golang slice 源码解读
本文从源码角度学习 golang slice 的创建、扩容,深拷贝的实现。
内部数据结构
slice 仅有三个字段,其中array 是保存数据的部分,len 字段为长度,cap 为容量。
type slice struct {
array unsafe.Pointer // 数据部分
len int // 长度
cap int // 容量
}
通过下面代码可以输出空slice 的大小:
package main
import "fmt"
import "unsafe"
func main() {
data := make([]int, 0, 3)
// 24 len:8, cap:8, array:8
fmt.Println(unsafe.Sizeof(data))
// 我们通过指针的方式,拿到数组内部结构的字段值
ptr := unsafe.Pointer(&data)
opt := (*[3]int)(ptr)
// addr, 0, 3
fmt.Println(opt[0], opt[1], opt[2])
data = append(data, 123)
fmt.Println(unsafe.Sizeof(data))
shallowCopy := data[:1]
ptr1 := unsafe.Pointer(&shallowCopy)
opt1 := (*[3]int)(ptr1)
fmt.Println(opt1[0])
}
创建
创建一个slice,其实就是分配内存。cap, len 的设置在汇编中完成。

下面的代码主要是做了容量大小的判断,以及内存的分配。
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 获取需要申请的内存大小
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// 分配内存
// 小对象从当前P 的cache中空闲数据中分配
// 大的对象 (size > 32KB) 直接从heap中分配
// runtime/malloc.go
return mallocgc(mem, et, true)
}
append
对于不需要内存扩容的slice,直接数据拷贝即可。
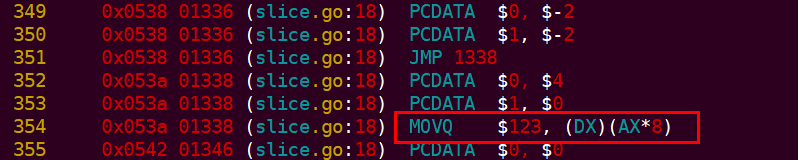
上面的DX 存放的就是array 指针,AX 是数据的偏移. 将 123 存入数组。
而对于容量不够的情况,就需要对slice 进行扩容。这也是slice 比较关心的地方。 (因为对于大slice,grow slice会影响到内存的分配和执行的效率)
func growslice(et *_type, old slice, cap int) slice {
// 静态分析, 内存扫描
// ...
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
// 如果存储的类型空间为0, 比如说 []struct{}, 数据为空,长度不为空
if et.size == 0 {
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
// 如果新容量大于原有容量的两倍,则直接按照新增容量大小申请
newcap = cap
} else {
if old.len < 1024 {
// 如果原有长度小于1024,那新容量是老容量的2倍
newcap = doublecap
} else {
// 按照原有容量的1/4 增加,直到满足新容量的需要
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// 通过校验newcap 大于0检查容量是否溢出。
if newcap <= 0 {
newcap = cap
}
}
}
var overflow bool
var lenmem, newlenmem, capmem uintptr
// 为了加速计算(少用除法,乘法)
// 对于不同的slice元素大小,选择不同的计算方法
// 获取需要申请的内存大小。
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size):
// 二的倍数,用位移运算
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
// 其他用除法
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
// 判断是否会溢出
if overflow || capmem > maxAlloc {
panic(errorString("growslice: cap out of range"))
}
// 内存分配
var p unsafe.Pointer
