Azkaban_Oozie_action
http://azkaban.github.io/azkaban/docs/2.5/
There is no reason why MySQL was chosen except that it is a widely used DB. We are looking to implement compatibility with other DB's, although the search requirement on historically running jobs benefits from a relational data store.
【solve the problem of Hadoop job dependencies】
Azkaban was implemented at LinkedIn to solve the problem of Hadoop job dependencies. We had jobs that needed to run in order, from ETL jobs to data analytics products.
Initially a single server solution, with the increased number of Hadoop users over the years, Azkaban has evolved to be a more robust solution.
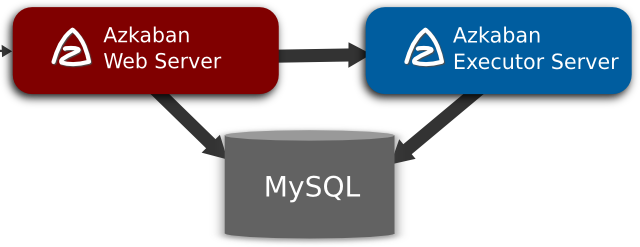
Azkaban consists of 3 key components:
- Relational Database (MySQL)
- AzkabanWebServer
- AzkabanExecutorServer
Relational Database (MySQL)
Azkaban uses MySQL to store much of its state. Both the AzkabanWebServer and the AzkabanExecutorServer access the DB.
How does AzkabanWebServer use the DB?
The web server uses the db for the following reasons:
- Project Management - The projects, the permissions on the projects as well as the uploaded files.
- Executing Flow State - Keep track of executing flows and which Executor is running them.
- Previous Flow/Jobs - Search through previous executions of jobs and flows as well as access their log files.
- Scheduler - Keeps the state of the scheduled jobs.
- SLA - Keeps all the sla rules
How does the AzkabanExecutorServer use the DB?
The executor server uses the db for the following reasons:
- Access the project - Retrieves project files from the db.
- Executing Flows/Jobs - Retrieves and updates data for flows and that are executing
- Logs - Stores the output logs for jobs and flows into the db.
- Interflow dependency - If a flow is running on a different executor, it will take state from the DB.
There is no reason why MySQL was chosen except that it is a widely used DB. We are looking to implement compatibility with other DB's, although the search requirement on historically running jobs benefits from a relational data store.
AzkabanWebServer
The AzkabanWebServer is the main manager to all of Azkaban. It handles project management, authentication, scheduler, and monitoring of executions. It also serves as the web user interface.
Using Azkaban is easy. Azkaban uses *.job key-value property files to define individual tasks in a work flow, and the _dependencies_ property to define the dependency chain of the jobs. These job files and associated code can be archived into a *.zip and uploaded through the web server through the Azkaban UI or through curl.
AzkabanExecutorServer
Previous versions of Azkaban had both the AzkabanWebServer and the AzkabanExecutorServer features in a single server. The Executor has since been separated into its own server. There were several reasons for splitting these services: we will soon be able to scale the number of executions and fall back on operating Executors if one fails. Also, we are able to roll our upgrades of Azkaban with minimal impact on the users. As Azkaban's usage grew, we found that upgrading Azkaban became increasingly more difficult as all times of the day became 'peak'.
【 no cyclical dependencies detected】
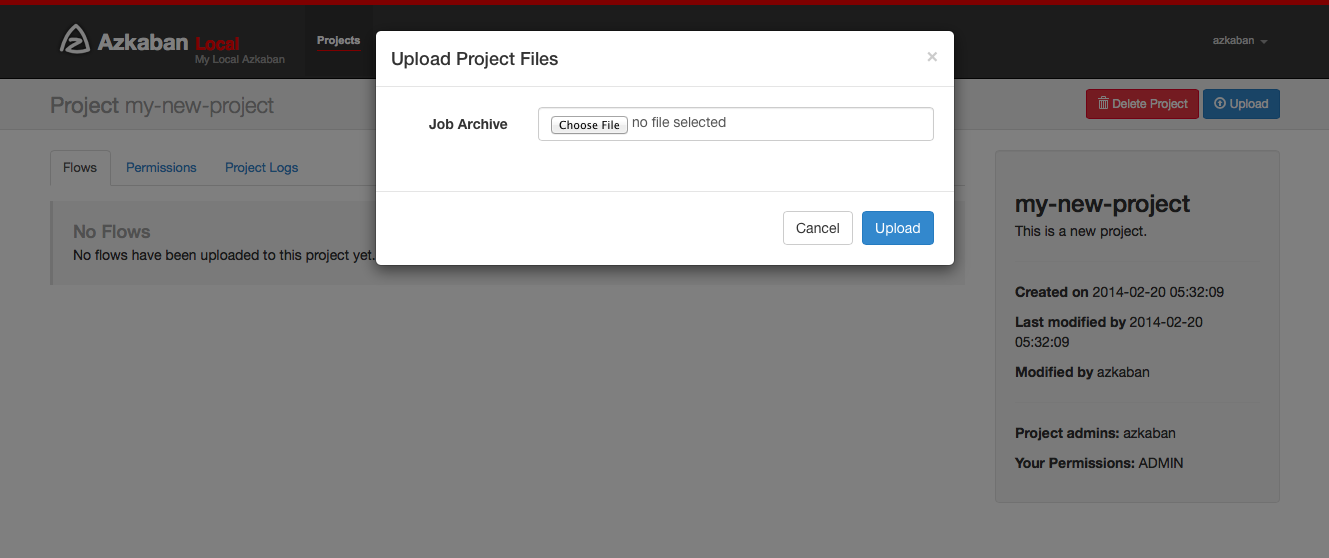
Select the archive file of your workflow files that you want to upload. Currently Azkaban only supports *.zip files. The zip should contain the *.job files and any files needed to run your jobs. Job names must be unique in a project.
