Python的基础--对象
对象(Objects)是python中数据的抽象,python中所有的数据均可以用对象或者是对象之间的关系来表示。每个对象均有标识符(identity)、类型(type)、值(value)。
- 标识符。对象一旦创建,那么它的标识符就不会改变,可以把标识符看作对象在内存中的地址。is 操作可以用来比较两个对象的标识符,函数id()用来返回对象标识符(python中返回对象在内存中的地址)。
- 类型。对象的类型也是不可变的,对象的类型决定了该对象支持的操作,另外也决定了该对象可能的值。type()函数返回一个对象的类型。
- 值。一些对象的值可以改变,我们叫它可变对象,字典和列表均属于可变对象;值不可改变的对象我们叫它不可变对象,数字、字符串、元组均属于不可变对象。
在python中,不存在所谓的传值调用,一切传递的都是对象的引用,也可以认为是传地址。
可变对象与不可变对象
python在heap中分配的对象分成两类:可变对象和不可变对象。所谓可变对象指的是,对象的内容可变,而不可变对象是指对象的内容不可变。
不可变(immutable)对象:int、字符串(string)、float、数值型(number)、元组(tuple)。
可变(mutable)对象:字典型(dictionary)、列表型(list)。
一、不可变对象
由于Python中的变量存放的是对象引用,所以对于不可变对象而言,尽管对象本身不可变,但变量的对象引用是可变的。
i = 73
i += 2

从上面图示得知,对象73和对象75并没有变化,变化的只是创建了一个新的对象,改变了变量的对象的引用。看看下面的代码,更能体现这一点:
#因为258是int对象,是不可变对象的。所以下面3个id的值都是一样的,最后一句的结果也是为True
#有点奇怪的是为什么在IDLE,和在脚本执行的结果不太一样。所以下面的代码请在脚本中执行。 print(id(258))
a = 258
print(id(a))
b = 258
print(id(b))
print(a is b)
总结一下,不可变对象的优缺点。
优点是:这样可以减少重复的值对内存空间的占用。
缺点是:我要修改这个变量绑定的值,如果内存中没用存在该值的内存块,那么必须重新开辟一块内存,把新地址与变量名绑定。而不是修改变量原来指向的内存块的值,这回给执行效率带来一定的降低。
二、可变对象
其对象的内容是可以变化的。当对象的内容发生变化时,变量的对象引用是不会变化的。如下面的例子:
m=[5,9]
m+=[6]

函数参数
Python函数参数对于可变对象,函数内对参数的改变会影响到原始对象;对于不可变对象,函数内对参数的改变不会影响到原始参数。原因在于:
1、可变对象,参数改变的是可变对象,其内容可以被修改。
2、不可变对象,改变的是函数内变量的指向对象。
有关可变对象和不可变对象的介绍,简单的介绍到这里。
对象的回收机制
python不像C那样需要显式地回收对象占用的空间,python内核中有垃圾回收机制,当一个对象不可达时,就会交由垃圾回收机制处理。
一些对象引用了一些外部资源,例如打开的文件或者窗口。通常我们认为当这些对象被垃圾回收机制回收时,它占用的外部资源即被释放。但是,垃圾回收机制并不一定会回收这些对象,因此这些对象提供了显式的方法(通常是_close()_)用来释放外部资源。程序中最好使用显式的方法来释放外部资源,一般可以使用 _try...finally_方便地释放。
对象的类型
对象的类型几乎影响了该对象的所有功能,在某种程度上,对象的标识符也受其类型的影响。
>>> sum = 15
>>> sum_add = 12 + 3
>>> sum is sum_add
True
>>> sum = 15000000
>>> sum_add = 10000000 + 5000000
>>> sum is sum_add
False
>>> sum_add == sum
True
对于不可变对象(这里是int),当我们需要一个新的对象(sum_add = 12 + 3)时,python可能会返回已经存在的某个类型和值都一致的对象(sum)的引用。当然,这里只是可能会返回已经存在的对象,要看python的具体实现。同样是创建新的对象sum_add = 10000000 + 5000000,python并没有把值和类型都一样的sum返回给sum_add。
>>> value = []
>>> value_1 = []
>>> value is value_1
False
>>> value == value
True
>>> value = value_1 = []
>>> value is value_1
True
对于可变对象,当我们需要新的对象时,python一定会为我们新建一个。注意,这里value = value_1 = []将会创建一个空的列表对象,然后同时返回给value和value_1。
扑朔迷离的不可变对象
首先看下面的代码:看我怎么改变不可变对象的值
>>> mutability = [1, 2, 3, 4]
>>> immutability = (0, mutability, 5)
>>> immutability
(0, [1, 2, 3, 4], 5) #查看可变对象与不可变对象的标识符(内存地址)
>>> id(mutability)
28356200
>>> id(immutability)
28048640 #对可变对象与不可变对象都做一些改变
>>> mutability[2] = "see here!"
