weight: bold;
}
table th, table td {
border: 1px solid #ccc;
padding: 6px 13px;
}
table tr {
border-top: 1px solid #ccc;
background-color: #fff;
}
table tr:nth-child(2n) {
background-color: #f8f8f8;
}
/* IMAGES
=============================================================================*/
img {
max-width: 100%
}
-->
引言
我相信很多人在初接触编程时,都被字符集狠狠地虐过,特别是数据库的中文乱码问题,那么乱码是怎么产生的呢? 我们都知道计算机是以二进制存储和运行的,那么它是怎么把二进制数据转换为各种文字的呢? 还有我们常用的各种字符集,常用的编码转换,都是怎么进行的呢?
本博文所写的内容不是技术干货,只是对我们常用的字符集和编码的一个小总结,小科普。我相信读完本文,您应该对 字符集和常见编码方式 有个差不多的认识了。
ASCII码
ASCII码(American Standard Code for Information Interchange,美国信息交换标准代码)应该是我们最初接触过的编码方式了,编程最常用的字符都被它包括在内。它使用7bit来表示 128(2e7)个字符,最高位固定为 0,共占用一个字节。其中:
0~31 及 127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:TAB(制表符)、CR(回车)、DEL(删除)、BS(退格)等,常用的ASCII值为 8、9、10 和13 分别转换为退格、制表、换行和回车字符。
48~57 为 0 到 9 十个阿拉伯数字。
65~90 为 26 个大写英文字母,97~122 号为 26 个小写英文字母,其余为一些标点符号、运算符号等。
32~47,58~64,123~126 代表常用标点符号(:‘等);
我们会发现这些中很多都可以在键盘上可以找得到。
tips:
- PHP中我们可以使用
ord($char)来得到一个字符的ASCII码; - 可以用
chr($int)来得到得到对应ASCII数值的字符;
ANSI编码
美国人发明了计算机,并将他们最常用的字符以一个字节存入了计算机,可是世界上这么多的语言都要用计算机来表示怎么办呢?
为了使计算机支持多种语言,不同的国家和地区制定了不同的标准。而对于汉字,产生了 GB2312、 BIG5、 JIS 等各自的编码标准。这些使用 1 个字节表示一个英文字符, 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。
我们在使用window系统保存文件选择编码方式时,会看到有这个ANSI编码这个选项,在不同的windows系统中,ANSI代表着不同的编码。不同ANSI编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。
Unicode编码
来源
既然ANSI编码有着不同编码之间互不兼容不能共存的缺点,而现代网络中又会频繁出现多语言交互,如果在多语言网络传播时,一个 '11011011' 到底代表着什么字符呢?
这时,Unicode 应运而生,它是一个足够大的字符编码映射表,将所有字符都囊括其中,每一个都对应唯一一个 Unicode 数值。如汉字 '好' 对应的 unicode 数值为 '0x597d', 转为二进制为 '0101 1001 0111 1101',表示它需要 16 bit,两个字节,当然还有需要更多字节来保存的字符(原谅我举起不来粟子)。
最新的UCS-4标准是一个尚未填充完全的31位 Unicode 字符集,它使用 31 位来保存字符,加上恒为 0 的首位,共需占据 32 位,4 字节。这样,Unicode 便能保存 2e31 个字符,已经完全足够存储世界上所有的字符了。
tips:
在网络传输中,中文字符会被转换为 Unicode 来传输,用正则匹配一个中文字符为:
\x{4e00}-\x{9fa5},PHP中想查看一个中文字符的 Unicode 码,可以使用
json_encode($str);想 json_encode 保持原中文不自动转为 Unicode 可以使用
json_encode($str, JSON_UNESCAPED_UNICODE);添加一个 option 常量。PHP 中各种编码方式的转换可以看一下我的这篇博客:PHP用mb_string函数库处理与windows相关中文字符
乱码的产生就是因为对数据编码和解码的方式不同: windows中使用 ANSI 标准的 GBK 编码,数据库中使用 Unicode 的不同的编码方式存储,网页浏览器又以不同编码来解析,统一为 UTF-8 进行数据编码即可解决这类问题。
注意 Unicode 只是一种符号集,字符存储的具体实现方式看下面
UTF-8
