人声提取工具Spleeter安装教程(linux)
在安装之前,要确保运行Spleeter的计算机系统是64位,Spleeter不支持32位的系统。如何查看?
因为在linux环境下安装spleeter相对要简单很多,这篇教程先以Ubuntu20.04系统介绍安装教程。(在win系统下可以使用VMware虚拟机安装Ubuntu,之前永恒君也写过教程。)
在安装好Ubuntu20.04系统之后,就可以开始下面的步骤了。
安装步骤
1、下载并安装Anaconda
1-1 下载
Spleeter是基于python语言的工具,而Anaconda就是可以便捷获取python包且对包能够进行管理,同时对环境可以统一管理的发行版本,可以大大减少因为包等依赖项的问题而造成的困扰,提升效率。可以简单理解,Anaconda可以更方便的进行安装Spleeter。
进入官网https://www.anaconda.com/products/individual

选择linux - Python 3.7 - 64-Bit (x86) Installer
如果上面的网站访问慢的话,可以试试这个清华大学的镜像站https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
选择linux的即可
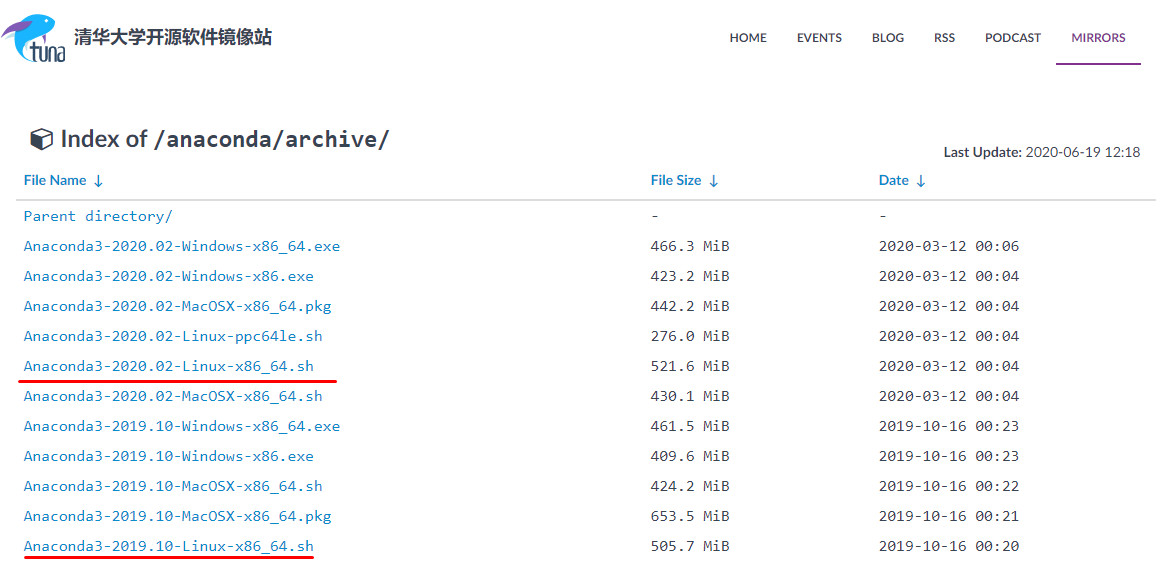
下载下来是一个以.sh结尾的文件,这个是在linux系统中的脚本文件,类似于windows系统中的.exe文件。

1-2 安装
1)在.sh所在的文件夹点击右键,打开终端,输入命令 bash + sh文件名,.sh文件名字要换成你自己的,如:
bash Anaconda3-2019.10-Linux-x86_64.sh

2)按照提示,需要看一些条款,一路回车即可。
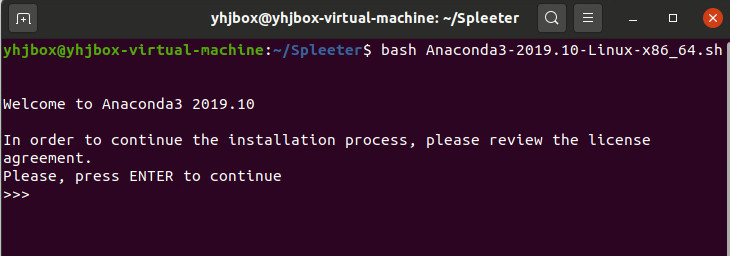
然后会问你是否同意条款,当然输入yes,不然呢?