>>> immutability
(0, [1, 2, 'see here!', 4], 5) #查看改变后的可变对象与不可变对象的标识符(内存地址)
>>> id(mutability)
28356200
>>> id(immutability)
28048640
这里元组immutability中一个元素为可变对象列表mutability,当我们改变mutability的值时,号称不可变对象的元组的值似乎发生了变化。这又是为什么呢?
回答这个问题前,先总结下上面这段代码发生了什么:不可变对象A包含了一个对可变对象B的引用,可变对象B的值发生改变时,不可变对象A的值似乎会发生改变。
那么,为什么我们仍认为A是不可变对象呢?因为A仍然包含对象B,而B的标识符并没有发生变化,也就是说A的所有元素的标识符并没有发生变化。
看内存的布局是怎样的:
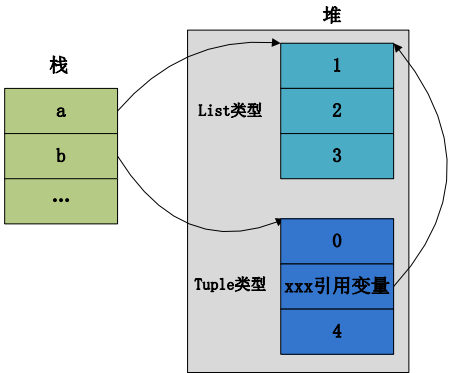
可以看出a是一个list列表类型的对象,它是一个可变对象,所以修改它的值不会创建新的对象。但是b是一个不可变对象,只要修改它的值,就会重新创建对象,注意,这里并没有修改它的值,因为它的所有元素的标识符并没有变化。
再看下面的例子:
>>> a = 2
>>> b = (1, a, 3)
>>> b
(1, 2, 3)
>>> id(a)
23112444
>>> id(b)
27983104 >>> a += 10
>>> b
(1, 2, 3)
>>> id(b[1])
23112444
>>> id(b)
27983104 >>> id(a)
23112324
在执行a+=10之前的内存布局为:
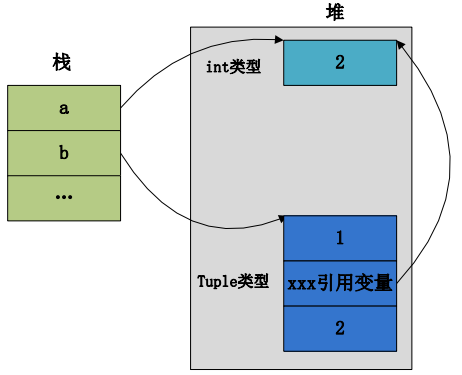
执行完a+=10的指令之后的内存布局为:
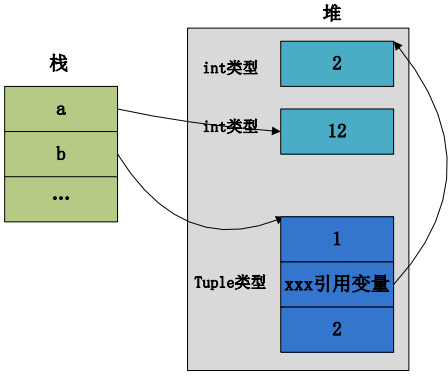
这里仅仅是原来的int(2)这个对象的引用数目减1.
在来一个狠的,在上面代码的基础上再来一个:
>>> b
(1, 2, 3) >>> b[1] = 13
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment >>> b[1]
2
通过元组类型的对象b对其中的一个int类型对象赋值,这样的话,因为int是不可变对象,所以会重新申请新的内存,那么同样会引起元组b中的xxx引用变量的改变,那么这样就真正的改变了元组b对象的某个元素的标识符。导致真正的改变了不可变元组对象b,这时就会报错。
修改上面的一些bug:
1. 首先id(a)函数是查看引用变量a所指向的对象的标识符,也就是内存地址。并不是引用变量a的内存地址。
2. 不管是元组还是列表,它们的元素存储的都是某个真实对象的引用,并不存储这个对象,因为python中一切皆对象。
先看一个内存结构,然后在看代码:
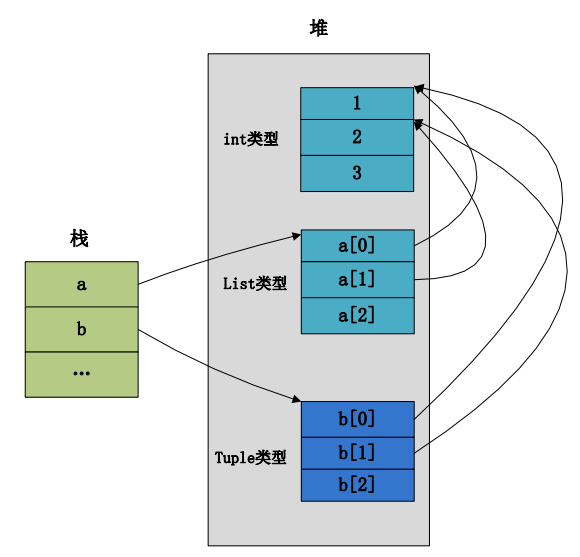
>>> a = (1,2,3)
>>> b = [1,2,3]
>>> id(a)
19840616
>>> id(b)
28577384
>>> id(a[0])
20032264
>>> id(b[0])
20032264
Python的基础--对象的更多相关文章
- Python的基础--对象 转
对象(Objects)是python中数据的抽象,python中所有的数据均可以用对象或者是对象之间的关系来表示.每个对象均有标识符(identity).类型(type).值(value). 标识 ...
