caffe 中的一些参数介绍
转自:http://blog.csdn.net/cyh_24/article/details/51537709
solver.prototxt
net: "models/bvlc_alexnet/train_val.prototxt"
test_iter: 1000 #
test_interval: 1000 #
base_lr: 0.01 # 开始的学习率
lr_policy: "step" # 学习率的drop是以gamma在每一次迭代中
gamma: 0.1
stepsize: 100000 # 每stepsize的迭代降低学习率:乘以gamma
display: 20 # 没display次打印显示loss
max_iter: 450000 # train 最大迭代max_iter
momentum: 0.9 #
weight_decay: 0.0005 #
snapshot: 10000 # 没迭代snapshot次,保存一次快照
snapshot_prefix: "models/bvlc_reference_caffenet/caffenet_train"
solver_mode: GPU # 使用的模式是GPU test_iter
在测试的时候,需要迭代的次数,即test_iter* batchsize(测试集的)=测试集的大小,测试集的 batchsize可以在prototx文件里设置。test_interval
训练的时候,每迭代test_interval次就进行一次测试。momentum
灵感来自于牛顿第一定律,基本思路是为寻优加入了“惯性”的影响,这样一来,当误差曲面中存在平坦区的时候,SGD可以更快的速度学习。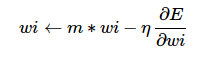 wi←m∗wi−η∂E∂wi
wi←m∗wi−η∂E∂wi
train_val.prototxt
layer { # 数据层
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN # 表明这是在训练阶段才包括进去
}
transform_param { # 对数据进行预处理
mirror: true # 是否做镜像
crop_size: 227
# 减去均值文件
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
data_param { # 设定数据的来源
source: "examples/imagenet/ilsvrc12_train_lmdb"
batch_size: 256
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST # 测试阶段
}
transform_param {
mirror: false # 是否做镜像
crop_size: 227
# 减去均值文件
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
data_param {
source: "examples/imagenet/ilsvrc12_val_lmdb"
batch_size: 50
backend: LMDB
}
}lr_mult
学习率,但是最终的学习率需要乘以 solver.prototxt 配置文件中的 base_lr .如果有两个 lr_mult, 则第一个表示 weight 的学习率,第二个表示 bias 的学习率
一般 bias 的学习率是 weight 学习率的2倍’decay_mult
权值衰减,为了避免模型的over-fitting,需要对cost function加入规范项。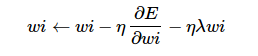 wi←wi−η∂E∂wi−ηλwi
wi←wi−η∂E∂wi−ηλwinum_output
卷积核(filter)的个数kernel_size
卷积核的大小。如果卷积核的长和宽不等,需要用 kernel_h 和 kernel_w 分别设定
stride
卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。pad
扩充边缘,默认为0,不扩充。扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。
也可以通过pad_h和pad_w来分别设定。weight_filler
权值初始化。 默认为“constant”,值全为0.
很多时候我们用”xavier”算法来进行初始化,也可以设置为”gaussian”
weight_filler {
type: "gaussian"
std: 0.01
}- bias_filler
偏置项的初始化。一般设置为”constant”, 值全为0。
bias_filler {
type: "constant"
value: 0
}bias_term
是否开启偏置项,默认为true, 开启
group
分组,默认为1组。如果大于1,我们限制卷积的连接操作在一个子集内。
卷积分组可以减少网络的参数,至于是否还有其他的作用就不清楚了。每个input是需要和每一个kernel都进行连接的,但是由于分组的原因其只是与部分的kernel进行连接的
如: 我们根据图像的通道来分组,那么第i个输出分组只能与第i个输入分组进行连接。pool
池化方法,默认为MAX。目前可用的方法有 MAX, AVE, 或 STOCHASTICdropout_ratio
丢弃数据的概率
caffe 中的一些参数介绍的更多相关文章
- Apache中 RewriteRule 规则参数介绍
Apache中 RewriteRule 规则参数介绍 摘要: Apache模块 mod_rewrite 提供了一个基于正则表达式分析器的重写引擎来实时重写URL请求.它支持每个完整规则可以拥有不限数量 ...
