python for data analysis chapter1~2
Q1:numpy与series的区别:index
Tab补全(任意路径Tab)
内省(函数:?显示文档字符串,??显示源代码;结合通配符:np.* load *?)
%load .py
ctrl-c(强行中断)
%timeit(执行时间)%debug? %pwd
%matplotlib inline(否则你创建的图可能不会出现)
单行注释#
多行注释,多行字符串‘’‘ ’‘’
Q2:赋值,浅拷贝和深拷贝
 1、赋值:简单地拷贝对象的引用,两个对象的id相同。
1、赋值:简单地拷贝对象的引用,两个对象的id相同。
2、浅拷贝:创建一个新的组合对象,这个新对象与原对象共享内存中的子对象。
3、深拷贝:创建一个新的组合对象,同时递归地拷贝所有子对象,新的组合对象与原对象没有任何关联。虽然实际上会共享不可变的子对象,但不影响它们的相互独立性。
is/is not(检查两个引用是否指向同一个对象)
Q4:is和==
只有数值型和字符串型,并且在通用对象池中的情况下,a is b才为True,否则当a和b是int,str,tuple,list,dict或set型时,a is b均为False。
Q3:可迭代对象,迭代器,生成器
 字符串是不可变的序列
字符串是不可变的序列
Q5:.replace()和修改有什么区别
不改变原str内容

字符串格式化:'{0:.2f} {1:s} are worth US${2:d}'.format(4.5560,'Argentine Pesos',1)
val.encode('utf-8') val.decode('utf-8')
Q6:为什么有的要()有的不要
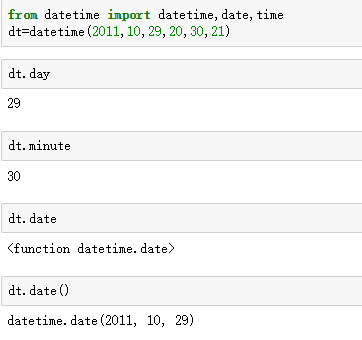
.day is not a method, you do not need to call it.
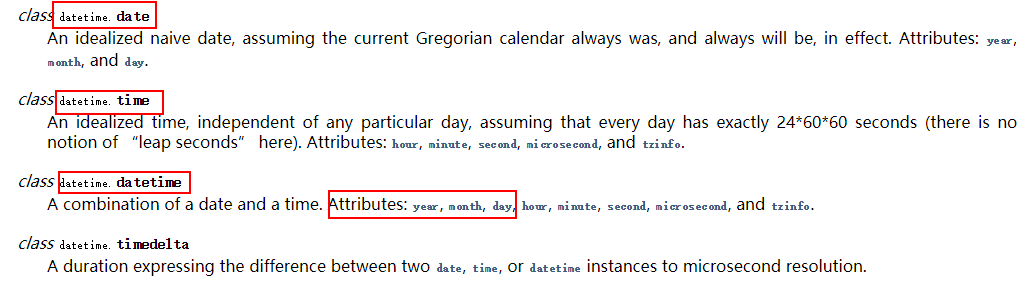
 datetime(2019,2,26,20,30,21).strftime('%m/%d/%Y %H:%M'):将datetime转换为字符串
datetime(2019,2,26,20,30,21).strftime('%m/%d/%Y %H:%M'):将datetime转换为字符串
datetime.strptime('20091031','%Y%m%d'):将字符串转换为datetime
 如果某个条件为True则后面的elif和else代码怪则不会执行
如果某个条件为True则后面的elif和else代码怪则不会执行
continue:跳过continue条件值进入下一次循环
break:到达条件值break结束循环(只结束最内层for循环,外层for循环继续运行)
while条件符合
pass
三元表达式:value=true-expr if condition else false-expr
python for data analysis chapter1~2的更多相关文章
- 数据分析---《Python for Data Analysis》学习笔记【04】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
- 数据分析---《Python for Data Analysis》学习笔记【03】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
- 数据分析---《Python for Data Analysis》学习笔记【02】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
- 数据分析---《Python for Data Analysis》学习笔记【01】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
- 《python for data analysis》第十章,时间序列
< python for data analysis >一书的第十章例程, 主要介绍时间序列(time series)数据的处理.label:1. datetime object.time ...
- 《python for data analysis》第九章,数据聚合与分组运算
# -*- coding:utf-8 -*-# <python for data analysis>第九章# 数据聚合与分组运算import pandas as pdimport nump ...
- 《python for data analysis》第七章,数据规整化
<利用Python进行数据分析>第七章的代码. # -*- coding:utf-8 -*-# <python for data analysis>第七章, 数据规整化 imp ...
- 《python for data analysis》第五章,pandas的基本使用
<利用python进行数据分析>一书的第五章源码与读书笔记 直接上代码 # -*- coding:utf-8 -*-# <python for data analysis>第五 ...
- 《python for data analysis》第四章,numpy的基本使用
<利用python进行数据分析>第四章的程序,介绍了numpy的基本使用方法.(第三章为Ipython的基本使用) 科学计算.常用函数.数组处理.线性代数运算.随机模块…… # -*- c ...
随机推荐
- ThreadLocal(关于struts2的ThreadLocal,实际上Jdk1.2就有了)
ThreadLocal是通过在不同线程中操作变量的副本,来达到线程安全的目的,是用空间资源换时间资源的方式.今天在看struts2源码的时候,发现ActionContext中,就持有一个静态的Thre ...
- 牛客NOIP提高组(二)题解
心路历程 预计得分:100 + 40 + 30 = 170 实际得分:100 + 30 + 0 = 130 T2有一个部分分的数组没开够RE了. T3好像是思路有点小问题.. 思路没问题,实现的时候一 ...
- SpringBoot:异步开发之异步调用
前言 除了异步请求,一般上我们用的比较多的应该是异步调用.通常在开发过程中,会遇到一个方法是和实际业务无关的,没有紧密性的.比如记录日志信息等业务.这个时候正常就是启一个新线程去做一些业务处理,让主线 ...
- python+selenium之多表单切换
在Web应用中经常会遇到fram/iframe表单嵌套页面的应用,WebDriver只能在一个页面上对元素识别与定位,对于fram/iframe表单内嵌套页面上的元素无法直接定位.这是需要通过swit ...
- Installing Apache, PHP, and MySQL on Mac OS X
I have installed Apache, PHP, and MySQL on Mac OS X since Leopard. Each time doing so by hand. Each ...
- UVA 12901 Refraction 折射 (物理)
一道物理题,解个2次方程就行了... 求h最小的情况对应如下图所示 做法不唯一,我想避免精度损失所以在化简的时候尽可能地去避免sqrt和浮点数乘除. 似乎精度要求很低,直接用角度算也可以 #inclu ...
- 手写IOC框架
1.IOC框架的设计思路 ① 哪些类需要我们的容器进行管理 ②完成对象的别名和对应实例的映射装配 ③完成运行期对象所需要的依赖对象的依赖
- python3.6.2利用pyinstaller发布EXE
我的环境是Ubuntu 16.04,系统自带Python2和Python3 安装 pip3 install pyinstaller 发布exe pyinstaller -F helloworld.py ...
- python 基础之for循环有限循环
# range(3) 表示 >>> range(3) [0, 1, 2] for循环 for i in range(3): print(i) 测试 0 1 2 打印1~100的奇数 ...
- HTML5语义
语义通俗化为意义,也就是语义化的元素等于意义化的元素,看到这个元素的名称,就知道这个元素的意义,是拿来做什么用的,这就是HTML5的一个新特性,一个具有语义化的元素能够清楚的把元素的意义告诉浏览器和开 ...