线性回归 - LinearRegression - 预测糖尿病 - 量化预测的质量
线性回归是分析一个变量与另外一个或多个变量(自变量)之间,关系强度的方法。
线性回归的标志,如名称所暗示的那样,即自变量与结果变量之间的关系是线性的,也就是说变量关系可以连城一条直线。
模型评估:量化预测的质量
https://scikit-learn.org/stable/modules/model_evaluation.html#model-evaluation
线性回归的 7种 预测质量方法,

1、导包,
# 导包
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline from sklearn.linear_model import LinearRegression
import sklearn.datasets as datasets
2、加载数据集, 糖尿病数据
# 获取数据集 diabetes
data = datasets.load_diabetes()
data
{'data': array([[ 0.03807591, 0.05068012, 0.06169621, ..., -0.00259226,
0.01990842, -0.01764613],
[-0.00188202, -0.04464164, -0.05147406, ..., -0.03949338,
-0.06832974, -0.09220405],
[ 0.08529891, 0.05068012, 0.04445121, ..., -0.00259226,
0.00286377, -0.02593034],
...,
[ 0.04170844, 0.05068012, -0.01590626, ..., -0.01107952,
-0.04687948, 0.01549073],
[-0.04547248, -0.04464164, 0.03906215, ..., 0.02655962,
0.04452837, -0.02593034],
[-0.04547248, -0.04464164, -0.0730303 , ..., -0.03949338,
-0.00421986, 0.00306441]]),
'target': array([151., 75., 141., 206., 135., 97., 138., 63., 110., 310., 101.,
69., 179., 185., 118., 171., 166., 144., 97., 168., 68., 49.,
68., 245., 184., 202., 137., 85., 131., 283., 129., 59., 341.,
87., 65., 102., 265., 276., 252., 90., 100., 55., 61., 92.,
259., 53., 190., 142., 75., 142., 155., 225., 59., 104., 182.,
128., 52., 37., 170., 170., 61., 144., 52., 128., 71., 163.,
150., 97., 160., 178., 48., 270., 202., 111., 85., 42., 170.,
200., 252., 113., 143., 51., 52., 210., 65., 141., 55., 134.,
42., 111., 98., 164., 48., 96., 90., 162., 150., 279., 92.,
83., 128., 102., 302., 198., 95., 53., 134., 144., 232., 81.,
104., 59., 246., 297., 258., 229., 275., 281., 179., 200., 200.,
173., 180., 84., 121., 161., 99., 109., 115., 268., 274., 158.,
107., 83., 103., 272., 85., 280., 336., 281., 118., 317., 235.,
60., 174., 259., 178., 128., 96., 126., 288., 88., 292., 71.,
197., 186., 25., 84., 96., 195., 53., 217., 172., 131., 214.,
59., 70., 220., 268., 152., 47., 74., 295., 101., 151., 127.,
237., 225., 81., 151., 107., 64., 138., 185., 265., 101., 137.,
143., 141., 79., 292., 178., 91., 116., 86., 122., 72., 129.,
142., 90., 158., 39., 196., 222., 277., 99., 196., 202., 155.,
77., 191., 70., 73., 49., 65., 263., 248., 296., 214., 185.,
78., 93., 252., 150., 77., 208., 77., 108., 160., 53., 220.,
154., 259., 90., 246., 124., 67., 72., 257., 262., 275., 177.,
71., 47., 187., 125., 78., 51., 258., 215., 303., 243., 91.,
150., 310., 153., 346., 63., 89., 50., 39., 103., 308., 116.,
145., 74., 45., 115., 264., 87., 202., 127., 182., 241., 66.,
94., 283., 64., 102., 200., 265., 94., 230., 181., 156., 233.,
60., 219., 80., 68., 332., 248., 84., 200., 55., 85., 89.,
31., 129., 83., 275., 65., 198., 236., 253., 124., 44., 172.,
114., 142., 109., 180., 144., 163., 147., 97., 220., 190., 109.,
191., 122., 230., 242., 248., 249., 192., 131., 237., 78., 135.,
244., 199., 270., 164., 72., 96., 306., 91., 214., 95., 216.,
263., 178., 113., 200., 139., 139., 88., 148., 88., 243., 71.,
77., 109., 272., 60., 54., 221., 90., 311., 281., 182., 321.,
58., 262., 206., 233., 242., 123., 167., 63., 197., 71., 168.,
140., 217., 121., 235., 245., 40., 52., 104., 132., 88., 69.,
219., 72., 201., 110., 51., 277., 63., 118., 69., 273., 258.,
43., 198., 242., 232., 175., 93., 168., 275., 293., 281., 72.,
140., 189., 181., 209., 136., 261., 113., 131., 174., 257., 55.,
84., 42., 146., 212., 233., 91., 111., 152., 120., 67., 310.,
94., 183., 66., 173., 72., 49., 64., 48., 178., 104., 132.,
220., 57.]),