系统提示安装的默认位置,一般直接回车即可
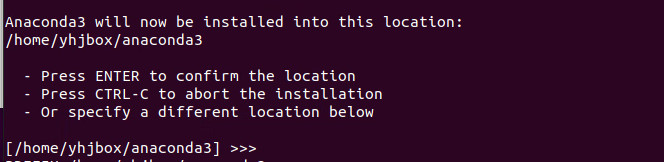
然后就进入安装的过程,稍等一会

接下来提示是否要初始化,一般输入yes

到这个界面,就说明安装成功了。

1-3 修改配置文件condarc
这样下载比较快。(因为源文件都在国外的服务器上,速度经常会不稳定)。
在终端里面输入命令:
sudo gedit ~/.condarc
或者在主目录下面,找到.condarc文件并打开

将下面的内容粘贴进去:
channels:
- defaults
show_channel_urls: true
channel_alias: https://mirrors.tuna.tsinghua.edu.cn/anaconda
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud

2、安装Spleeter
2-1 建议为Spleeter创建单独的运行环境,名称取为music,并激活。(这一步非必须,可直接进行步骤2-2安装Spleeter)
为了程序的稳定性,建议先通过Anaconda创建一个环境专门用来运行Spleeter,这个永恒君命名为music,使用python3.7。
打开终端,输入
conda activate base
conda create -n music python=3.7 #创建一个python3.7的环境,名字为music

完成之后,激活music环境,终端输入
conda activate music

2-2 终端输入下面的命令,安装Spleeter,这个过程视网络情况,可能需要耐心等待一会。
conda install -c conda-forge spleeter
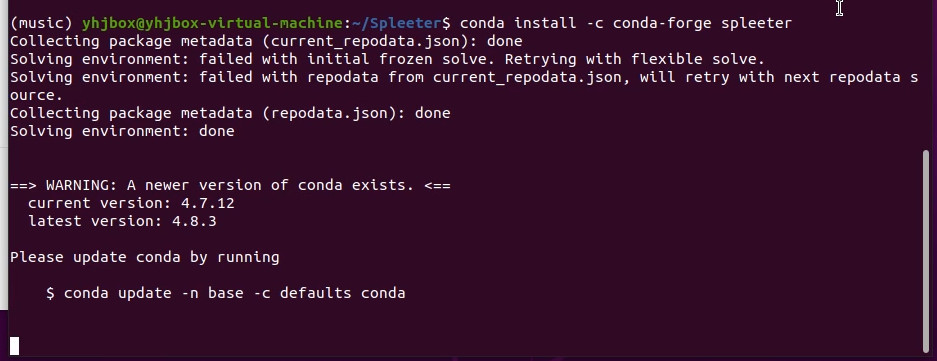
出现下面的提示,就说明安装完成了。

3、下载训练模型(一定要注意存放的路径)
第一次分离音轨前需要给Spleeter一个“示范”,需要有个pretrained models(预训练模块)。
下载地址:
https://github.com/deezer/spleeter/releases