我们知道了按照 Unicode 的标准,存储一个字符最多要使用 4 个字节。如果所有的字符都按照这个标准来存储,那么欧美国家可能要哭了,因为他们本来可以用一个字节轻松存储文档的,因为国际化,所有的存储空间要增大三倍。为了解决这个问题,UTF-8(8-bit Unicode Transformation Format)出现了。
UTF-8采用变长的编码方式,使用 1~4 个字节来表示一个符号:
- 对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
- 对于 n 字节的符号(n>1),第一个字节的前 n 位都设为 1,第 n+1 位设为0,后面字节的前两位一律设为 10。剩下的没有提及的二进制位,全部为这个符号的 unicode 码。
于是,皆大欢喜,UTF-8 成为了互联网使用最广泛的 Unicode 编码实现方式。
除此之外,Unicode 还有UTF-7、Punycode、CESU-8、SCSU、UTF-32、GB18030 等实现方式;
UTF8MB4
utf8mb4 并不是 Unicode 的实现方式之一,它是 mysql 的编码方式,在最新的 mysql 中,utf8mb4 已经可以代替 utf8,并具有 utf8 不具有的特点。
mb4, 即 most bytes 4, mysql 的 utf8 编码最多使用 3 个字节存储一个字符,在存储 4 字节字符的时候会报错,而 utf8mb4 最多可以使用4个字节来存储一个字符。所以它可以用来存储更多的 Unicode 字符,包括一些 Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上),和很多不常用的汉字,以及任何新增的 Unicode 字符。
由于 utf8mb4 为 utf8 的超集,所以 utf8 编码的 mysql 数据库可以平滑过渡到 utf8mb4。
Url编码
url 编码是 web 开发中最常用的编码了。由于 url 中一些字符有特殊的作用,那么它被称为保留字符(reserved purpose),如 = 用来赋值, ? 用来表示 query_string 的开始, # 用来标识锚点。当我们仅仅想把这些字符当作普通字符串传输该怎么办呢,这就需要使用 url 编码。
URL编码(URL encoding),由于其使用 % 为前缀来替代特殊字符,也被称作百分号编码,是特定上下文的统一资源定位符 (URL)的编码机制。也用于为 "application/x-www-form-urlencoded" MIME 准备数据, 因为它用于通过 HTTP 的请求操作 (request) 提交 HTML 表单数据。
转换规则:
首先需要把该字符的 ASCII 的值表示为两个十六进制的数字,然后在其前面放置转义字符( % ),置入 URI 中的相应位置;对于非 ASCII 字符(如中文等), 需要转换为 UTF-8 字节序, 然后每个字节按照上述方式表示。
下表是常见的字符和 urlencode 之后的 标识:
| char | url | char | url | char | url | char | url | char | url |
|---|---|---|---|---|---|---|---|---|---|
| ! | %21 | # | %23 | $ | %24 | & | %26 | ' | %27 |
| ( | %28 | ) | %29 | * | %2A | + | %2B | , | %2C |
| / | %2F | : | %3A | ; | %3B | = | %3D | ? | %3F |
| @ | %40 | [ | %5B | ] | %5D |
tips: PHP中使用 urlencode() 和 urldecode() 进行 url 的编码和解码。
Base64编码
base64 也是一种 web 开发中的常用编码,它能实现简单的可逆加密,同时在系统之间传输二进制等字符使用 base64 编码也很方便。
它使用 A-Z a-z 0-9 + / 等 64 (2e6) 个字符来表示字符。严格来说,还有用来标识结尾处分组的字节数的 = , 它只会出现在编码串的最后。
编码规则:
将一个字符串以分为三个字节(3 * 8 = 24 bit)为一个分组, 将此 24 个 bit 分为四组,每组 6 bit, 然后使用 其 6 bit 对应的十进制数来映射出一个 base64 字符;
如 UTF-8(三个字节表示一个中文) 中文 ‘琪’ 转 base64 的过程为
- 转换为十六进制表示为
e790aa; - 每个十六进制字符转换为4个二进制bit为
11100111 10010000 10101010; - 拆分为四个 6 bit 分组为
111001 111001 000010 101010; - 对应的十进制数字为
57 57 2 42; - 对应 base64 编码 为
55Cq;
十进制对应 base64 编码的 映射表如下:
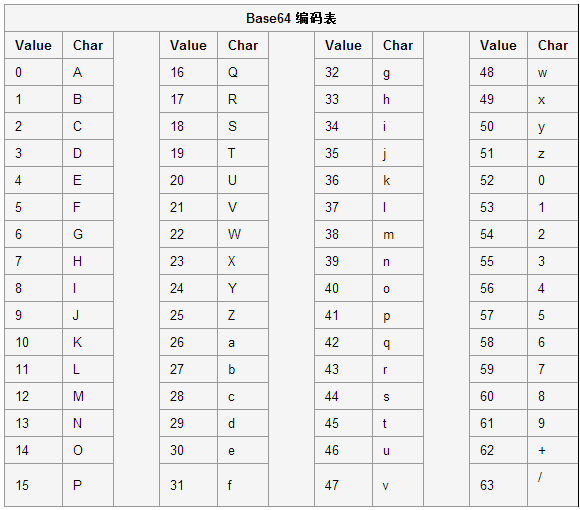
那么一个字符串拆分到最后不足三字节了怎么办呢?
