Solr4.8.0源码分析(11)之Lucene的索引文件(4)
Solr4.8.0源码分析(11)之Lucene的索引文件(4)
1. .dvd和.dvm文件
.dvm是存放了DocValue域的元数据,比如DocValue偏移量。
.dvd则存放了DocValue的数据。
在Solr4.8.0中,dvd以及dvm用到的Lucene编码格式是Lucene45DocValuesFormat。跟之前的文件格式类似,它分别包含Lucene45DocValuesProducer
和Lucene45DocValuesConsumer来实现该文件的读和写。
@Override
public DocValuesConsumer fieldsConsumer(SegmentWriteState state) throws IOException {
return new Lucene45DocValuesConsumer(state, DATA_CODEC, DATA_EXTENSION, META_CODEC, META_EXTENSION);
} @Override
public DocValuesProducer fieldsProducer(SegmentReadState state) throws IOException {
return new Lucene45DocValuesProducer(state, DATA_CODEC, DATA_EXTENSION, META_CODEC, META_EXTENSION);
}
Lucene 4.5 DocValues format通过下面的策略对四种类型进行编码:
- NUMERIC
- Delta-compressed(增量压缩):表示文档值的整数写入一个16k大小的block。在每个block中,最小的值被编码,每个入口都是最小值的一个增量。所有这些增量都使用位压缩方法。更多信息见下文BlockPackedWriter。
- Table-compressed(表压缩):当不同数值的数量非常小(<256)时,或者在文档值序列中有没有使用gap值,solr会使用一个查找表替代。每一个文档值的入口都被替代为表上的序号,这些序号同样适用位压缩的方法压缩为PackedInts格式。
- GCD-compressed(最大公约数压缩):当所有数字分享同一个除数,最大共同分母(reatest common denominator,GCD) 会被计算出来,并且商会使用Delta-compressed 策略存储起来。
BINARY
- Fixed-width Binary:使用一个固定长度的,很大的拼接起来的位数组。每一个文档值都可以直接用docID * length 得到。
- Variable-width Binary:同样是一个很大的拼接起来的位数组,不过加入每篇文档的结束地址。这些地址从16k大小的块的起始位置被写入,并且每个入口具有平均长度的增量。对每篇文档,与增量之间的偏差(实际-平均)会记录下来。
- Prefix-compressed Binary:值会写入16(字节)大小的chunk中,其中第一个值被完整地记录下来,而其他值分享前缀。Chunk的地址被写入16k大小的block中。从block的起始位置开始写,对每个入口使用平均值作为增量。对每篇文档,与增量之间的偏差(实际-平均)会记录下来。
- Sorted:
- 使用Prefix-compressed Binary压缩法实现一个从序号到重复的term的映射,同时所有文档的序号使用上面出现的Numeric压缩策略
- SortedSet:
- 使用Prefix-compressed Binary压缩法实现一个从序号到重复的term的映射,同时一个序号的列表和所有文档在这个列表上的索引使用上面出现的Numeric压缩策略。
1.1 .dvm和.dvd文件格式
首先来介绍下.dvm的文件格式:
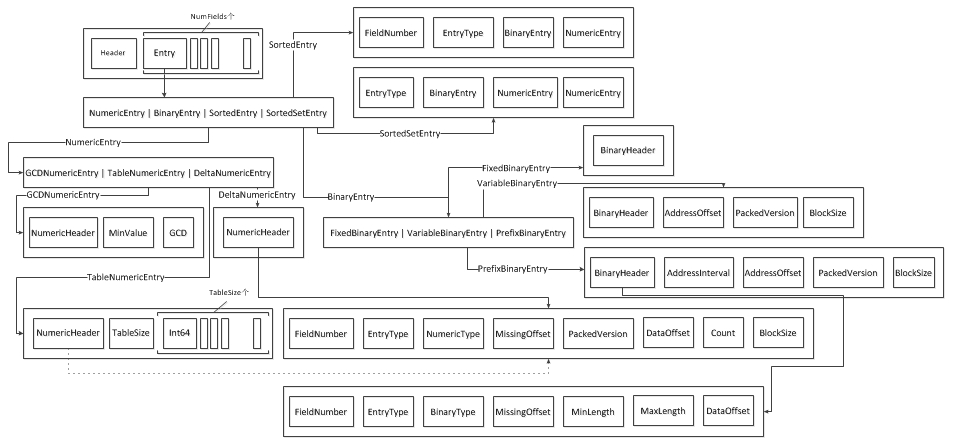
. dvm的文件结构分为好多层:
- 第一层:.dvm 由Header,<Entry>NumFields,Footer
- Header和Footer跟之前相同
- NumFields 个的Entry,Entry为入口。
- 第二层:Entry具有四种类型,NumericEntry | BinaryEntry | SortedEntry | SortedSetEntry
- 第三层:
- NumericEntry:有三种类型GCDNumericEntry | TableNumericEntry | DeltaNumericEntry
- GCDNumericEntry: 包含NumericHeader,MinValue,GCD三部分
- TableNumericEntry:包含NumericHeader,TableSize,Int64TableSize三部分
- DeltaNumericEntry:包含NumericHeader
- BinaryEntry: 有三种类型FixedBinaryEntry | VariableBinaryEntry | PrefixBinaryEntry
- FixedBinaryEntry: 包含BinaryHeader
- VariableBinaryEntry:包含BinaryHeader,AddressOffset,PackedVersion,BlockSize四部分
- PrefixBinaryEntry: 包含BinaryHeader,AddressInterval,AddressOffset,PackedVersion,BlockSize五部分
SortedEntry: 包含FieldNumber,EntryType,BinaryEntry,NumericEntry