下载图上2stems,分离人声的话一般只需要2轨即可。
在主目录下面新建pretrained_models\2stems路径文件夹,将下载的模型文件解压到文件夹里面。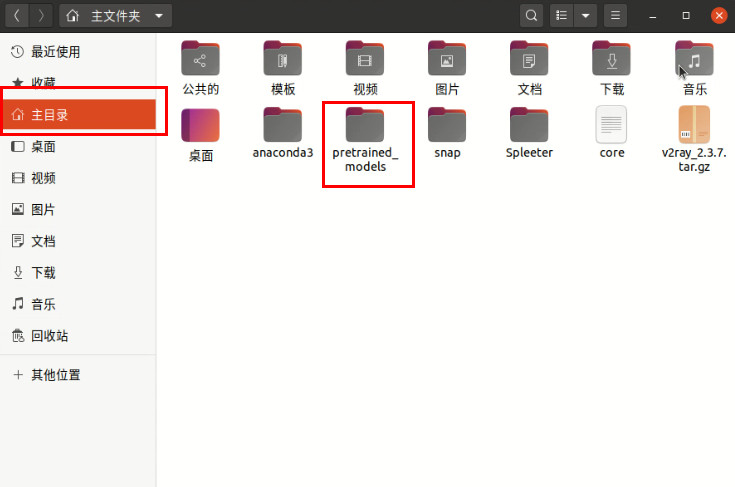
如果你使用的是4stems、5stems,则要相对应的在pretrained_models文件夹下面建立4stems、5stems文件夹。
4、分离提取人声
把需要分离的原始音乐文件 ppxhn.mp3 放在主目录,然后终端键入命令运行:
spleeter separate -i ppxhn.mp3 -p spleeter:2stems -o output
使用的是4stems、5stems的话,只需要把上面命令2stems改成4stems或者5stems即可。
出现下面的字样就说明提取成功了,在主目录下面会生成一个output\ppxhn的文件夹


