【宇哥带你玩转MySQL】索引篇(一)索引揭秘,看他是如何让你的查询性能指数提升的
场景复现,一个索引提高600倍查询速度?
首先准备一张books表
create table books(
id int not null primary key auto_increment,
name varchar(255) not null,
author varchar(255) not null,
created_at datetime not null default current_timestamp,
updated_at datetime not null default current_timestamp on update current_timestamp
)engine=InnoDB;
然后插入100w条数据
drop procedure prepare_data;
delimiter //
create procedure prepare_data()
begin
declare i int;
set i = 0;
while i < 1000000
do
insert into books(name, author) value (concat('name', i), concat('author', i));
set i = i + 1;
end while;
end //
delimiter ;
call prepare_data();
那么问题来了,现在我们要在这100w本书中找到name为name9000000的书,来看看大概需要多久。
set profiling = 1;
select * from books where name = 'name900000';
show profiles;
set profiling = 0;
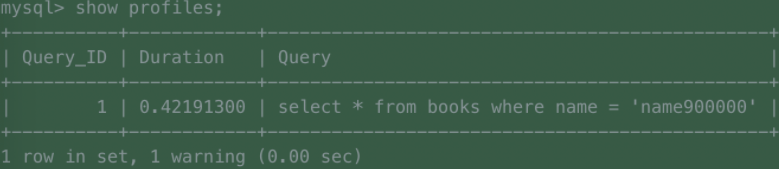
(图一)
大概在400ms左右,我不是很满意这个查询的速度,那么如何提升查询速度呢?建个索引吧!
create index idx_books_name on books(name);
创建索引后我们再看看查询的速度
set profiling = 1;
select * from books where name = 'name900000';
show profiles;
set profiling = 0;
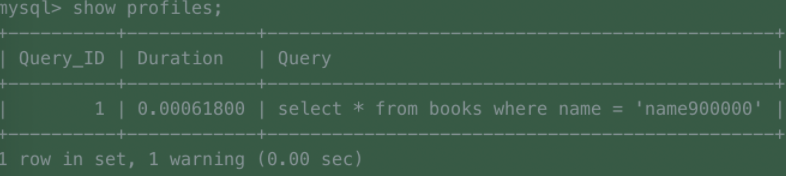
(图二)
可以发现,只需要6ms,索引为我们带来600倍的速度提升,那么为什么索引可以带来这么大的查询速度提升呢?
索引揭秘
想象一下, 现在我们有100w条数据,如何快速的通过name找到符合条件的数据
如果这100w条数据是按照name有序排列的,那么我们就可以使用二分搜索,这样每次可以排除一半数据。那么100w数据最多只需要查询 ~= 20次就可以找到
~= 20次就可以找到
运行过程类型下图
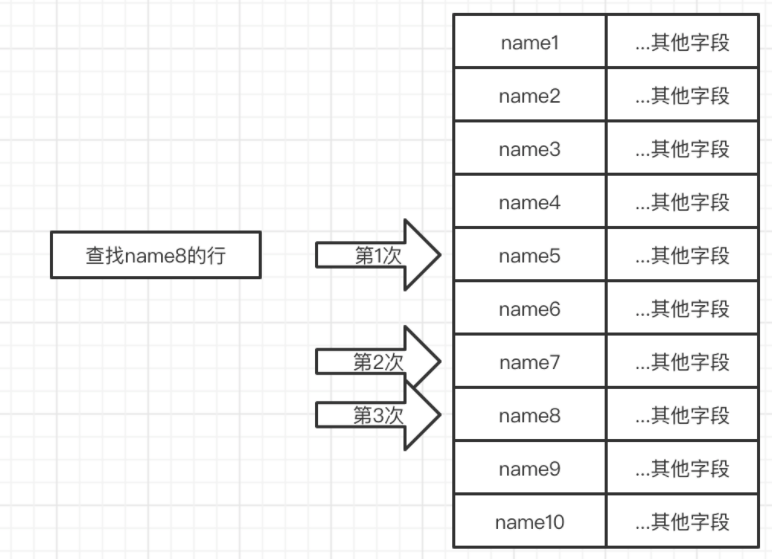
(图三)
这里可以发现一个问题,在比较过程中,我们只用到了name字段,但是却需要把name和其他字段一起加载到内存,这样显然会浪费很多内存,所以我们可以修改结构为下图

(图四)
我们把原来表中的name和id字段进行一份复制形成了一个新的表,这样的话,当我们根据name来查询数据时,只需要把name和id两个数据加载到内存就行了,当找到数据后再根据id找到对应行的其他数据。
其实这个冗余表就是我们常说的索引,索引表会把我们指定的列的数据进行拷贝形成一个新的表,这个表中的数据是有序排列的,如果有多列,则是按声明的前后关系依次比较。
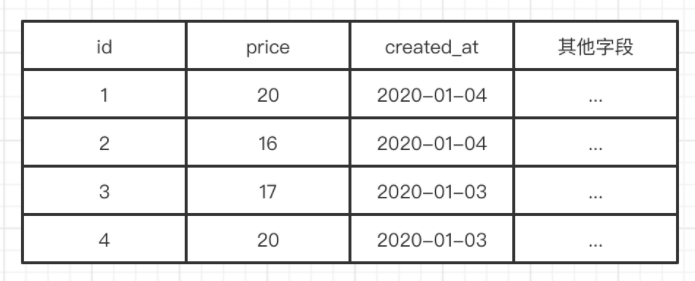
例如,有一个商品表items,其中有名称、价格、创建日期等字段
create table items
(
id int not null primary key auto_increment,
