爬虫:网页里元素的xpath结构,scrapy不一定就找的到
这种情况原因是html界面关联的js文件可能会动态修改DOM结构,这样浏览器完成了动态修改DOM,在 浏览器上看到的DOM结构,就和后台抓到的DOM结构不通
举例:新浪微博发的微博,在浏览器通过firebug的插件FirePath可以很容易计算出xpath

通过Firefinder可以查看xpath的匹配情况
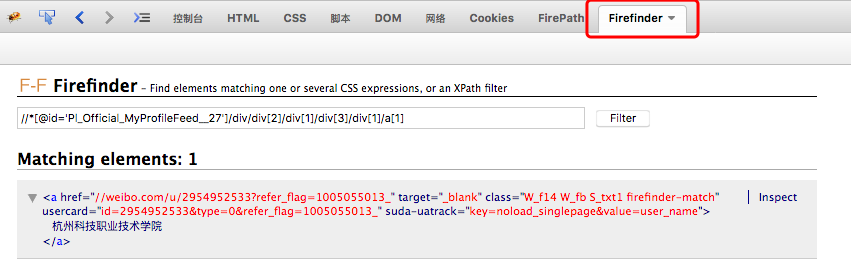
但是查看页面的源代码,可以发现,微博的内容都是包含在js里的FM.view里的,这些会被js动态生成DOM,但是抓取返回的内容都是下面这些内容,是还没有生成DOM的

爬虫:网页里元素的xpath结构,scrapy不一定就找的到的更多相关文章
- 爬虫——网页解析利器--re & xpath
正则解析模块re re模块使用流程 方法一 r_list=re.findall('正则表达式',html,re.S) 方法二 创建正则编译对象 pattern = re.compile('正则表达式 ...
- python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接 现在我再新建个爬虫文件,名称设置为crawler2 做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrap ...
- Python 网络爬虫 008 (编程) 通过ID索引号遍历目标网页里链接的所有网页
通过 ID索引号 遍历目标网页里链接的所有网页 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyChar ...
- 【XPath Helper:chrome爬虫网页解析工具 Chrome插件】XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插件网
[XPath Helper:chrome爬虫网页解析工具 Chrome插件]XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插 ...
- 页面元素定位 XPath 简介
页面元素定位 XPath 简介 本文所说的 Xpath 是用于 Selenium 自动化测试所使用到的,是针对XHTML网页而言的一种页面元素的定位表示法. XPath 背景 XPath即为XML路径 ...
- 爬虫写法进阶:普通函数--->函数类--->Scrapy框架
本文转载自以下网站: 从 Class 类到 Scrapy https://www.makcyun.top/web_scraping_withpython12.html 普通函数爬虫: https:// ...
- 小白学 Python 爬虫(20):Xpath 进阶
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- selenium之元素定位-xpath
被测试网页的HTML代码 <html> <body> <div id="div1" style="text-align:center&quo ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
随机推荐
- 04 JVM是如何执行方法调用的(上)
重载和重写 重载:同一个类中定义名字相同的方法,但是参数类型或者参数个数必须不同. 重载的方法在编译过程中就可完成识别.具体到每一个方法的调用,Java 编译器会根据所传入参数的生命类型来选取重载方法 ...
- 菜鸟之路——git学习及GitHub的使用
首先,感谢廖雪峰老师的git教程 https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000 ...
- [错误解决]paramiko.ssh_exception.SSHException: Error reading SSH protocol banner 设置
报错信息 上午的时候数据组的同事跟我说有几个程序报错,经过查看log发现找到报错信息: paramiko.ssh_exception.SSHException: Error reading SSH p ...
- Spring Cloud Eureka简单入门
步骤: 1.创建父工程 2.创建EurekaServer工程 3.创建EurekaClient工程 父工程pom.xml <?xml version="1.0" encodi ...
- 移动端布局rem em
1.概念 em作为font-size的单位时,其代表父元素的字体大小,em作为其他属性单位时,代表自身字体大小 rem作用于非根元素时,相对于根元素字体大小:rem作用于根元素字体大小时,相对于其出初 ...
- webpack & async await
webpack & async await ES 7 // async function f() { // return 1; // } const f = async () => { ...
- iOS---Objective-C: +load vs +initialize
在 NSObject 类中有两个非常特殊的类方法 +load 和 +initialize ,用于类的初始化.这两个看似非常简单的类方法在许多方面会让人感到困惑,比如: 子类.父类.分类中的相应方法什么 ...
- Puppet单机实战之Nginx代理Tomcat
author:JevonWei 版权声明:原创作品 blog:http://119.23.52.191/ --- 构建实战之Nginx代理Tomcat [root@node1 modules]# mk ...
- Arcengine 基本操作(待更新)
/// <summary> /// 删除fieldName属性值为1的弧段 /// </summary> /// <param name="fieldName& ...
- Python 读取 pkl文件
使用python 的cPickle 库中的load函数,可以读取pkl文件的内容 import cPickle as pickle fr = open('mnist.pkl') #open的参数是pk ...