树的三种DFS策略(前序、中序、后序)遍历
之前刷leetcode的时候,知道求排列组合都需要深度优先搜索(DFS), 那么前序、中序、后序遍历是什么鬼,一直傻傻的分不清楚。直到后来才知道,原来它们只是DFS的三种不同策略。
N = Node(节点)
L = Left(左节点)
R = Right(右节点)
在深度优先搜索的时候,以Node的访问顺序,定义了三种不同的搜索策略:
前序遍历:结点 —> 左子树 —> 右子树
中序遍历:左子树—> 结点 —> 右子树
后序遍历:左子树 —> 右子树 —> 结点
##前序遍历
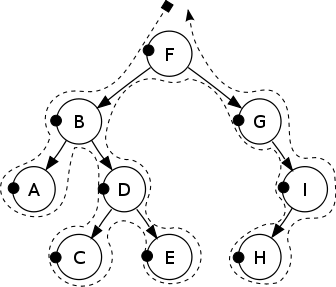
Pre-order: F, B, A, D, C, E, G, I, H.
##中序遍历
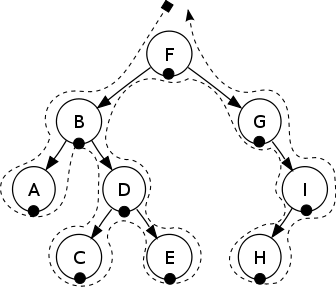
In-order: A, B, C, D, E, F, G, H, I.
在二叉搜索树(BST)中,中序遍历返回递增的一个序列
##后序遍历
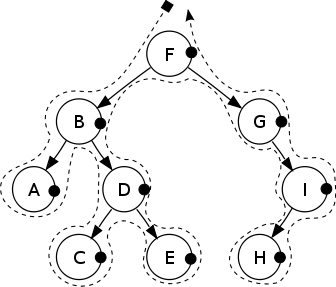
Post-order: A, C, E, D, B, H, I, G, F.
##递归代码
递归实现比较直观容易,通常DFS遍历,都需要传递一个参数 or 设置一个全局变量,来保存结果
def pre_order(self, node, results):
if node is None:
return
results.append(node.val)
self.pre_order(node.left, results)
self.pre_order(node.right, results)
def in_order(self, node, results):
if node is None:
return
self.in_order(node.left, results)
results.append(node.val)
self.in_order(node.right, results)
def post_order(self, node, results):
if node is None:
return
self.post_order(node.left, results)
self.post_order(node.right, results)
results.append(node. 大专栏 树的三种DFS策略(前序、中序、后序)遍历val)
##非递归代码
深度优先遍历的非递归代码,一定用到的是stack数据接口
非递归实现前序和中序还可以,后续遍历就非常烧脑了
前序最简单,相当于for循环所有children,所以一版非递归DFS,就用前序就好了。
中序遍历,由于对于BST有一个递增的特性,所以还是比较常用的
def preorderTraversal(self, root):
results = []
if root is None:
return results
stack = [root]
while(len(stack) > 0):
node = stack.pop()
results.append(node.val)
# right first so left pop fisrt
if node.right is not None:
stack.append(node.right)
if node.left is not None:
stack.append(node.left)
return results
def inorderTraversal(self, root):
results = []
if root is None:
return results
stack = []
node = root
while(len(stack) > 0 or node is not None):
if (node is not None):
stack.append(node)
node = node.left
else:
node = stack.pop()
results.append(node.val)
node = node.right
return results
def postorderTraversal(self, root):
results = []
if root is None:
return results
node = root
stack = []
lastNodeVisted = None
while(len(stack) > 0 or node is not None):
if node is not None:
stack.append(node)
node = node.left
else:
peek = stack[-1] # last element
if (peek.right is not None and lastNodeVisted != peek.right):
node = peek.right
else:
results.append(peek.val)
lastNodeVisted = stack.pop()
return results
–END–
树的三种DFS策略(前序、中序、后序)遍历的更多相关文章
- java:数据结构(四)二叉查找树以及树的三种遍历
@TOC 二叉树模型 二叉树是树的一种应用,一个节点可以有两个孩子:左孩子,右孩子,并且除了根节点以外每个节点都有一个父节点.当然这种简单的二叉树不能解决让树保持平衡状态,例如你一直往树的左边添加元素 ...
