大数据学习之hadoop伪分布式集群安装(一)公众号undefined110
hadoop的基本概念:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
准备搭建环境:
1.选择合适的操作系统(linux)和语言(java)。
2.准备虚拟机:我的电脑是windows系统还要玩游戏,当然要准备一个虚拟机。虚拟机选择VMware Workstation。首先创建新的虚拟机,分配好内存和硬盘,网络适配器调为VMNET8模式配置,方便以后对网络的使用。
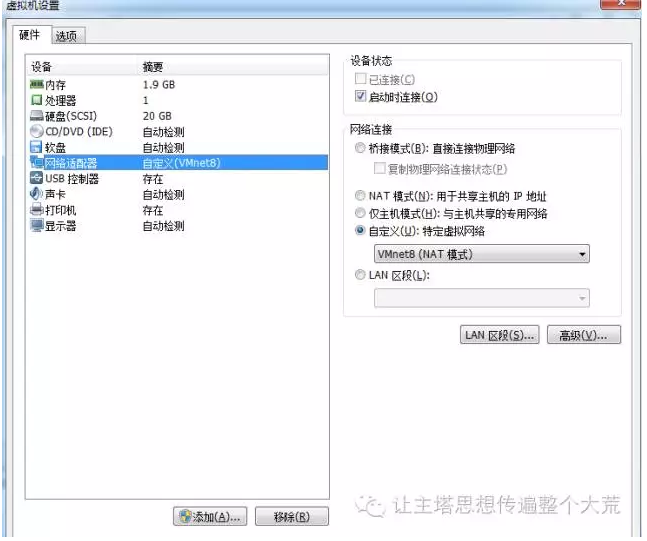
3.安装操作系统:首先得要安装linux系统吧,因为linux系统有太多可选择了,例如最著名的RedHat咱中国人开发的红旗Linux,Ubuntu、Fedora、CentOS等等,因为学习,一切为了有更多资料,安装CentOS6.4这个版本的系统。
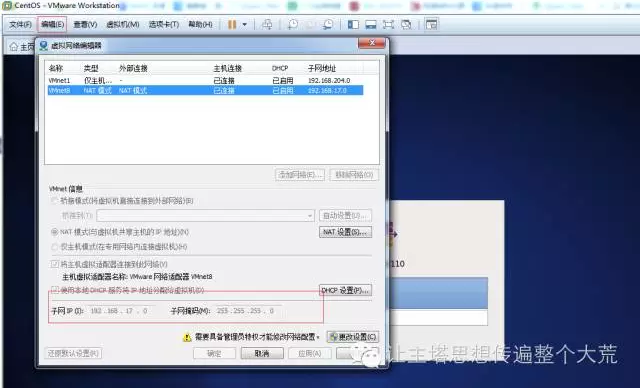
4.设置网络:点击虚拟机的编辑-虚拟网络编辑器,设置子网IP和子网掩码。子网IP:
192.168.17.0 子网掩码:255.255.255.0
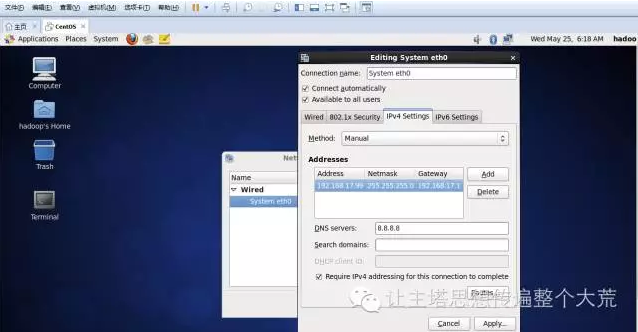
5.在系统中不要用root账号,权限太大,不安全,在实际生产环境中也不会用到root账号。创建名字为hadoop的用户,登录进去。设置网络使用和虚拟机同一子网上的IP,便于本地与虚拟机的交互通信。
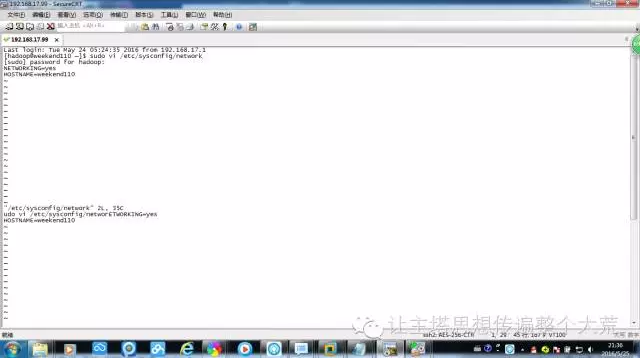
6.使用Securecrt连接上虚拟机,方便在本地直接通过命令操作虚拟机。用sudo vi /etc/sysc onfig/network打开系统文件修改主机名和IP的映射关系,保存后source /etc/profile刷新配置立即生效。关闭防火墙,因为在内网环境而且学习使用,对每个端口进行配置太麻烦,
#查看防火墙状态 service iptables status
#关闭防火墙 service iptables stop
#查看防火墙开机启动状态 chkconfig iptables --list
#关闭防火墙开机启动 chkconfig iptables off
给hadoop赋予root账号权限
重启linux系统
7.使用SecureFx将要安装的软件包传到虚拟机,连接上虚拟机后,把软件包直接拖到hadoop文件夹下
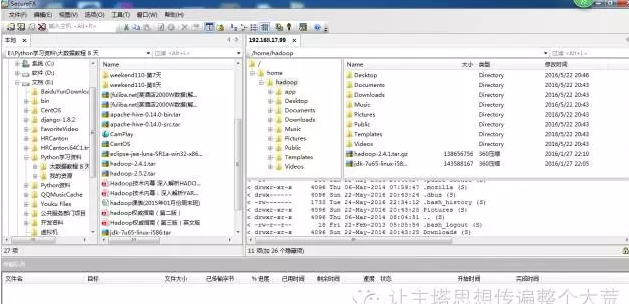
8.创建一个app文件夹将解压的文件都统一放在这里(怎么创建文件夹,解压需要学习Linux基本操作,这里不多说)。
9.方便每次直接使用,需要配置环境变量。
①配置java的jdk环境变量:命令vim /etc/profile
#在文件最后添加
export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585
export PATH=$PATH:$JAVA_HOME/bin
#刷新配置
source /etc/profile
