Azkaban_Oozie_action
http://azkaban.github.io/azkaban/docs/2.5/
There is no reason why MySQL was chosen except that it is a widely used DB. We are looking to implement compatibility with other DB's, although the search requirement on historically running jobs benefits from a relational data store.
【solve the problem of Hadoop job dependencies】
Azkaban was implemented at LinkedIn to solve the problem of Hadoop job dependencies. We had jobs that needed to run in order, from ETL jobs to data analytics products.
Initially a single server solution, with the increased number of Hadoop users over the years, Azkaban has evolved to be a more robust solution.
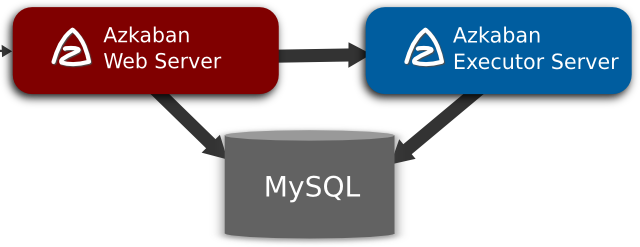
Azkaban consists of 3 key components:
- Relational Database (MySQL)
- AzkabanWebServer
- AzkabanExecutorServer
Relational Database (MySQL)
Azkaban uses MySQL to store much of its state. Both the AzkabanWebServer and the AzkabanExecutorServer access the DB.
How does AzkabanWebServer use the DB?
The web server uses the db for the following reasons:
- Project Management - The projects, the permissions on the projects as well as the uploaded files.
- Executing Flow State - Keep track of executing flows and which Executor is running them.
- Previous Flow/Jobs - Search through previous executions of jobs and flows as well as access their log files.
- Scheduler - Keeps the state of the scheduled jobs.
- SLA - Keeps all the sla rules
How does the AzkabanExecutorServer use the DB?
The executor server uses the db for the following reasons:
- Access the project - Retrieves project files from the db.
- Executing Flows/Jobs - Retrieves and updates data for flows and that are executing
- Logs - Stores the output logs for jobs and flows into the db.
- Interflow dependency - If a flow is running on a different executor, it will take state from the DB.
There is no reason why MySQL was chosen except that it is a widely used DB. We are looking to implement compatibility with other DB's, although the search requirement on historically running jobs benefits from a relational data store.
AzkabanWebServer
The AzkabanWebServer is the main manager to all of Azkaban. It handles project management, authentication, scheduler, and monitoring of executions. It also serves as the web user interface.
Using Azkaban is easy. Azkaban uses *.job key-value property files to define individual tasks in a work flow, and the _dependencies_ property to define the dependency chain of the jobs. These job files and associated code can be archived into a *.zip and uploaded through the web server through the Azkaban UI or through curl.
AzkabanExecutorServer
Previous versions of Azkaban had both the AzkabanWebServer and the AzkabanExecutorServer features in a single server. The Executor has since been separated into its own server. There were several reasons for splitting these services: we will soon be able to scale the number of executions and fall back on operating Executors if one fails. Also, we are able to roll our upgrades of Azkaban with minimal impact on the users. As Azkaban's usage grew, we found that upgrading Azkaban became increasingly more difficult as all times of the day became 'peak'.
【 no cyclical dependencies detected】
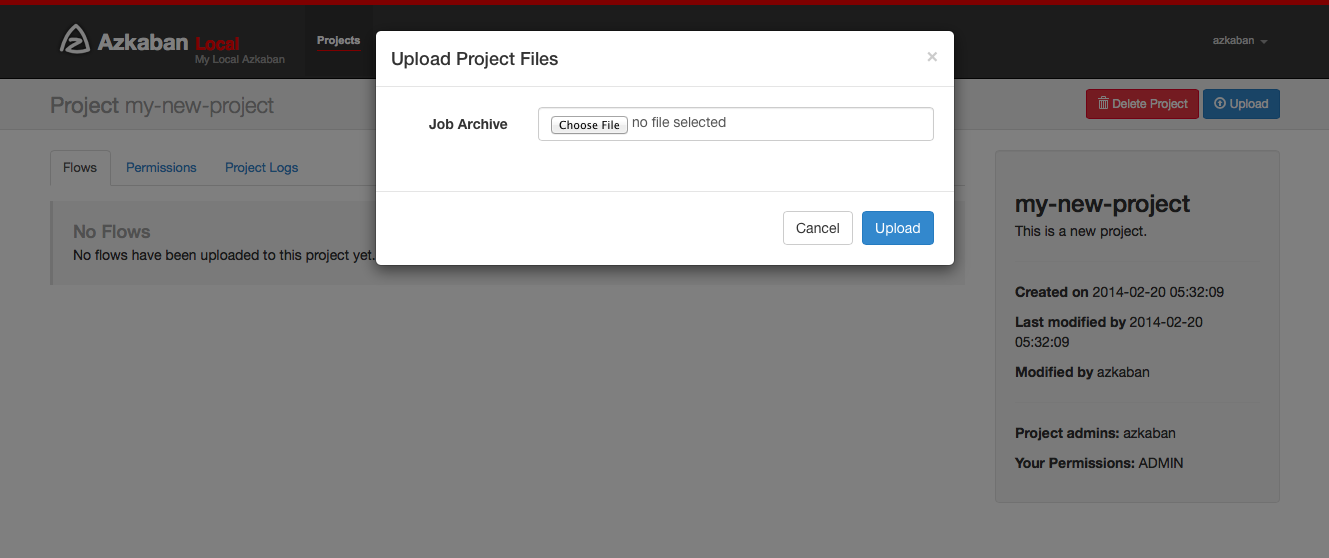
Select the archive file of your workflow files that you want to upload. Currently Azkaban only supports *.zip files. The zip should contain the *.job files and any files needed to run your jobs. Job names must be unique in a project.