- Python开发基础-Day19继承组合应用、对象序列化和反序列化,选课系统综合示例
继承+组合应用示例 class Date: #定义时间类,包含姓名.年.月.日,用于返回生日 def __init__(self,name,year,mon,day): self.name = nam ...
- python 模块基础介绍
从逻辑上组织代码,将一些有联系,完成特定功能相关的代码组织在一起,这些自我包含并且有组织的代码片段就是模块,将其他模块中属性附加到你的模块的操作叫做导入. 那些一个或多个.py文件组成的代码集合就称为 ...
- Python文件基础
===========Python文件基础========= 写,先写在了IO buffer了,所以要及时保存 关闭.关闭会自动保存. file.close() 读取全部文件内容用read,读取一行用 ...
- 3.Python编程语言基础技术框架
3.Python编程语言基础技术框架 3.1查看数据项数据类型 type(name) 3.2查看数据项数据id id(name) 3.3对象引用 备注Python将所有数据存为内存对象 Python中 ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- Python爬虫基础之requests
一.随时随地爬取一个网页下来 怎么爬取网页?对网站开发了解的都知道,浏览器访问Url向服务器发送请求,服务器响应浏览器请求并返回一堆HTML信息,其中包括html标签,css样式,js脚本等.我们之前 ...
- 举例子来说明Python引用和对象
今天看到这么一句奇怪的话: python中变量名和对象是分离的:最开始的时候是看到这句话的时候没有反应过来.决定具体搞清楚一下python中变量与对象之间的细节.(其实我感觉应该说 引用和对象分离 更 ...
- 零基础学Python--------第2章 Python语言基础
第2章 Python语言基础 2.1 Python语法特点 2.11注释 在Python中,通常包括3种类型的注释,分别是单行注释.多行注释和中文编码声明注释. 1.单行注释 在Python中,使用 ...
随机推荐
- PHP学习笔记五【方法】
<?php $num1=34; $num2=90; $oper="+"; $res=0; switch($oper) { case "+": $res=$ ...
- SQL语句函数详解__sql聚合函数
函数是一种有零个或多个参数并且有一个返回值的程序.在SQL中Oracle内建了一系列函数,这些函数都可被称为SQL或PL/SQL语句,函数主要分为两大类:单行函数.组函数 本文将讨论如何使用单行函数及 ...
- Java三大特征之多态(三)
面向对象编程有三大特性:封装.继承.多态. 封装隐藏了类的内部实现机制,可以在不影响使用的情况下改变类的内部结构,同时也保护了数据.对外界而已它的内部细节是隐藏的,暴露给外界的只是它的访问方法. 继承 ...
- 烧饼(nyoj779)
描述烧饼有两面,要做好一个兰州烧饼,要两面都弄热.当然,一次只能弄一个的话,效率就太低了.有这么一个大平底锅,一次可以同时放入k个兰州烧饼,一分钟能做好一面.而现在有n个兰州烧饼,至少需要多少分钟才能 ...
- Oracle EBS-SQL (MRP-6):检查MRP计划运行报错原因之超大数据查询1.sql
/*逐一运行检查计划运行超大数据*/ ---------------------------------------------------- /*查询-1*/ select plan_id, 'C ...
- Nand flash 的发展和eMMC
讨论到eMMC的发展历程,必须要从介绍Flash的历史开始 Flash分为两种规格:NOR Flash和NAND Flash,两者均为非易失性闪存模块. 1988年,Intel首次发出NOR flas ...
- (九)boost库之文件处理filesystem
(九)boost库之文件处理filesystem filesystem库是一个可移植的文件系统操作库,它在底层做了大量的工作,使用POSIX标准表示文件系统的路径,使C++具有了类似脚本语言的功能 ...
- Ruby小例子
1.ruby定义函数与执行函数案例 def fact(n) ) end end print fact() 结果: 24 2.一个小例子 words = [)] print "guess?\n ...
- UML_组件图
简介 众所周知,组件图是用来描述系统中的各组件之间的关系.首先我们必须知道组件的定义是什么,然后组件之间有哪些关系.理清楚这些,我们在以后的设计中才能 派上用场.UML语言对组件的定义已发生了巨大变化 ...
- Oracle表空间常用操作
--创建表空间 create tablespace test datafile 'E:\test2_data.dbf' SIZE 20M autoextend on next 5M maxsize 5 ...