②配置hadoop,伪分布式需要修改5个配置文件,查找到这五个文件.
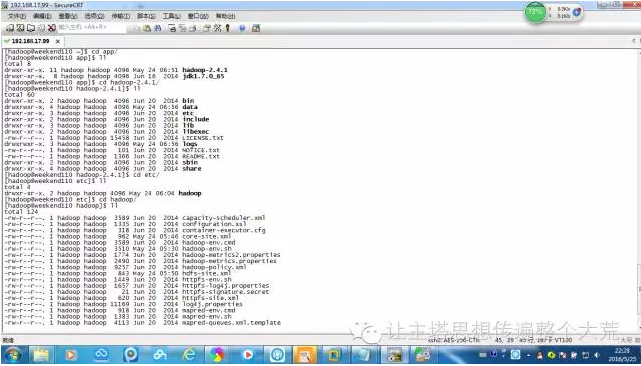
1:sudo vim hadoop-env.sh
#第27行
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
2:sudo vim core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://weekend110:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.4.1/data</value>
</property>
3:sudo vim hdfs-site.xml
<!-- 指定HDFS副本的数量 -->虚拟机中配置一个就行了,多了浪费
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4: 将mapred-site.xml.template重命名 为mapred-site.xml
(mv mapred-site.xml.template mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5: sudo vi yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>weekend-1206-01</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
③ 将hadoop添加到环境变量
命令:sudo vim /etc/proflie
Shift+G直接跳到最后添加如下配置信息
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
刷新 source /etc/profile
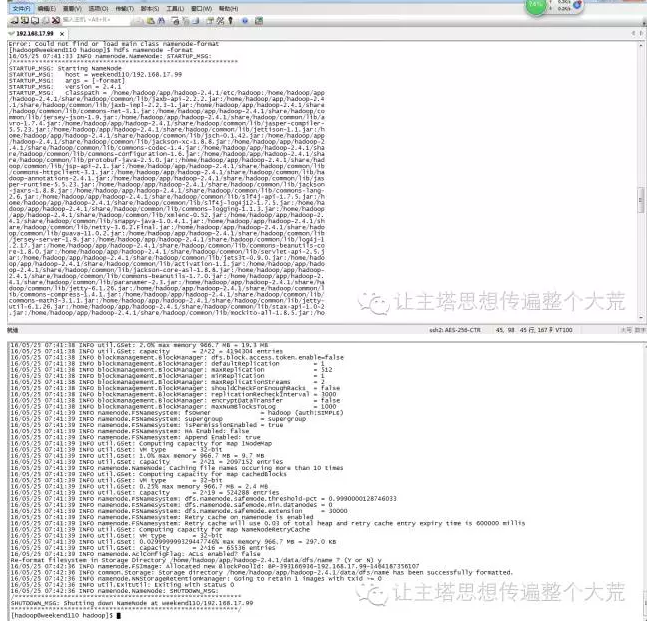
10: 格式化namenode(是对namenode进行初始化,像U盘一样第一次使用需要格式化)
hdfs namenode -format (hadoop namenode -format)
11:启动hadoop
先启动HDFS
start-dfs.sh
再启动YARN
start-yarn.sh
12.执行命名: jps验证是否启动成功。以为本机原来已经启动故有标红信息。最后看到hadoop启动成功。

扫下这个二维码一起学习hadoop:

大数据学习之hadoop伪分布式集群安装(一)公众号undefined110的更多相关文章
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop伪分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 设置静态IP地址 Hadoop伪分布式集群搭建: 为普通用户添加su ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
