大数据学习——MapReduce学习——字符统计WordCount
操作背景
jdk的版本为1.8以上
ubuntu12
hadoop2.5伪分布
安装 Hadoop-Eclipse-Plugin
要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 hadoop-eclipse-plugin,可下载 Github 上的 hadoop2x-eclipse-plugin(备用下载地址:http://pan.baidu.com/s/1i4ikIoP)。
下载后,将 release 中的 hadoop-eclipse-kepler-plugin-2.6.0.jar (还提供了 2.2.0 和 2.4.1 版本)复制到 Eclipse 安装目录的 plugins 文件夹中,运行
eclipse -clean 重启 Eclipse 即可(添加插件后只需要运行一次该命令,以后按照正常方式启动就行了)。
配置 Hadoop-Eclipse-Plugin
在继续配置前请确保已经开启了 Hadoop
1. 按照如下流程进入Hadoop Map/Reduce界面
Window--》Preference--》Hadoop Map/Reduce
点击右侧的Browse...选择Hadoop的安装路径,然后点击ok即可
2.按照如下操作到切换 Map/Reduce 开发视图
Window--》Open Perspective--》Other
弹出一个窗口选择Map/Reduce即可
3.建立与 Hadoop 集群的连接
点击 Eclipse软件右下角的 Map/Reduce Locations 面板,在面板中单击右键,选择 New Hadoop Location
在弹出的General选项面板里
设置两处
1.Location Name随便写就是连接名
2.DFS Master的Port与fs.defaultFS(设置为hdfs://localhost:9000)的端口号相同为9000
设置完成以后配置好后,点击左侧 Project Explorer 中的 MapReduce Location (点击三角形展开)就能直接查看 HDFS 中的文件列表了,双击可以查看内容,右键点击可以上传、下载、删除
在 Eclipse 中创建 MapReduce 项目
用刚刚创建的Map/Reduce视图新建目录mymapreduce1/in,在此目录下上传文件文件名为buyer_favorite1,
这个文件的目录和名字可以自行修改,但要注意修改代码中的Path in的路径和文价名
此文件为某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期
buyer_favorite1包含:买家id,商品id,收藏日期这三个字段
内容如下
买家id 商家id 收藏日期
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
点击File--》New--》Other找到Map/Reduce Project点击创建即可。
然后将以下代码放到项目中
代码是是统计每个买家收藏商品数量
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//这个路径是存放用户收藏商品的信息
Path in = new Path("hdfs://localhost:9000/mymapreduce1/in/buyer_favorite1");
//这个路径也可自行设置,但是路径必须不存在
Path out = new Path("hdfs://localhost:9000/mymapreduce1/out");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
/**
*
* 第一个Object表示输入key的类型;第二个Text表示输入value的类型;
*第三个Text表示表示输出键的类型;第四个IntWritable表示输出值的类型
*/
public static class doMapper extends
Mapper<Object, Text, Text, IntWritable> {
public static final IntWritable one = new IntWritable(1);
public static Text word = new Text(); protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
//StringTokenizer是Java工具包中的一个类,用于将字符串进行拆分
//StringTokenizer构造函数的第二个参数是分割符,确认文件中的分割符是三个空格或者一个tab
StringTokenizer tokenizer = new StringTokenizer(value.toString(),
" ");
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
//参数同Map一样,依次表示是输入键类型,输入值类型,输出键类型,输出值类型
public static class doReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); @Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
}
右键此Map/Reduce Project=>Run As=>Run on Hadoop
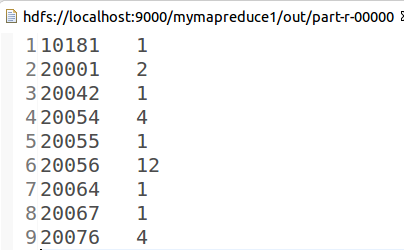
Map/Reduce视图工具查看输出目录中的part-r-00000文件
结果如下
参考资料
http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-eclipse/?tdsourcetag=s_pcqq_aiomsg
大数据学习——MapReduce学习——字符统计WordCount的更多相关文章
- 大数据技术 - MapReduce的Combiner介绍
本章来简单介绍下 Hadoop MapReduce 中的 Combiner.Combiner 是为了聚合数据而出现的,那为什么要聚合数据呢?因为我们知道 Shuffle 过程是消耗网络IO 和 磁盘I ...
- 【机器学习实战】第15章 大数据与MapReduce
第15章 大数据与MapReduce 大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力. 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则 ...