'DESCR': '.. _diabetes_dataset:\n\nDiabetes dataset\n----------------\n\nTen baseline variables, age, sex, body mass index, average blood\npressure, and six blood serum measurements were obtained for each of n =\n442 diabetes patients, as well as the response of interest, a\nquantitative measure of disease progression one year after baseline.\n\n**Data Set Characteristics:**\n\n :Number of Instances: 442\n\n :Number of Attributes: First 10 columns are numeric predictive values\n\n :Target: Column 11 is a quantitative measure of disease progression one year after baseline\n\n :Attribute Information:\n - Age\n - Sex\n - Body mass index\n - Average blood pressure\n - S1\n - S2\n - S3\n - S4\n - S5\n - S6\n\nNote: Each of these 10 feature variables have been mean centered and scaled by the standard deviation times `n_samples` (i.e. the sum of squares of each column totals 1).\n\nSource URL:\nhttps://www4.stat.ncsu.edu/~boos/var.select/diabetes.html\n\nFor more information see:\nBradley Efron, Trevor Hastie, Iain Johnstone and Robert Tibshirani (2004) "Least Angle Regression," Annals of Statistics (with discussion), 407-499.\n(https://web.stanford.edu/~hastie/Papers/LARS/LeastAngle_2002.pdf)',
'feature_names': ['age',
'sex',
'bmi',
'bp',
's1',
's2',
's3',
's4',
's5',
's6'],
'data_filename': 'c:\\python37\\lib\\site-packages\\sklearn\\datasets\\data\\diabetes_data.csv.gz',
'target_filename': 'c:\\python37\\lib\\site-packages\\sklearn\\datasets\\data\\diabetes_target.csv.gz'}
3、将数据分为 训练数据 和 测试数据
# 导包, 将数据分为 训练数据 和 测试数据
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1) display (X_train.shape, y_train.shape, X_test.shape, y_test.shape)
(397, 10)
(397,)
(45, 10)
(45,)
4、建模
# 使用线性回归算法 训练数据
lr = LinearRegression() lr.fit(X_train, y_train)
5、预测数据
# 开始预测数据
lr.predict(X_test)
array([230.00915863, 109.37448796, 135.55277842, 151.10470676,
112.50492861, 60.06173076, 185.98893008, 154.37782567,
226.83758259, 35.04571744, 72.66756812, 58.39584888,
174.04109657, 236.22478163, 140.04573477, 179.59637478,
290.40096377, 232.79655649, 127.57606558, 155.94225585,
233.96170807, 122.18494431, 124.57198973, 97.73726963,
261.60495587, 170.48284605, 128.85673176, 93.16011898,
198.08756371, 179.37427503, 199.42069686, 106.91159532,
114.42691898, 215.81999925, 200.58503886, 168.46631094,
123.85604486, 118.02004664, 189.81321827, 80.30230583,
108.35537981, 80.98007737, 180.839016 , 83.22091387,
117.70861488])
6、查看真实数据
# 查看真实的 结果值, 与上面测试结果 对比
y_test
array([246., 69., 40., 150., 107., 70., 67., 252., 236., 104., 48.,
77., 311., 270., 187., 200., 270., 217., 135., 144., 280., 191.,
65., 170., 303., 138., 42., 158., 222., 85., 173., 129., 68.,
279., 248., 235., 111., 153., 101., 77., 72., 42., 107., 102.,
183.])
7、回归评价得分 (R²得分,决定系数)
回归评价7种方法,
# 调用算法, 算出 评价分, 负无穷 到 1 的范围, 1为最好
lr.score(X_test, y_test)
0.5103097598041384
8、代码实现 预测评价(R²得分,决定系数)
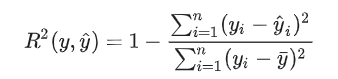
'''
The coefficient R^2 is defined as (1 - u/v), where u is the residual
sum of squares ((y_true - y_pred) ** 2).sum() and v is the total
sum of squares ((y_true - y_true.mean()) ** 2).sum().
'''
y_pred = lr.predict(X_test).round(2)
y_true = y_test # 代码实现 评价标准
# 真实结果: y_true
# 测试结果: y_pred
u = ((y_true - y_pred)**2).sum()
v = ((y_true - y_true.mean())**2).sum()
score = (1 - u/v)
score
0.5103097598041384
线性回归 - LinearRegression - 预测糖尿病 - 量化预测的质量的更多相关文章
- 机器学习之路: python 线性回归LinearRegression, 随机参数回归SGDRegressor 预测波士顿房价
python3学习使用api 线性回归,和 随机参数回归 git: https://github.com/linyi0604/MachineLearning from sklearn.datasets ...