accompaniment.wav是提取的背景
vocals.wav是提取的人声

小结一下
1、安装Anaconda,修改配置文件condarc。
2、安装Spleeter
3、下载训练模型
4、分离提取人声
其它问题:
1、32位win系统无法使用,64位系统可以使用,建议搭配64位的Python程序或者Anaconda。
2、模型文件始终下载不下来,手动下载并放置到指定文件夹
模型下载地址:https://github.com/deezer/spleeter/releases
特别地,一般模型下载很慢而且不容易成功完成,可以建议使用GitHub文件加速下载地址转换:https://shrill-pond-3e81.hunsh.workers.dev/,转换后使用idm等下载即可。
下载成功后在主目录下依次建立文件夹 pretrained_models\2stems,将2stems.tar.gz解压缩后放置到这个文件夹中即可。
类似地也可建立文件夹并放置模型文件:
pretrained_models\2stems-finetune
pretrained_models\4stems
pretrained_models\4stems-finetune
pretrained_models\5stems
pretrained_models\5stems-finetune
-finetune这种是更为精确的高质量模型,使用方法也一样。
3、拆分类型选项
4stems、4stems、5stems三种分别对应分成2轨、4轨和5轨
人声(歌声)、伴奏分离 (2个音轨)
人声、鼓、贝斯、其他分离 (4个音轨)
人声、鼓、贝斯、钢琴、其他分离 (5个音轨)
4、支持的音频文件有mp3、wav、ogg
5、一次分离多个文件(比较费资源,不推荐)
spleeter separate \
-i <path/to/audio1.mp3> <path/to/audio2.wav> <path/to/audio3.ogg> \
-o audio_output
人声提取工具Spleeter安装教程(linux)的更多相关文章
- idea开发工具下载安装教程
我用这款工具主要用于java开发 在安装这个工具之前需要配置java的环境 java的jdk环境配置 jdk:1.8 jdk官网下载链接 --->点我 进入之后,下拉 选择 jdk1.8版本 ...
- Windows下Redis3.2.10及图像化工具redis-desktop-manager安装教程
1.下载地址: GitHub地址:https://github-production-release-asset-2e65be.s3.amazonaws.com/3402186/bb1d10fc-3f ...
- 深度学习工具LabelXml安装教程
LabelXml安装教程 1,下载LabelXml工具 前往github上下载labelxml,官网地址如下:https://github.com/tzutalin/labelImg 下载打包源码为z ...
- 自动化构建工具gradle安装教程(使用sdkman安装)
gradle是什么?(wiki解释) Gradle是一个基于Apache Ant和Apache Maven概念的项目自动化建构工具.它使用一种基于Groovy的特定领域语言来声明项目设置,而不是传统的 ...
- Navicat Premium 15 安装包&激活工具及安装教程(亲测可用)
Navicat Premium 15 安装包及激活工具 网盘地址: 链接:https://pan.baidu.com/s/1GU9qgdG1dRCw9Un8H9Ba9A提取码:F1r9 开始安装 下载 ...
- Typecho 安装教程 -- Linux
1.下载宝塔面板 1 使用 SSH 连接工具,如堡塔SSH终端连接到您的 Linux 服务器后,挂载磁盘,根据系统执行相应命令开始安装(大约2分钟完成面板安装): 2 Centos安装脚本 yum i ...
- mysql安装教程linux
https://www.cnblogs.com/YangshengQuan/p/8431520.html 设置sql远程访问
- Bug管理工具MantisBT-2.18.0安装教程
Bug管理工具MantisBT安装教程 MantisBT官网下载地址:https://sourceforge.net/projects/mantisbt/# 写于:2018.12.1 如上传博客资料图 ...
- PyCharm 2019 2.3 软件安装教程(1.补丁破解2.破解码)
一:补丁破解 PyCharm 2019 2.3 下载地址 https://pan.baidu.com/s/1HaWFcbO-x4vZuT6mVC0AGA 提取码:elu7 更多破解教程微信公众号关注“ ...
随机推荐
- Istio Polit-agent & Envoy 启动流程
开篇 通过上一篇 Istio Sidecar注入原理 文章可以发现,在应用提交到kubernate部署时已经同时注入了Sidecar应用. 细心的话应该还可以发现,除了注入了istio-proxy应用 ...
- [编辑排版]小技巧---markdown 转 richText
Markdown 使用markdown,可以方便地编辑富文本,VSCode自带了对markdown的支持,编辑完成后可点击右上角预览,实时查看效果. 在github上有给账号,就可以使用GithubP ...
- [Python基础]006.IO操作
IO操作 输入输出 print raw_input input 文件 打开文件 关闭文件 读文件 写文件 文件指针 实例 输入输出 输入输出方法都是Python的内建函数,并且不需要导入任何的包就可以 ...
- [Objective-C] 011_数据持久化_NSKeyedArchiver
在日常开发中对于NSString.NSDictionary.NSArray.NSData.NSNumber这些基本类的数据持久化,可以用属性列表的方法持久化到.plist 文件中.但是一些我们自定义的 ...
- 50个SQL语句(MySQL版) 问题六
--------------------------表结构-------------------------- student(StuId,StuName,StuAge,StuSex) 学生表 tea ...
- Java实现 LeetCode 461 汉明距离
461. 汉明距离 两个整数之间的汉明距离指的是这两个数字对应二进制位不同的位置的数目. 给出两个整数 x 和 y,计算它们之间的汉明距离. 注意: 0 ≤ x, y < 231. 示例: 输入 ...
- Java实现 蓝桥杯VIP 算法训练 集合运算
问题描述 给出两个整数集合A.B,求出他们的交集.并集以及B在A中的余集. 输入格式 第一行为一个整数n,表示集合A中的元素个数. 第二行有n个互不相同的用空格隔开的整数,表示集合A中的元素. 第三行 ...
- Linux 文件系统常用命令
文件系统查看命令df df:查看分区,单位默认是KB df -h 统计目录或文件大小du du /etc/:会列出/etc/目录下的所有子目录所占的空间,最后给出/etc/目录的大小,属于高负载命令, ...
- Redis企业级数据备份与恢复方案
一.持久化配置 RBD和AOF建议同时打开(Redis4.0之后支持) RDB做冷备,AOF做数据恢复(数据更可靠) RDB采取默认配置即可,AOF推荐采取everysec每秒策略 AOF和RDB还不 ...
- [bx] and loop
1.[bx] 表示一个内存单元,它的偏移地址在bx中 mov al,[bx] 2.描述符号() 来表示一个寄存器或一个内存单元中的内容. 约定符号idata表示常量. 3.loop 标号 CPU在执行 ...