title varchar(255) not null,
price decimal(12,2) not null,
created_at datetime not null,
updated_at datetime not null
) engine = innodb;
(图五)
由于用户喜欢按价格和创建时间查找商品,我们可以创建一个idx_items_price_created_at(price, created_at)的索引,那么他的数据结构就是这样的:先按price排序,再按created_at排序,如图六
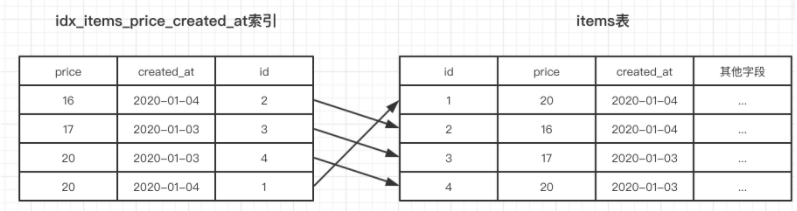
(图六)
通过图六的数据结构我们可以学习到索引使用的一个原则和一个优化
一个原则:最左匹配原则:如果要触发索引使用,需要按索引字段的声明顺序来添加条件过滤
以items表中的idx_items_price_created_at索引使用举例:
# sql1:price + created_at条件,可以使用索引
select * from items where price = "20" and created_at = '2020-01-04'; # sql2:created_at + price条件,可以使用索引,注意虽然此处查询条件顺序和索引顺序不一样,但其实mysql在执行sql前,会先对sql进行语法分析,最终的结果是和sql1一样的。但是我不推荐这种写法,因为对于看代码的人来说没有sql1直观。
select * from items where created_at = "2020-01-04" and price = "20"; # sql3:price 可以使用索引,因为索引表即使只考虑price字段,顺序也是有序的
select * from items where price = "20"; # sql4:crated_at 不可以使用索引,因为索引中如果只考虑craeted_at字段,顺序不能保证有序
select * from items where created_at = "2020-01-04";
一个优化:覆盖索引:如果要查询的字段全在索引上,那么不需要回表
以items表中的idx_items_price_created_at索引使用举例:
# sql1:由于需要所有的字段,该查询在根据idx_items_price_created_at找到id后,还需要根据id再找items表中该条记录的其他字段的值
select * from items where price = "20" and created_at = '2020-01-04';
# sql2: 由于需要的字段在索引上都有,该查询只需要在idx_items_price_created_at索引表找到记录直接返回即可
select price, created_at, id where price = "20" and created_at = '2020-01-04';
小结
通过本章学习,我们了解到索引其实就是一个有序排列的表,我们通过有序排列的优势来加快查询。也正是由于索引是有序排列的,如果想有效使用索引,我们就需要要遵循最左匹配原则。我们还了解到覆盖索引,如果查询的字段全在索引上,可以减少一次回表查询,利用该特性在大批量查询时可以大幅度优化性能。
本章所讲的内容全是以数据全在内存中为前提的,但是真实场景中数据都是在硬盘中保存,如果一个表中的数据可能有好几G,我们不可能把所有的数据都加载到内存然后进行二分搜索,所以下一章会我们讲一讲索引和硬盘的关系。
【宇哥带你玩转MySQL】索引篇(一)索引揭秘,看他是如何让你的查询性能指数提升的的更多相关文章
- 为什么MySQL要用B+树?聊聊B+树与硬盘的前世今生【宇哥带你玩转MySQL 索引篇(二)】
为什么MySQL要用B+树?聊聊B+树与硬盘的前世今生 在上一节,我们聊到数据库为了让我们的查询加速,通过索引方式对数据进行冗余并排序,这样我们在使用时就可以在排好序的数据里进行快速的二分查找,使得查 ...