- 大数据学习——mapreduce程序单词统计
项目结构 pom.xml文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns=&q ...
- 【大数据】Hive学习笔记
第1章 Hive基本概念 1.1 什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表, ...
- 【大数据】Sqoop学习笔记
第1章 Sqoop简介 Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MyS ...
- 【大数据】Scala学习笔记
第 1 章 scala的概述1 1.1 学习sdala的原因 1 1.2 Scala语言诞生小故事 1 1.3 Scala 和 Java 以及 jvm 的关系分析图 2 1.4 Scala语言的特点 ...
- 想转行大数据,开始学习 Hadoop?
学习大数据首先要了解大数据的学习路线,首先搞清楚先学什么,再学什么,大的学习框架知道了,剩下的就是一步一个脚印踏踏实实从最基础的开始学起. 这里给大家普及一下学习路线:hadoop生态圈——Strom ...
- 【福利】送Spark大数据平台视频学习资料
没有套路真的是送!! 大家都知道,大数据行业spark很重要,那话我就不多说了,贴心的大叔给你找了份spark的资料. 多啰嗦两句,一个好的程序猿的基本素养是学习能力和自驱力.视频给了你们,能不能 ...
- 大数据-spark-hbase-hive等学习视频资料
不错的大数据spark学习资料,连接过期在评论区评论,再给你分享 https://pan.baidu.com/s/1ts6RNuFpsnc39tL3jetTkg
- 云计算、大数据、编程语言学习指南下载,100+技术课程免费学!这份诚意满满的新年技术大礼包,你Get了吗?
开发者认证.云学院.技术社群,更多精彩,尽在开发者会场 近年来,新技术发展迅速.互联网行业持续高速增长,平均薪资水平持续提升,互联网技术学习已俨然成为学生.在职人员都感兴趣的“业余项目”. 阿里云大学 ...
随机推荐
- Android Studio Madual作为application的使用以及工作空间和modual的区别
Android Studio Madual作为application的使用以及工作空间和modual的区别 前言: 写这篇文章的目的是因为自己使用Android Studio开发时进入了一个误区,后面 ...
- 剑指offer_12.31_Day_1
不用加减乘除做加法 题目描述 写一个函数,求两个整数之和,要求在函数体内不得使用+.-.*./四则运算符号. 不用四则运算,必然是依靠位运算. 位运算包括,与,或,异或,取反,左移,右移. 分别为 ...
- 【SpringBoot】SpringBoot Web开发(八)
本周介绍SpringBoot项目Web开发的项目内容,及常用的CRUD操作,阅读本章前请阅读[SpringBoot]SpringBoot与Thymeleaf模版(六)的相关内容 Web开发 项目搭建 ...
- js去除热点的虚线框
1.一个页面有多张图片,图片的链接为热点绘制,在ie中点击会出现虚线框. <script type="text/javascript"> window.onload = ...
- faster RCNN(keras版本)代码讲解(3)-训练流程详情
转载:https://blog.csdn.net/u011311291/article/details/81121519 https://blog.csdn.net/qq_34564612/artic ...
- 记录 TypeError: render() got an unexpected keyword argument 'renderer' 错误
在网上看到MXShop这个项目,适合Python, Django + drf 进阶的,其中遇到 TypeError: render() got an unexpected keyword argume ...
- php curl模拟post请求提交数据例子总结
php curl模拟post请求提交数据例子总结 [导读] 在php中要模拟post请求数据提交我们会使用到curl函数,下面我来给大家举几个curl模拟post请求提交数据例子有需要的朋友可参考参考 ...
- 吴裕雄--天生自然MySQL学习笔记:MySQL WHERE 子句
MySQL 表中使用 SQL SELECT 语句来读取数据. 如需有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句中. 语法 以下是 SQL SELECT 语句使用 WHERE ...
- HDU - 1251 字典树模板题
Ignatius最近遇到一个难题,老师交给他很多单词(只有小写字母组成,不会有重复的单词出现),现在老师要他统计出以某个字符串为前缀的单词数量(单词本身也是自己的前缀). Input输入数据的第一部 ...
- SQL 2005 带自增列 带外键约束 数据导入导出
1,生成建表脚本 选中要导的表,点右键-编写表脚本为-create到 ,生成建表脚本 2,建表(在新库),但不建外键关系 不要选中生成外键的那部分代码,只选择建表的代码 3,导数据,用SQL STU ...