- Eviews 9.0新版本新功能——预测(Auto-ARIMA预测、VAR预测)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 9.预测功能 新增需要方法的预测功能:Auto ...
- 数据挖掘-diabetes数据集分析-糖尿病病情预测_线性回归_最小平方回归
# coding: utf-8 # 利用 diabetes数据集来学习线性回归 # diabetes 是一个关于糖尿病的数据集, 该数据集包括442个病人的生理数据及一年以后的病情发展情况. # 数据 ...
- 量化预测质量之分类报告 sklearn.metrics.classification_report
classification_report的调用为:classification_report(y_true, y_pred, labels=None, target_names=None, samp ...
- 时间序列预测——深度好文,ARIMA是最难用的(数据预处理过程不适合工业应用),线性回归模型简单适用,预测趋势很不错,xgboost的话,不太适合趋势预测,如果数据平稳也可以使用。
补充:https://bmcbioinformatics.biomedcentral.com/articles/10.1186/1471-2105-15-276 如果用arima的话,还不如使用随机森 ...
- 手把手丨我们在UCL找到了一个糖尿病数据集,用机器学习预测糖尿病(三)
梯度提升: from sklearn.ensemble import GradientBoostingClassifier gb=GradientBoostingClassifier(random_s ...
- 数据预测算法-ARIMA预测
简介 ARIMA: AutoRegressive Integrated Moving Average ARIMA是两个算法的结合:AR和MA.其公式如下: 是白噪声,均值为0, C是常数. ARIMA ...
- (转载)微软数据挖掘算法:Microsoft 时序算法之结果预测及其彩票预测(6)
前言 本篇我们将总结的算法为Microsoft时序算法的结果预测值,是上一篇文章微软数据挖掘算法:Microsoft 时序算法(5)的一个总结,上一篇我们已经基于微软案例数据库的销售历史信息表,利用M ...
- 机器学习-线性回归LinearRegression
概述 今天要说一下机器学习中大多数书籍第一个讲的(有的可能是KNN)模型-线性回归.说起线性回归,首先要介绍一下机器学习中的两个常见的问题:回归任务和分类任务.那什么是回归任务和分类任务呢?简单的来说 ...
随机推荐
- Linux 磁盘管理篇,目录管理(一)
目录: 当我们在linux的ext2档案建立一个目录时,ext2会分配一个inode与至少一块Block给该目录,其中inode记录该目录在相关属性,并指向分配到在那块Block,而block ...
- HttpClient之Get请求和Post请求示例
HttpClient之Get请求和Post请求示例 博客分类: Java综合 HttpClient的支持在HTTP/1.1规范中定义的所有的HTTP方法:GET, HEAD, POST, PUT, ...
- 数据结构和算法(Golang实现)(29)查找算法-2-3树和左倾红黑树
某些教程不区分普通红黑树和左倾红黑树的区别,直接将左倾红黑树拿来教学,并且称其为红黑树,因为左倾红黑树与普通的红黑树相比,实现起来较为简单,容易教学.在这里,我们区分开左倾红黑树和普通红黑树. 红黑树 ...
- CocoaPods应用于iOS项目框架管理方案
- AJ学IOS(26)UI之iOS抽屉效果小Demo
AJ分享,必须精品 先看效果 实现过程 第一步,把三个view设置好,还有颜色 #warning 第一步 - (void)addChildView { // left UIView *leftView ...
- Julia的基本知识
知识来源 1.变量.整数和浮点数 Julia和Matllab挺像的,基本的变量,数值定义都差不多,所以就没必要记录了. 2.数学运算 3.函数
- B. 复读机的力量
我们规定一个人是复读机当且仅当他说的每一句话都是复读前一个人说的话. 我们规定一个人是复读机当且仅当他说的每一句话都是复读前一个人说的话. 我们规定一个人是复读机当且仅当他说的每一句话都是复读前一个人 ...
- 如何可视化深度学习网络中Attention层
前言 在训练深度学习模型时,常想一窥网络结构中的attention层权重分布,观察序列输入的哪些词或者词组合是网络比较care的.在小论文中主要研究了关于词性POS对输入序列的注意力机制.同时对比实验 ...
- C语言二维数组超细讲解
用一维数组处理二维表格,实际是可行的,但是会很复杂,特别是遇到二维表格的输入.处理和输出. 在你绞尽脑汁的时候,二维数组(一维数组的大哥)像电视剧里救美的英雄一样显现在你的面前,初识数组的朋友们还等什 ...
- Mysql中的一些类型
列类型--整数类型Tinyint:迷你整形 一个字节=8位 最大能表示的数值是0-255 实际区间 -128~127Smallint:小整形 两个字节 能表示0-65535Mediumint:中整型 ...