- 三种java 去掉字符串中的重复字符函数
三种java 去掉字符串中的重复字符函数 public static void main(string[] args) { system.out.println(removerepeatedchar( ...
- 算法进阶面试题03——构造数组的MaxTree、最大子矩阵的大小、2017京东环形烽火台问题、介绍Morris遍历并实现前序/中序/后序
接着第二课的内容和带点第三课的内容. (回顾)准备一个栈,从大到小排列,具体参考上一课.... 构造数组的MaxTree [题目] 定义二叉树如下: public class Node{ public ...
- 前序+中序->后序 中序+后序->前序
前序+中序->后序 #include <bits/stdc++.h> using namespace std; struct node { char elem; node* l; n ...
- SDUT-2804_数据结构实验之二叉树八:(中序后序)求二叉树的深度
数据结构实验之二叉树八:(中序后序)求二叉树的深度 Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 已知一颗二叉树的中序 ...
- 二叉树 遍历 先序 中序 后序 深度 广度 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- SDUT OJ 数据结构实验之二叉树八:(中序后序)求二叉树的深度
数据结构实验之二叉树八:(中序后序)求二叉树的深度 Time Limit: 1000 ms Memory Limit: 65536 KiB Submit Statistic Discuss Probl ...
- 给出 中序&后序 序列 建树;给出 先序&中序 序列 建树
已知 中序&后序 建立二叉树: SDUT 1489 Description 已知一棵二叉树的中序遍历和后序遍历,求二叉树的先序遍历 Input 输入数据有多组,第一行是一个整数t (t& ...
- 【C&数据结构】---关于链表结构的前序插入和后序插入
刷LeetCode题目,需要用到链表的知识,忽然发现自己对于链表的插入已经忘得差不多了,以前总觉得理解了记住了,但是发现真的好记性不如烂笔头,每一次得学习没有总结输出,基本等于没有学习.连复盘得机会都 ...
随机推荐
- base64字符串转化成图片
package com.dhht.wechat.util; import sun.misc.BASE64Decoder;import sun.misc.BASE64Encoder; import ja ...
- LeetCode No.151,152,153
No.151 ReverseWords 翻转字符串里的单词 题目 给定一个字符串,逐个翻转字符串中的每个单词. 示例 输入: "the sky is blue" 输出: " ...
- 通过if语句实现for循环的提前结束
/************************************************************************* > File Name: mybreakin ...
- Kafa 的安装配置及使用
1.kafka 的简介及应用场景 Apache Kafka是一个分布式的消息系统,可用于统计,日志及流处理 2.kafka 基本原理 3.kafka 集群体系结构 4.kafka实例 https:// ...
- shell_切割日志
可以修改的:1.日志存放目录:logdir='/data/logs/'2.每个类型日志保留个数:savefiles=30 #!/bin/bashnum=$(date -d"+1 day ag ...
- poj-3661 Running(DP)
http://poj.org/problem?id=3661 Description The cows are trying to become better athletes, so Bessie ...
- 对数据集进行最优分箱和WOE转换
对数据集分箱的方式三种,等宽等频最优,下面介绍对数据集进行最优分箱,分箱的其他介绍可以查看其他的博文,具体在这就不细说了: 大体步骤: 加载数据: 遍历所有的feature, 分别处理离散和连续特征: ...
- spring security在异步线程的处理
https://spring.io/guides/topicals/spring-security-architecture 在异步线程中使用SecurityContextHolder , 需要将父线 ...
- 吴裕雄--天生自然 HADOOP大数据分布式处理:安装配置MYSQL数据库
安装之前先安装基本环境:yum install -y perl perl-Module-Build net-tools autoconf libaio numactl-libs # 下载mysql源安 ...
- dhcp server
centos yum install dhcp -y cat /etc/dhcp/dhcpd.conf default-lease-time 7200; max-lease-time 14400; s ...