if et.kind&kindNoPointers != 0 {
p = mallocgc(capmem, nil, false)
// 清空不需要数据拷贝的部分内存
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
p = mallocgc(capmem, et, true)
if writeBarrier.enabled { // gc 相关
// Only shade the pointers in old.array since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem)
}
}
// 数据拷贝
memmove(p, old.array, lenmem)
return slice{p, old.len, newcap}
}
切片拷贝 (copy)
切片的浅拷贝
shallowCopy := data[:1]
ptr1 := unsafe.Pointer(&shallowCopy)
opt1 := (*[3]int)(ptr1)
fmt.Println(opt1[0])
下面是上述代码的汇编代码:
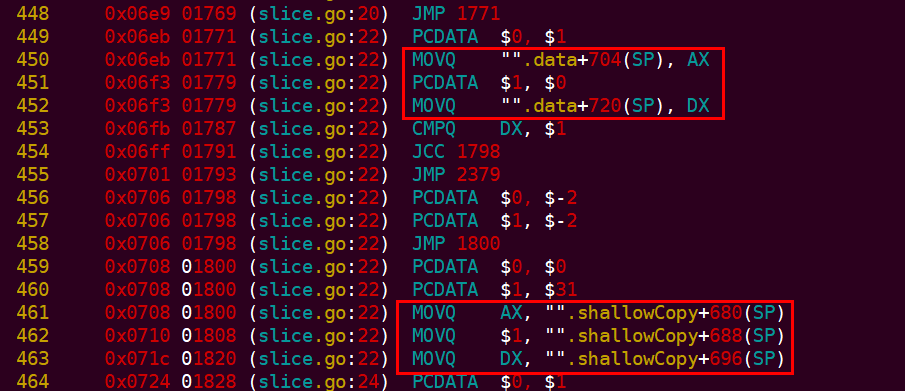
上面,先将 data 的成员数据拷贝到寄存器,然后从寄存器拷贝到shallowCopy的对象中。(注意到只是拷贝了指针而已, 所以是浅拷贝)
切片的深拷贝
深拷贝也比较简单,只是做了一次内存的深拷贝。
func slicecopy(to, fm slice, width uintptr) int {
if fm.len == 0 || to.len == 0 {
return 0
}
n := fm.len
if to.len < n {
n = to.len
}
// 元素大小为0,则直接返回
if width == 0 {
return n
}
// 竟态分析和内存扫描
// ...
size := uintptr(n) * width
// 直接内存拷贝
if size == 1 { // common case worth about 2x to do here
*(*byte)(to.array) = *(*byte)(fm.array) // known to be a byte pointer
} else {
memmove(to.array, fm.array, size)
}
return n
}
// 字符串slice的拷贝
func slicestringcopy(to []byte, fm string) int {
if len(fm) == 0 || len(to) == 0 {
return 0
}
n := len(fm)
if len(to) < n {
n = len(to)
}
// 竟态分析和内存扫描
// ...
memmove(unsafe.Pointer(&to[0]), stringStructOf(&fm).str, uintptr(n))
return n
}
其他
- 汇编的生成方法
go tool compile -N -S slice.go > slice.S
需要了解unsafe.Pointer 的使用
slice.go 位于 runtime/slice.go
上述代码使用 go1.12.5 版本
还有一点需要提醒, type 长度为0的对象。比如说 struct{} 类型。(所以,很多使用chan struct{} 做channel 的传递,节省内存)
package main
import "fmt"
import "unsafe"
func main() {
var data [100000]struct{}
var data1 [100000]int
// 0
fmt.Println(unsafe.Sizeof(data))
// 800000
fmt.Println(unsafe.Sizeof(data1))
}

golang slice 源码解读的更多相关文章
- go 中 sort 如何排序,源码解读
sort 包源码解读 前言 如何使用 基本数据类型切片的排序 自定义 Less 排序比较器 自定义数据结构的排序 分析下源码 不稳定排序 稳定排序 查找 Interface 总结 参考 sort 包源 ...
- underscore 源码解读之 bind 方法的实现
自从进入七月以来,我的 underscore 源码解读系列 更新缓慢,再这样下去,今年更完的目标似乎要落空,赶紧写一篇压压惊. 前文 跟大家简单介绍了下 ES5 中的 bind 方法以及使用场景(没读 ...
- jQuery.Callbacks 源码解读二
一.参数标记 /* * once: 确保回调列表仅只fire一次 * unique: 在执行add操作中,确保回调列表中不存在重复的回调 * stopOnFalse: 当执行回调返回值为false,则 ...