SortedSetEntry: 包含EntryType,BinaryEntry,NumericEntry,NumericEntry
- NumericEntry:有三种类型GCDNumericEntry | TableNumericEntry | DeltaNumericEntry
- 第四层:
- NumericHeader: 包含FieldNumber,EntryType,NumericType,MissingOffset,PackedVersion,DataOffset,Count,BlockSize
- FieldNumber: 域的编号,如果为-1 表示最后一个元数据
- EntryType:如果为0 则为NumericEntry,如果为1则为BinaryEntry
- NumericType:Numeric的编码方式
- 0:Delta-compressed(增量压缩): 16K大小的整数组成一个block,每一个block从这个block的最小整数开始增量递增。
- 1:GCD-compressed(最大公约数压缩): 当所有整数具有相同公约数时,商将使用增量压缩进行编码
- 2:Table-compressed(表压缩):当所有不同的数值较小时,使用表压缩方法可以节省空间,在原文档号后面会跟随不同数值的查找表。
- MissingOffset:指向一个位数组,指明了所有有这个域值的文档。如果MissingOffset为-1,则说明没有丢失的值。
- PackedVersion:
- DataOffset:指向.dvd文件中数据起始位置的指针
- Count:
- MinLength:
- BinaryEntry:包含FieldNumber,EntryType,BinaryType,MissingOffset,MinLength,MaxLength,DataOffset。(部分内容同NumericHeade)
- BinaryType: 二进制的存储方式
- 0: fixed-width(固定长度):所有值是固定长度的,可以直接通过乘法获取地址
- 1: variable-width(可变长): 每个值的地址是额外存储的
- 2:prefix-compressed(前缀压缩): 间隔的值的前缀会存储
- MinLength and MaxLength:存储Binary 类型的值的位数组的长度的最小值和最大值。如果这两个值是相等的,那么所有的值都是固定的大小,并且可以通过DataOffset + (docID * length)计算出来。否则,Binary的值是不定长的,并且组合起来的整数型元数据(PackedVersion,BlockSize)用于支持这些地址。
- BinaryType: 二进制的存储方式
- Sorted域包括两个入口:BinaryEntry指向值的元数据,一般的NumericEntry指向document-to-ord (文档到编号)元数据。
- SortedSet包括三个入口: 一个BinaryEntry指向值的元数据,两个NumericEntries 分别对应document-to-ord 索引和有序列表元数据。
- NumericHeader: 包含FieldNumber,EntryType,NumericType,MissingOffset,PackedVersion,DataOffset,Count,BlockSize
.dvd文件格式:
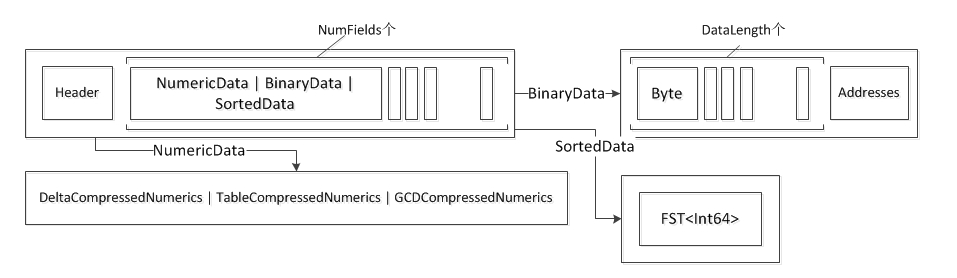
同样.dvd 文件具有好几层结构:
第一层:Header,<NumericData | BinaryData | SortedData>NumFields,Footer 与dvm类似,NumFields个Data(SortedData,BinaryData,NumericData其中一个)
- 第二层:
- NumericData:DeltaCompressedNumerics | TableCompressedNumerics | GCDCompressedNumerics对应上文讲到的Numeric的压缩方式
- BinaryData:ByteDataLength,Addresses
- SortedData:FST<Int64>
- 第三层:
- DeltaCompressedNumerics:BlockPackedInts(blockSize=16k)
- TableCompressedNumerics:PackedInts
- GCDCompressedNumerics: BlockPackedInts(blockSize=16k)
- Addresses:MonotonicBlockPackedInts(blockSize=16k)
- SortedSet入口储存了BinaryData中的序号的列表,使用一个增长的vLong类型的序列,并用差值编码。
1.2 .dvm和.dvd代码实现
前文讲到Lucene45DocValuesFormat分别包含Lucene45DocValuesProducer和Lucene45DocValuesConsumer来实现该文件的读和写,那么本节内容主要以Lucene45DocValuesProducer为例来学习下dvm和dvd。
首先学习下Lucene45DocValuesProducer的初始化:主要作用是读取.dvm文件和.dvd流。其中在读取.dvm文件过程中,Lucene45DocValuesProducer调用了readFields(in, state.fieldInfos)来获取入口信息。
protected Lucene45DocValuesProducer(SegmentReadState state, String dataCodec, String dataExtension, String metaCodec, String metaExtension) throws IOException {