Azkaban will validate the contents of the zip to make sure that dependencies are met and that there's no cyclical dependencies detected. If it finds any invalid flows, the upload will fail.
Uploads overwrite all files in the project. Any changes made to jobs will be wiped out after a new zip file is uploaded.
After a successful upload, you should see all of your flows listed on the screen.
http://oozie.apache.org/
Apache Oozie Workflow Scheduler for Hadoop
Overview
Oozie is a workflow scheduler system to manage Apache Hadoop jobs.
Oozie Workflow jobs are Directed Acyclical Graphs (DAGs) of actions.
Oozie Coordinator jobs are recurrent Oozie Workflow jobs triggered by time (frequency) and data availability.
Oozie is integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs out of the box (such as Java map-reduce, Streaming map-reduce, Pig, Hive, Sqoop and Distcp) as well as system specific jobs (such as Java programs and shell scripts).
Oozie is a scalable, reliable and extensible system.
Azkaban_Oozie_action的更多相关文章
随机推荐
- NULL和唯一约束UNIQUE的对应关系
NULL和唯一约束UNIQUE的对应关系 在数据库中,NULL表示列值为空.唯一约束UNIQUE规定指定列的值必须是唯一的,值和值之间都不能相同.这个时候,就出现一个问题,NULL和NULL算是相 ...
- Codeforces 583 DIV2 Robot's Task 贪心
原题链接:http://codeforces.com/problemset/problem/583/B 题意: 就..要打开一个电脑,必须至少先打开其他若干电脑,每次转向有个花费,让你设计一个序列,使 ...
- 轻量i3wm配置使用笔记 -- 主题切换器(j4-make-config)
快速切换主题 j4-make-config介绍: j4-make-config脚本可以方便地在几组"主题"之间切换,还可以根据当前工作的环境,轻松地从几个不同的配置部分组合一个完整 ...
- Jenkins内存溢出的处理方法
参考:http://openwares.net/java/jenkens_deploy_to_tomcat_error_of_outofmemoryerror.html上的说明,有如下解释: -Xms ...
- Scut游戏服务器引擎6.1.5.6发布,直接可运行,支持热更新
1. 增加exe版(console),web版本(IIS)的游戏服宿主程序 2. 增加Model支持脚本化,实现不停服更新 3. 增加Language支持脚本化 4. 修改Sns与Pay Center ...
- IDEA使用Maven打包时如何去掉测试阶段
如图
- 2017.2.12 开涛shiro教程-第八章-拦截器机制
原博客地址:http://jinnianshilongnian.iteye.com/blog/2018398 根据下载的pdf学习. 1.拦截器介绍 下图是shiro拦截器的基础类图: 1.Namea ...
- winform程序公布后,client下载报错“您的 Web 浏览器设置不同意执行未签名的应用程序”
如题 在winserver2008服务器上操作会报错.解决的方法: IE→Internet选项→安全→可信网站,加入信任公布的IP地址
- Git 学习之--安装配置GitHub
楼主今天学习了一下Git的使用,而且Androdi studio 下加入了Git插件,成功提交项目到自己Github个人主页 watermark/2/text/aHR0cDovL2Jsb2cuY3Nk ...
- vs:如何添加.dll文件
Newtonsoft.Json.dll 一个第三方的json序列化和反序列化dll,转换成json供页面使用,页面json数据转换成对象,供.net使用 Mysql.Data.dll mysql数 ...