- MySQL如何创建一个好索引?创建索引的5条建议【宇哥带你玩转MySQL 索引篇(三)】
MySQL如何创建一个好索引?创建索引的5条建议 过滤效率高的放前面 对于一个多列索引,它的存储顺序是先按第一列进行比较,然后是第二列,第三列...这样.查询时,如果第一列能够排除的越多,那么后面列需 ...
- MySQL数据库篇之索引原理与慢查询优化之一
主要内容: 一.索引的介绍 二.索引的原理 三.索引的数据结构 四.聚集索引与辅助索引 五.MySQL索引管理 六.测试索引 七.正确使用索引 八.联合索引与覆盖索引 九.查询优化神器--explai ...
- MySQL数据库篇之索引原理与慢查询优化之二
接上篇 7️⃣ 正确使用索引 一.索引未命中 并不是说我们创建了索引就一定会加快查询速度,若想利用索引达到预想的提高查询速度的效果, 我们在添加索引时,必须遵循以下问题: #1 范围问题,或者说条件 ...
- 老猪带你玩转android自定义控件二——自定义索引栏listview
带索引栏的listview,在android开发非常普遍,方便用户进行字母索引,就像微信通讯录这样: 今天,我们就从零到一实现这个具有索引栏的listview. 怎么实现这个控件了,我们应当梳理出一个 ...
- 阿里小哥带你玩转JVM:揭秘try-catch-finally在JVM底层都干了些啥?
让我们准备一个函数: 然后,反编译他的字节码: 首先我们介绍异常表:在编译生成的字节码中,每个方法都附带一个异常表. 异常表中的每一个条目代表一个异常处理器,并且由 from 指针.to 指针 ...
- 【祥哥带你玩HoloLens开发】了解如何实现远程主机为HoloLens实时渲染
今天有一个兄弟在群里讲到他们的项目模型比较大,单用HoloLens运行设备的性能无法满足需要,问道如何将渲染工作交给服务器来做,讲渲染结果传给HoloLens.正好刚刚看官方github的时候发现一个 ...
- MySQL索引篇之索引存储模型
本文重点介绍下索引的存储模型 二分查找 给定一个1~100的自然数,给你5次机会,你能猜中这个数字吗? 你会从多少开始猜? 为什么一定是50呢?这个就是二分查找的一种思想,也叫折半查找,每 ...
- 老司机带你玩Spring.Net -入门篇
网上有 Spring.Net 的相关的很多介绍的文章还有实践例子,推荐个还不错的博客 Spring.Net 学习笔记 .以前对 Spring.Net 算是有过一面之缘,但却迟迟未真正相识.在网上有太多 ...
随机推荐
- 必备技能四、ajax及token
转https://segmentfault.com/a/1190000008470355?utm_source=tuicool&utm_medium=referral 转 https://ww ...
- 备份Oracl数据库.bat
=========================== @echo off echo ================================================ echo Win ...
- MATLAB神经网络(1)之R练习
)之R练习 将在MATLAB神经网络中学到的知识用R进行适当地重构,再写一遍,一方面可以加深理解和记忆,另一方面练习R,比较R和MATLAB的不同.如要在R中使用之前的数据,应首先在MATLAB中用w ...
- Vue2.0 【第一季】第7节 v-bind指令
目录 Vue2.0 [第一季] 第7节 v-bind指令 第7节 v-bind指令 v-bind缩写 绑定CSS样式 Vue2.0 [第一季] 第7节 v-bind指令 第7节 v-bind指令 v- ...
- ajax4
用jquery实现json jquery.ajax([settings]) type类型使用“POST”或者“GET”,默认使用get URL:发送请求地址 data:是一个对象,连同请求发送到服务器 ...
- 在k3d上快速安装Istio,助你在本地灵活使用K8S!
作者丨Mitsuyuki Shiiba 原文链接: https://dev.to/bufferings/tried-k8s-istio-in-my-local-machine-with-k3d-52g ...
- 【分布式锁】03-使用Redisson实现RedLock原理
前言 前面已经学习了Redission可重入锁以及公平锁的原理,接着看看Redission是如何来实现RedLock的. RedLock原理 RedLock是基于redis实现的分布式锁,它能够保证以 ...
- Python第一周作业
import turtle turtle.color('black','red') turtle.pensize(10) turtle.begin_fill() for i in range(5): ...
- MySQL笔记(3)-- SQL分析
Linux服务器安装MySQL后,直接命令mysql进入服务,需进行修改: /usr/bin/mysqladmin -u root password 123456 设置开机自启动: chkconfig ...
- fastjson JSONObject.toJSONString 出现 $ref: "$."的解决办法(重复引用)
首先,fastjson作为一款序列化引擎,不可避免的会遇到循环引用的问题,为了避免StackOverflowError异常,fastjson会对引用进行检测. 如果检测到存在重复/循环引用的情况,fa ...