//.dvm文件名
String metaName = IndexFileNames.segmentFileName(state.segmentInfo.name, state.segmentSuffix, metaExtension);
// read in the entries from the metadata file.
//打开.dvm并获取检验和,获取文件流,
ChecksumIndexInput in = state.directory.openChecksumInput(metaName, state.context);
//获取segment的document个数
this.maxDoc = state.segmentInfo.getDocCount();
boolean success = false;
try {
//获取.dvm header
version = CodecUtil.checkHeader(in, metaCodec,
Lucene45DocValuesFormat.VERSION_START,
Lucene45DocValuesFormat.VERSION_CURRENT);
numerics = new HashMap<>();
ords = new HashMap<>();
ordIndexes = new HashMap<>();
binaries = new HashMap<>();
sortedSets = new HashMap<>();
//读取NumFields个<Entry>
readFields(in, state.fieldInfos);
//加入Footer
if (version >= Lucene45DocValuesFormat.VERSION_CHECKSUM) {
CodecUtil.checkFooter(in);
} else {
CodecUtil.checkEOF(in);
}
success = true;
} finally {
if (success) {
IOUtils.close(in);
} else {
IOUtils.closeWhileHandlingException(in);
}
}
success = false;
try {
//.dvd文件名
String dataName = IndexFileNames.segmentFileName(state.segmentInfo.name, state.segmentSuffix, dataExtension);
//打开.dvd文件
data = state.directory.openInput(dataName, state.context);
//获取.dvd header
final int version2 = CodecUtil.checkHeader(data, dataCodec,
Lucene45DocValuesFormat.VERSION_START,
Lucene45DocValuesFormat.VERSION_CURRENT);
if (version != version2) {
throw new CorruptIndexException("Format versions mismatch");
}
success = true;
} finally {
if (!success) {
IOUtils.closeWhileHandlingException(this.data);
}
}
//估算类的大小,也就是估算.dvd流的大小
ramBytesUsed = new AtomicLong(RamUsageEstimator.shallowSizeOfInstance(getClass()));
}
readFields(in, state.fieldInfos)主要是读取EntryType,根据它的值来选择哪种方式来读取后续的Entry信息,
函数中涉及了以下几个方式:
1. Numeric类型readNumericEntry()
2.BinaryEntry类型readBinaryEntry()
3.SortedSetEntry类型readSortedField()
4.SortedSetEntry类型readSortedSetEntry(),同时在该类型下,readFields还分别调用了readSortedSetFieldWithAddresses和readSortedField
private void readFields(IndexInput meta, FieldInfos infos) throws IOException {
//读取Entry的编号,如果编号为-1,表示这是最后一个Entry。
int fieldNumber = meta.readVInt();
while (fieldNumber != -1) {
// check should be: infos.fieldInfo(fieldNumber) != null, which incorporates negative check
// but docvalues updates are currently buggy here (loading extra stuff, etc): LUCENE-5616
if (fieldNumber < 0) {
// trickier to validate more: because we re-use for norms, because we use multiple entries
// for "composite" types like sortedset, etc.