Azkaban will validate the contents of the zip to make sure that dependencies are met and that there's no cyclical dependencies detected. If it finds any invalid flows, the upload will fail.
Uploads overwrite all files in the project. Any changes made to jobs will be wiped out after a new zip file is uploaded.
After a successful upload, you should see all of your flows listed on the screen.
http://oozie.apache.org/
Apache Oozie Workflow Scheduler for Hadoop
Overview
Oozie is a workflow scheduler system to manage Apache Hadoop jobs.
Oozie Workflow jobs are Directed Acyclical Graphs (DAGs) of actions.
Oozie Coordinator jobs are recurrent Oozie Workflow jobs triggered by time (frequency) and data availability.
Oozie is integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs out of the box (such as Java map-reduce, Streaming map-reduce, Pig, Hive, Sqoop and Distcp) as well as system specific jobs (such as Java programs and shell scripts).
Oozie is a scalable, reliable and extensible system.
Azkaban_Oozie_action的更多相关文章
随机推荐
- 基于VUE开发项目
前言 最近由于公司需要,需要写一个相对来说比较大型的后台管理系统.为了保证管理系统操作体验较为舒适并且项目后期益于维护,最后决定基于VUE全家桶来开发一个高度组件化的单页SPA应用. 技术选型 vue ...
- 【Maven】3.使用IntelliJ IDEA 使用本地搭建的maven私服,而不是使用默认的maven设置
安装Idea的教程:http://www.cnblogs.com/sxdcgaq8080/p/7641379.html 搭建maven私服的教程:http://www.cnblogs.com/sxdc ...
- mac python 切换系统默认版本
1 找到所安装python路径/usr/local/Cellar/python/2.7.13/bin2 vim ~/.bash_profile 3 添加如下代码: PATH="/usr/lo ...
- VS2010 MFC中 创建文件夹及文件判空的方法
1. MFC中 创建文件夹的方法如下: CString strFolderPath = "./Output"; //判断路径是否存在 if(!PathIsDirectory(str ...
- hdu 5381 The sum of gcd(线段树+gcd)
题目链接:hdu 5381 The sum of gcd 将查询离线处理,依照r排序,然后从左向右处理每一个A[i],碰到查询时处理.用线段树维护.每一个节点表示从[l,i]中以l为起始的区间gcd总 ...
- Activity 事件以及如何得到新打开Activity关闭后返回的数据
1: package com.example.activity_basic; 2: 3: import android.os.Bundle; 4: import android.app.Activ ...
- 缷载vs2015后项目不能加载问题
当加载项目时出现MSBuildToolsPath is not specified for the ToolsVersion "14.0" defined at "HKE ...
- robotframework安装appium
安装: Appium-Python-Client,在运行的cmd下输入:pip install Appium-python-Client 安装:robotframework-appiumlibrary ...
- 转 FreeBSD 安装JDK
cd /usr/ports/java/openjdk6make install clean 默认什么都不用选,因为我们配置的是运行环境, 中间编译过程好久... 偷懒的干脆就直接安装/usr/port ...
- C# 请求Web Api 接口,返回的json数据直接反序列化为实体类
须要的引用的dll类: Newtonsoft.Json.dll.System.Net.Http.dll.System.Net.Http.Formatting.dll Web Api接口为GET形式: ...