- 第二十四课:jQuery.event.remove,dispatch的源码解读
本课还是来讲解一下jQuery是如何实现它的事件系统的.这一课我们先来讲一下jQuery.event.remove的源码解读. remove方法的目的是,根据用户传参,找到事件队列,从里面把匹配的ha ...
- nodeJS之eventproxy源码解读
1.源码缩影 !(function (name, definition) { var hasDefine = typeof define === 'function', //检查上下文环境是否为AMD ...
- Webpack探索【16】--- 懒加载构建原理详解(模块如何被组建&如何加载)&源码解读
本文主要说明Webpack懒加载构建和加载的原理,对构建后的源码进行分析. 一 说明 本文以一个简单的示例,通过对构建好的bundle.js源码进行分析,说明Webpack懒加载构建原理. 本文使用的 ...
- Bert系列(二)——源码解读之模型主体
本篇文章主要是解读模型主体代码modeling.py.在阅读这篇文章之前希望读者们对bert的相关理论有一定的了解,尤其是transformer的结构原理,网上的资料很多,本文内容对原理部分就不做过多 ...
- go中panic源码解读
panic源码解读 前言 panic的作用 panic使用场景 看下实现 gopanic gorecover fatalpanic 总结 参考 panic源码解读 前言 本文是在go version ...
- Vue 源码解读(3)—— 响应式原理
前言 上一篇文章 Vue 源码解读(2)-- Vue 初始化过程 详细讲解了 Vue 的初始化过程,明白了 new Vue(options) 都做了什么,其中关于 数据响应式 的实现用一句话简单的带过 ...
随机推荐
- OpenLDAP 多主复制(基于docker容器模式部署)
**本文主要讲述在docker环境下如何进行 OpenLDAP 多主复制,至于 OpenLDAP 原理可以先参考这篇文章了解:https://cloud.tencent.com/developer/a ...
- 李宏毅老师机器学习课程笔记_ML Lecture 3-1: Gradient Descent
引言: 这个系列的笔记是台大李宏毅老师机器学习的课程笔记 视频链接(bilibili):李宏毅机器学习(2017) 另外已经有有心的同学做了速记并更新在github上:李宏毅机器学习笔记(LeeML- ...
- Flume数据采集结合etcd作为配置中心在爬虫数据采集处理中的架构实践。
Apache Flume是一个分布式的.可靠的.可用的系统,用于有效地收集. 聚合和将大量日志数据从许多不同的源移动到一个集中的数据存储,但是其本身是以本地properties作为配置的,配置无法做到 ...
- window的三种系统弹框介绍
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8 ...
- iOS nil,Nil,NULL,NSNULL的区别
nil (id)0 是OC对象的空指针,可正常调用方法(返回空值,false,零值等) Nil (Class)0 是OC类的空指针,主要运用于runtime中,Class c = Nil; 其他特性 ...
- Python中矩阵的完全显示问题以及输出矩阵中的非零元问题
问题:有时需要查看矩阵的所有元素,但矩阵过大时中间部分会用[... ...]号代替,这样不方便数据分析. 解决: # 解决不完全显示问题 import numpy as np np.set_print ...
- WiX 简介
最近研究了一下WIX打包,简单总结一下,方便自己以后查阅,也希望能给需要的人一些提示和帮助. WiX 简介 Windows Installer XML (WiX ) 平台是一组工具与规范,使您能够创建 ...
- CSS盒子模型(boeder)+浮动(float)+定位(position)
盒子的上下层:margin--background-color--background-image--padding--content--border(最外层) 计算一个盒子宽 = 内容的宽(wid ...
- 三层架构之UI层
之前已经发表了BLL,DAL,MODEL,三个层的源码 继续UI层: 先简单实现用户的登录及注册 高级操作可按照上一篇文章进行源码完善 如图所示↑ UI层目录文件 Reg.aspx 进行注册操作 & ...
- javascript中常见的表单验证项
1.不能超过20个字符 <body> <form name=a onsubmit="return test()"> <textarea name=&q ...