throw new CorruptIndexException("Invalid field number: " + fieldNumber + " (resource=" + meta + ")");
}
//读取EntryType,以此来区分Entry的类型,0表示NUMERICENTRY,1表示BINARYENTRY,2表示SORTEDENTRY,3表示SORTED_SETENTRY
byte type = meta.readByte();
if (type == Lucene45DocValuesFormat.NUMERIC) {
//获取具体的NumericEntry内容,并放入以编号为键,NumericEntry为值的map中
numerics.put(fieldNumber, readNumericEntry(meta));
} else if (type == Lucene45DocValuesFormat.BINARY) {
//获取具体的BinaryEntry内容,并放入以编号为键,BinaryEntry为值的map中
BinaryEntry b = readBinaryEntry(meta);
binaries.put(fieldNumber, b);
} else if (type == Lucene45DocValuesFormat.SORTED) {
//读取SortedEntry
readSortedField(fieldNumber, meta, infos);
} else if (type == Lucene45DocValuesFormat.SORTED_SET) {
//读取SortedSetEntry,并放入以编号为键,SortedSetEntry为值的map中
SortedSetEntry ss = readSortedSetEntry(meta);
sortedSets.put(fieldNumber, ss);
//标准的存储有序的集合是否通过address的间接转换,SORTED_SET_WITH_ADDRESSES是docid->address>ord映射
if (ss.format == SORTED_SET_WITH_ADDRESSES) {
readSortedSetFieldWithAddresses(fieldNumber, meta, infos);
//SORTED_SET_SINGLE_VALUED_SORTED 只存储docid->ord的值
} else if (ss.format == SORTED_SET_SINGLE_VALUED_SORTED) {
if (meta.readVInt() != fieldNumber) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
if (meta.readByte() != Lucene45DocValuesFormat.SORTED) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
readSortedField(fieldNumber, meta, infos);
} else {
throw new AssertionError();
}
} else {
throw new CorruptIndexException("invalid type: " + type + ", resource=" + meta);
}
//读取下一个Entry
fieldNumber = meta.readVInt();
}
}
1. readNumericEntry()
static NumericEntry readNumericEntry(IndexInput meta) throws IOException {
NumericEntry entry = new NumericEntry();
entry.format = meta.readVInt(); //NumericType,Numeric的编码方式
entry.missingOffset = meta.readLong(); //MissingOffset表示该field在哪个document中缺失,如果为-1表示没有document缺失字段
entry.packedIntsVersion = meta.readVInt(); //PackedVersion 打包整数的version
entry.offset = meta.readLong(); //DataOffset 指向.dvd文件中数据起始位置的指针
entry.count = meta.readVLong(); //Count 已写的值的个数
entry.blockSize = meta.readVInt(); //BlockSize 已打包的整数的大小
switch(entry.format) {
case GCD_COMPRESSED: //GCD-compressed(最大公约数压缩)
entry.minValue = meta.readLong(); //MinValue
entry.gcd = meta.readLong(); //GCD
break;
case TABLE_COMPRESSED: //Table-compressed(表压缩)
if (entry.count > Integer.MAX_VALUE) {
throw new CorruptIndexException("Cannot use TABLE_COMPRESSED with more than MAX_VALUE values, input=" + meta);
}
final int uniqueValues = meta.readVInt(); //TableSize
if (uniqueValues > 256) { //TableSize必须小于256
throw new CorruptIndexException("TABLE_COMPRESSED cannot have more than 256 distinct values, input=" + meta);
}
entry.table = new long[uniqueValues]; //TableSize个Long
for (int i = 0; i < uniqueValues; ++i) {
entry.table[i] = meta.readLong();
}
break;
case DELTA_COMPRESSED: //Delta-compressed(增量压缩)
break;
default:
throw new CorruptIndexException("Unknown format: " + entry.format + ", input=" + meta);
}
return entry;
}
2. BinaryEntry()
static BinaryEntry readBinaryEntry(IndexInput meta) throws IOException {
BinaryEntry entry = new BinaryEntry();
entry.format = meta.readVInt(); //BinaryType类型
entry.missingOffset = meta.readLong(); //缺失表示,同NuericEntry