- 二个字节的情况:将这二个字节的 16 bit 分为三组,那么最后一组只有 4 bit (16 % 6 = 4); 在这 4 个 bit 末尾添加 2 个 0 同样凑成 6 bit;再在末尾补上一个
=号标识补位,以便于解码; - 一个字节的情况:将这一个字节一共 8 bit 分为两组,那么最后一组只有 2 bit (8 % 6 = 2); 在这 2 个 bit 末尾添加 4 个 0 同样凑成 6 bit;再在末尾补上
==号标识补位,以便于解码;
由于原来三个字节的字符最后转换成四个字节来表示,base64 编码后字符串长度一般为原来 的 3/4。
以下是我为了完全了解 base64 编码自己用 PHP 实现的一个 base64 编码类(写完编码犯懒了。。。):
<?php
class Base64 {
private $mapping = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H',
'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f',
'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r',
's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '0', '1', '2', '3',
'4', '5', '6', '7', '8', '9', '+', '/',];
/**
* base64 主方法
*
* @param $str
*
* @return string
*/
public function encode($str) {
// 将字符串unpack成为十六进制
$unpacked = unpack('H*', $str);
$hex = str_split($unpacked[1]);
$bin_str = $this->HexToBin($hex);
return $this->binToBase64($bin_str);
}
/**
* 将二进制字符串分组后映射为对应的base64字符串
*
* @param $bin_str
*
* @return string
*/
private function binToBase64($bin_str) {
$base64_str = '';
$bin_list = str_split($bin_str, 6);
foreach ($bin_list as $bin) {
$append = '';
switch (strlen($bin)) {
// $bin为6位的不用特殊处理
case 6:
break;
// $bin为4位的是二字节字符串 2*8%6 = 4
case 4:
$bin = str_pad($bin, 6, '0', STR_PAD_RIGHT);
$append = '=';
break;
// $bin为2位的是一字节字符串 1*8%6 = 2
case 2:
$append = '==';
$bin = str_pad($bin, 6, '0', STR_PAD_RIGHT);
break;
}
$order = base_convert($bin, 2, 10);
$char = $this->mapping[$order];
$base64_str .= $char . $append;
}
return $base64_str;
}
/**
* 将十六进制字符串转换为二进制字符串
*
* @param $hex
*
* @return string
*/
private function hexToBin($hex) {
$bin_str = '';
foreach ($hex as $char) {
// 将十六进制转为二进制字符串,每个十六进制字符转为4位二进制,不足的以0补充
$bin = base_convert($char, 16, 2);
if (strlen($bin) < 4) {
$bin = str_pad($bin, 4, '0', STR_PAD_LEFT);
}
$bin_str .= $bin;
}
return $bin_str;
}
}
$encoder = new Base64();
var_dump($encoder->encode('枕边书blog')); // 5p6V6L655LmmYmxvZw==
var_dump(base64_encode('枕边书blog')); // 5p6V6L655LmmYmxvZw==tips: 在 PHP 中使用 base64_encode() 和 base64_decode() 进行 base64 编码和解码。
小结
字符集和编码一般不是 web 开发中的重点,但了解一下也挺有意思的,既能增长见识,还能预防哪一天突然踩了其中的坑。
如果您觉得本文对您有帮助,可以帮忙点一下推荐,也可以关注我。如有错漏之处,烦请指出,谢谢。
参考:
阮一峰:字符编码笔记:ASCII,Unicode和UTF-8
WEB开发中的字符集和编码的更多相关文章
- java中的字符集和编码
前言 上次对计算机中的“字符集”和“编码”分别进行了总结,并指出二者之间的区别,不要搞混了,不清楚的再回到上一章看一下.今天再总结下java中是如何使用字符集(主要是Unicode字符集,其他常用字符 ...