- htaccess文件中RewriteRule 规则参数介绍
.htaccess 文件 <IfModule mod_rewrite.c> RewriteEngine on RewriteCond %{REQUEST_FILENAME} !-d Rew ...
- Django中HttpRequest常用参数介绍
HttpRequest对象常用参数介绍,以及前端不同请求方式(http方法/Content-Type类型)对应的参数获取方式. 一.HttpRequest对象 django请求对象的详细参数以及实现方 ...
- Apache中 RewriteCond 规则参数介绍
RewriteCond指令定义了规则生效的条件,即在一个RewriteRule指令之前可以有一个或多个RewriteCond指令.条件之后的重写规则仅在当前URI与Pattern匹配并且满足此处的条件 ...
- Apache中 RewriteCond 规则参数介绍 转
摘要: RewriteCond指令定义了规则生效的条件,即在一个RewriteRule指令之前可以有一个或多个RewriteCond指令.条件之后的重写规则仅在当前URI与Pattern匹配并且满足此 ...
- caffe中的caffemodel参数提取方法
需要的文件为:deploy.prototxt caffemodel net = caffe.Net(deploy.txt,caffe_model,caffe.TEST)具体代码: import caf ...
- Apache中RewriteCond规则参数介绍
Apache中 RewriteCond语句对于我来说一直是个难点,多次试图去把它搞明白,都没有结构,这次我终于算大概知道它的意思了.RewriteCond就像我们程序中的if语句一样,表示如果符合某个 ...
- Apache中RewriteCond规则参数介绍(转)
CodeIgniter2.0已经出来有20多天了呢~也就是我一直用的php框架(CI).一直都在研究jquery,倒是把CI给忘到一边去了,呵呵~~今天公司事情不是很多,于是开始熟悉一下CI2.0的一 ...
- 【体系结构】Oracle参数介绍
[体系结构]Oracle参数介绍 1 BLOG文档结构图 2 前言部分 2.1 导读和注意事项 各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知道的知识,~O(∩_∩ ...
随机推荐
- CH Round #55 - Streaming #6 (NOIP模拟赛day2)
A.九九归一 题目:http://ch.ezoj.tk/contest/CH%20Round%20%2355%20-%20Streaming%20%236%20(NOIP模拟赛day2)/九九归一 题 ...
- Qt入门(5)——用Qt控件创建一个电话本界面
具体实现步骤: 一.首先用 Qt Designer 创建一个两张图的对话框,分别保存为listdialog.ui和editdialog.ui文件 要注意其中各个空间对应的名称修改好 二.新建一个Qt应 ...
- HDU_2048——全错位排列递推公式
Problem Description HDU 2006'10 ACM contest的颁奖晚会隆重开始了! 为了活跃气氛,组织者举行了一个别开生面.奖品丰厚的抽奖活动,这个活动的具体要求是这样的:首 ...
- DPDK2.1开发者手册1-2
Programmer’s Guide Release 2.1.0 翻译的目的是强化自己对dpdk的理解,看看2.1版本和现在使用的版本的差异,其次就是可能要走了,为那些要上手dpdk,但是又不想看英文 ...
- 数据采集工具flume
概述 flume是在2011年被首次引入到Cloudera的CDH3分发中,2011年6月,Cloudera将flume项目捐献给Apache基金会.2012年,flume项目从孵化器变成了顶级项目, ...
- paip.输入法编程---带ord gudin去重复-
paip.输入法编程---带ord gudin去重复- 作者Attilax , EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog.csdn.n ...
- springMVC学习(1)
spring mvc的位置: springMVC只是spring的一个模块: 第一步:发起请求到前端控制器(DispatcherServlet) 第二步:DispatcherServlet请求Ha ...
- jquery绑定事件on的用法
语法 $(selector).on(event,childSelector,data,function,map) 参数 描述 event 必需.规定要从被选元素移除的一个或多个事件或命名空间.由空格分 ...
- Gulp 简单的开发环境搭建
//获取gulp //require()是 node (CommonJS)中获取模块的语法 var gulp=require('gulp'); //获取gulp-concat模块(用于合并文件):np ...
- Angular基础教程:表达式日期格式化[转]
本地化日期格式化: ({{ today | date:'medium' }})Nov 24, 2015 2:19:24 PM ({{ today | date:'short' }})11/24/15 ...