entry.minLength = meta.readVInt(); //存储Binary 类型的值的位数组的长度的最小值和最大值。
//如果这两个值是相等的,那么所有的值都是固定的大小,
//并且可以通过DataOffset + (docID * length)计算出来。
//否则,Binary的值是不定长的
entry.maxLength = meta.readVInt();
entry.count = meta.readVLong();
entry.offset = meta.readLong(); //实际二进制数的偏移
switch(entry.format) {
case BINARY_FIXED_UNCOMPRESSED: //Fixed-width Binary
break;
case BINARY_PREFIX_COMPRESSED: //Variable-width Binary
entry.addressInterval = meta.readVInt();
entry.addressesOffset = meta.readLong();
entry.packedIntsVersion = meta.readVInt();
entry.blockSize = meta.readVInt();
break;
case BINARY_VARIABLE_UNCOMPRESSED: //Prefix-compressed Binary
entry.addressesOffset = meta.readLong();
entry.packedIntsVersion = meta.readVInt();
entry.blockSize = meta.readVInt();
break;
default:
throw new CorruptIndexException("Unknown format: " + entry.format + ", input=" + meta);
}
return entry;
}
3. readSortedSetFieldWithAddresses()
private void readSortedSetFieldWithAddresses(int fieldNumber, IndexInput meta, FieldInfos infos) throws IOException {
// sortedset = binary + numeric (addresses) + ordIndex
if (meta.readVInt() != fieldNumber) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
if (meta.readByte() != Lucene45DocValuesFormat.BINARY) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
BinaryEntry b = readBinaryEntry(meta);
binaries.put(fieldNumber, b);
if (meta.readVInt() != fieldNumber) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
if (meta.readByte() != Lucene45DocValuesFormat.NUMERIC) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
NumericEntry n1 = readNumericEntry(meta);
ords.put(fieldNumber, n1);
if (meta.readVInt() != fieldNumber) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
if (meta.readByte() != Lucene45DocValuesFormat.NUMERIC) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
NumericEntry n2 = readNumericEntry(meta);
ordIndexes.put(fieldNumber, n2);
}
4. readSortedField
private void readSortedField(int fieldNumber, IndexInput meta, FieldInfos infos) throws IOException {
// sorted = binary + numeric
if (meta.readVInt() != fieldNumber) {
throw new CorruptIndexException("sorted entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
if (meta.readByte() != Lucene45DocValuesFormat.BINARY) {
throw new CorruptIndexException("sorted entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
BinaryEntry b = readBinaryEntry(meta);
binaries.put(fieldNumber, b);
if (meta.readVInt() != fieldNumber) {
throw new CorruptIndexException("sorted entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
if (meta.readByte() != Lucene45DocValuesFormat.NUMERIC) {
throw new CorruptIndexException("sorted entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
NumericEntry n = readNumericEntry(meta);
ords.put(fieldNumber, n);
}
上文讲了.dvm文件的读取, 那么接下来学习下怎么对.dvd文件的读取。对.dvd文件的读取首先得获取.dvm的entry,然后根据不同的entrytype选择该类型的方法来获取具体的数据。
1. Numeric类型
LongValues getNumeric(NumericEntry entry) throws IOException {
//clone一份.dvd数据流,使得对clone后的流的操作不影响原始流
final IndexInput data = this.data.clone();
//根据entry的位置偏移,直接将流的指针指向偏移位置
data.seek(entry.offset);
switch (entry.format) {
case DELTA_COMPRESSED:
//如果是差值压缩,使用BlockPackedReader来解析,第i个整数就是BlockPackedReader的第i个值