- Ruby:字符集和编码学习总结
背景 Ruby直到1.9版本才很好的支持了多字节编码,本文简单总结了今天学习的关于Ruby编码方面的知识. 字符串可以使用不同的编码 在.NET中字符串的编码是一致的,Ruby允许字符串有不同的编码, ...
- .NET:字符集和编码学习总结
背景 一直没有深入的学习字符集和编码的知识(现在也没有深入),今天查阅了一些资料,弄明白了一些事情,本文就简单记录一下. 字符集和编码 字符集是指一些符号组成的集合,编码是对指定字符集如何表示为字节的 ...
- WEB开发中常用的正则表达式
在计算机科学中,正则表达式用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串.在WEB开发中,正则表达式通常用来检测.查找替换某些符合规则的字符串,如检测用户输入E-mai格式是否正确,采集符 ...
- WEB开发中常用的正则表达式集合
在计算机科学中,正则表达式用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串.在WEB开发中,正则表达式通常用来检测.查找替换某些符合规则的字符串,如检测用户输入E-mai格式是否正确,采集符 ...
- [译]如何在Web开发中使用Python
[译]如何在Web开发中使用Python 原文:HOWTO Use Python in the Web 摘要 这篇文档展示了Python如何融入到web中.它介绍了几种Python结合web服务器的方 ...
- 第123天:移动web开发中的常见问题
一.函数库 underscoreJS _.template: <ol class="carousel-indicators"> <!--渲染的HTML字符串--& ...
- Web 开发中 Blob 与 FileAPI 使用简述
本文节选自 Awesome CheatSheet/DOM CheatSheet,主要是对 DOM 操作中常见的 Blob.File API 相关概念进行简要描述. Web 开发中 Blob 与 Fil ...
- 【初码干货】使用阿里云对Web开发中的资源文件进行CDN加速的深入研究和实践
提示:阅读本文需提前了解的相关知识 1.阿里云(https://www.aliyun.com) 2.阿里云CDN(https://www.aliyun.com/product/cdn) 3.阿里云OS ...
随机推荐
- 4.Java网络编程之TCP/UDP
常见传输协议: UDP , TCP UDP协议: 特点: 1.将数据及源和目的封装成数据包中,不需要建立连接 2.每个数据包的大小限制在64K内 ...
- (转载)构建public APIs与CORS
from: https://segmentfault.com/a/1190000000709909 理由:在操作层面详细的讲解了跨域的操作.尤其是对于option请求的详解.收藏. 在构建Public ...
- Autofac - 事件
Autofac在提供之前那些方法的时候, 同时提供了五个事件, 这一篇就看一下这几个事件. 一.五大事件 builder.RegisterType<Person>().As<IPer ...
- 用NPOI从DataBase到Excel '2
NPOI的C# Helper代码2 public static MemoryStream ExportXls(DataTable dt) { HSSFWorkbook wk = new HSSFWor ...
- PHP5各个版本的新功能和新特性总结
因为 PHP 那“集百家之长”的蛋疼语法,加上社区氛围不好,很多人对新版本,新特征并无兴趣.本文将会介绍自 PHP5.2 起,直至 PHP5.6 中增加的新特征 本文目录:PHP5.2 以前:auto ...
- tomcat启动时候报错Can't convert argument: null
一.启动报错: 为了避免导入的项目重名,我先修改了前一个项目的名称. 重新启动该项目至tomcat,报错:java.lang.IllegalArgumentException: Cant conver ...
- 谁在关心toString的性能?
谁在关心toString的性能?没有人!除非当你有大量的数据在批量处理,使用toString产生了许多日志.然后,你去调查为何如此之慢,才意识到大部分的toString方法使用的是introspect ...
- Thinking in Java——笔记(20)
Annotations They provide information that you need to fully describe your program, but that cannot b ...
- python基础之条件控制与循环
Python3 条件控制 Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块. 计算机之所以能做很多自动化的任务,因为它可以自己做条件判断. 比如,输入用户 ...
- 高性能javascript学习笔记系列(5) -快速响应的用户界面和编程实践
参考高性能javascript 理解浏览器UI线程 用于执行javascript和更新用户界面的进程通常被称为浏览器UI线程 UI线程的工作机制可以理解为一个简单的队列系统,队列中的任务按顺序执行 ...