随机推荐
- Fire Net(深搜 和一前不一样的深搜)
/* http://acm.tzc.edu.cn/acmhome/problemdetail.do?&method=showdetail&id=1162 本题妙处: 用一个数对行取商是 ...
- [Locked] Longest Substring with At Most Two Distinct Characters
Longest Substring with At Most Two Distinct Characters Given a string, find the length of the longes ...
- poj3122
题目大意:馅饼(看起来像是一个简单点的题目啊,嘎嘎,希望是的吧) 我的生日即将来临按照习惯我将准备馅饼,不是一个馅饼,我有N块馅饼,有各种各样的味道和尺寸,当我的朋友来参加我的聚会平且他们都能得到一块 ...
- C语言学习_从VC++6.0开始
前言: C语言是一门博大精深的语言,C语言往往是程序员以及所有软件行业从业者的第一门编程语言. 编程环境: 对于初学者来说,我一开始学习C语言,其实是用的turboc 2.0版本,这个很有历史感,但是 ...
- 关于lucene的IndexSearcher单实例,对于索引的实时搜索
Lucene版本:3.0 一般情况下,lucene的IndexSearcher都要写成单实例,因为每次创建IndexSearcher对象的时候,它都需要把索引文件加载进来,如果访问量比较大,而索引也比 ...
- Structual设计--Flyweight模式
1.意图 运用共享技术有效地支持大量细粒度的对象. 2.别名 无 3.动机 有些应用程序得意于在其整个设计过程中採用对象技术,但简单化的实现代价极大.如我们在使用word的时候.假设设置正文字体为:t ...
- 为什么app都是异步编程
对本文题目首先需要了解一下什么是异步编程,异步编程即多线程编程. 多线程是一个比较轻量级的方法来实现单个应用程序内多个代码执行路径. 在具体理解多线程之前先看一个都理解的例子: 在系统级别内,程序并排 ...
- Android(java)学习笔记232:Android进程间通讯(IPC)之AIDL
一.IPC inter process communication 进程间通讯 二.AIDL android interface defination language 安卓接口定义语言 满 ...
- python运算符使用规律
#conding=utf-8 #优先级使用规律#1.一般情况下是左右结合print 4+6+5*6+6 #2.出现赋值的时候一般是右结合a=8+91print a #优先级记忆口诀'''函数寻址下标1 ...
- 原生js方法document.getElementsByClassName在ie8及其以下的兼容性问题
document.getElementsByClassName在ie8及其以下浏览器的兼容性问题,在ie8及其以下浏览器中不能使用,针对这个问题,下面给出详细的解决方法,感兴趣的朋友可以参考下 ...