final BlockPackedReader reader = new BlockPackedReader(data, entry.packedIntsVersion, entry.blockSize, entry.count, true);
return reader;
case GCD_COMPRESSED:
//如果使用公约数压缩,则先获取最小的初始值,则获取公约数,第i个整数就是初始值+公约数*BlockPackedReader第i个值
final long min = entry.minValue;
final long mult = entry.gcd;
final BlockPackedReader quotientReader = new BlockPackedReader(data, entry.packedIntsVersion, entry.blockSize, entry.count, true);
return new LongValues() {
@Override
public long get(long id) {
return min + mult * quotientReader.get(id);
}
};
case TABLE_COMPRESSED:
final long table[] = entry.table;
final int bitsRequired = PackedInts.bitsRequired(table.length - 1);
final PackedInts.Reader ords = PackedInts.getDirectReaderNoHeader(data, PackedInts.Format.PACKED, entry.packedIntsVersion, (int) entry.count, bitsRequired);
return new LongValues() {
@Override
public long get(long id) {
return table[(int) ords.get((int) id)];
}
};
default:
throw new AssertionError();
}
}
这里主要用到了 BlockPackedReader类来实现对数值进行解码。BlockPackedReader的存储格式如下:
1. <BLock>BlockCount 存放BlockCount个BLock
2. BlockCount 是对floor(整数个数/blocksize),即Block的个数
3. Block由<Head,(ints)>组成,真正存储的数值为ints+MinValue
4. Head由<Token,MinValue>,Token的高7位表示bitsPerValue,最低位为1表示MinValue是否为0,如果Token为0,则表示实际值就是minvalue.
所以:BlockPackedReader是按BlockSize大小的Block为单位进行存储的,每一个Block都会一个MinValue(可以为0,即当Token最低位为0),实际存储的数值等于MinValue+int。当只使用BlockPackedReader时就是差值压缩。当使用min(初始值)+GCD(最大公约数)*int的形式就是最大公约数压缩,其中int仍然使用BlockPackedReader。
public BlockPackedReader(IndexInput in, int packedIntsVersion, int blockSize, long valueCount, boolean direct) throws IOException {
this.valueCount = valueCount;
blockShift = checkBlockSize(blockSize, MIN_BLOCK_SIZE, MAX_BLOCK_SIZE);
blockMask = blockSize - 1;
final int numBlocks = numBlocks(valueCount, blockSize);
long[] minValues = null;
subReaders = new PackedInts.Reader[numBlocks];
for (int i = 0; i < numBlocks; ++i) {
final int token = in.readByte() & 0xFF;
final int bitsPerValue = token >>> BPV_SHIFT;
if (bitsPerValue > 64) {
throw new IOException("Corrupted");
}
if ((token & MIN_VALUE_EQUALS_0) == 0) {
if (minValues == null) {
minValues = new long[numBlocks];
}
minValues[i] = zigZagDecode(1L + readVLong(in));
}
if (bitsPerValue == 0) {
subReaders[i] = new PackedInts.NullReader(blockSize);
} else {
final int size = (int) Math.min(blockSize, valueCount - (long) i * blockSize);
if (direct) {
final long pointer = in.getFilePointer();
subReaders[i] = PackedInts.getDirectReaderNoHeader(in, PackedInts.Format.PACKED, packedIntsVersion, size, bitsPerValue);
in.seek(pointer + PackedInts.Format.PACKED.byteCount(packedIntsVersion, size, bitsPerValue));
} else {
subReaders[i] = PackedInts.getReaderNoHeader(in, PackedInts.Format.PACKED, packedIntsVersion, size, bitsPerValue);
}
}
}
this.minValues = minValues;
}
Solr4.8.0源码分析(11)之Lucene的索引文件(4)的更多相关文章
- Solr4.8.0源码分析(12)之Lucene的索引文件(5)
Solr4.8.0源码分析(12)之Lucene的索引文件(5) 1. 存储域数据文件(.fdt和.fdx) Solr4.8.0里面使用的fdt和fdx的格式是lucene4.1的.为了提升压缩比,S ...
- Solr4.8.0源码分析(10)之Lucene的索引文件(3)
Solr4.8.0源码分析(10)之Lucene的索引文件(3) 1. .si文件 .si文件存储了段的元数据,主要涉及SegmentInfoFormat.java和Segmentinfo.java这 ...
- Solr4.8.0源码分析(9)之Lucene的索引文件(2)
Solr4.8.0源码分析(9)之Lucene的索引文件(2) 一. Segments_N文件 一个索引对应一个目录,索引文件都存放在目录里面.Solr的索引文件存放在Solr/Home下的core/ ...
- Solr4.8.0源码分析(8)之Lucene的索引文件(1)
Solr4.8.0源码分析(8)之Lucene的索引文件(1) 题记:最近有幸看到觉先大神的Lucene的博客,感觉自己之前学习的以及工作的太为肤浅,所以决定先跟随觉先大神的博客学习下Lucene的原 ...
- Solr4.8.0源码分析(13)之LuceneCore的索引修复
Solr4.8.0源码分析(13)之LuceneCore的索引修复 题记:今天在公司研究elasticsearch,突然看到一篇博客说elasticsearch具有索引修复功能,顿感好奇,于是点进去看 ...
- Solr4.8.0源码分析(25)之SolrCloud的Split流程
Solr4.8.0源码分析(25)之SolrCloud的Split流程(一) 题记:昨天有位网友问我SolrCloud的split的机制是如何的,这个还真不知道,所以今天抽空去看了Split的原理,大 ...
- Solr4.8.0源码分析(24)之SolrCloud的Recovery策略(五)
Solr4.8.0源码分析(24)之SolrCloud的Recovery策略(五) 题记:关于SolrCloud的Recovery策略已经写了四篇了,这篇应该是系统介绍Recovery策略的最后一篇了 ...
- Solr4.8.0源码分析(23)之SolrCloud的Recovery策略(四)
Solr4.8.0源码分析(23)之SolrCloud的Recovery策略(四) 题记:本来计划的SolrCloud的Recovery策略的文章是3篇的,但是没想到Recovery的内容蛮多的,前面 ...
- Solr4.8.0源码分析(22)之SolrCloud的Recovery策略(三)
Solr4.8.0源码分析(22)之SolrCloud的Recovery策略(三) 本文是SolrCloud的Recovery策略系列的第三篇文章,前面两篇主要介绍了Recovery的总体流程,以及P ...
随机推荐
- eclipse运行内存不足解决办法
选中所要执行的类,鼠标右键移动到Run As选项,接着选择Run Configurations...选项,在弹出的选项卡中选择Arguments,在VM arguments下面的输入框中输入-Xmx1 ...
- Swap[HDU2819]
SwapTime Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submission ...
- SimpleDateFormat线程不安全问题处理
在工作中,通过SimpleDateFormat将字符串类型转为日期类型时,发现有时返回的日期类型出错,调用方法如下: public final class DateUtil { static fina ...
- 利用MyEclipse配置S2SH三大框架篇-Spring配置
1.配置完Struts2后,然后配置Spring 2.单击“MyEclipse->Project Capabilities->Add Spring Capabilities” 3.选择Sp ...
- JVM 调优
JVM内存,由三个部分构成 年轻代+老年代+永久代: 需要调试的是年轻代和老年代 的参数: 先解释几个JVM参数: -XMx : 最大可用内存: -Xms:初始化内存: -xss: 线程栈 的大小: ...
- 全文检索luncence
检索技术基本原理: 最主要的两点是 1.如何创建索引 2.如何查询. 分析需求: 好几篇文档,从这些文档找关键词,一种方式是顺序一个个遍历,加入这些文档量很多,就花费太长时间了,第二种是建立索引, ...
- Android MVP框架模式
结合前一篇MVC框架模式 为了更好地细分视图(View)与模型(Model)的功能,让View专注于处理数据的可视化以及与用户的交互,同时让Model只关系数据的处理,基于MVC概念的MVP(Mode ...
- BAT染指影视制作 欲全面撬开互联网粉丝经济
预測: 或靠"用户"模式盈利 除了内容制作,电影发行也在遭遇互联网模式的冲击. 除了给片方支付高额保底以外,随着市场竞争激烈.新进入者都在争夺好片的发行权. 业内预測.再往后,发行 ...
- python 学习笔记 copy
浅copy >>> a=[1,2,3,[4,5,6]]>>> a[1, 2, 3, [4, 5, 6]]>>> a[3].append(7)> ...
- QT的信号与槽机制介绍
信号与槽作为QT的核心机制在QT编程中有着广泛的应用,本文介绍了信号与槽的一些基本概念.元对象工具以及在实际使用过程中应注意的一些问题. QT是一个跨平台的C++ GUI应用构架,它提供了丰富的窗 ...