Nivdia向量数据库图检索最新标杆——CAGRA
本文连接:https://wanger-sjtu.github.io/CARGA/
CAGRA 是 N社在RAFT项目中 最新的 ANN 向量索引。这是一种高性能的、 GPU 加速的、基于图的方法,尤其是针对小批量情况进行了优化,其中每次查找只包含一个或几个查询向量。
与其他像HNSW、SONG等这类基于图的方法相似,CAGRA在索引训练阶段构建了一个经过优化的 k-最近邻(k-NN)图。这个图具备多种优良特性,能够在保持合理召回率的同时实现高效的搜索。与NSW、HNSW算法不同的是,CARGA算法是单层的图,为了适用GPU计算加速,在构建和查询阶段做了特殊的优化。
using namespace raft::neighbors;
// use default index parameters based on shape of the dataset
ivf_pq::index_params build_params = ivf_pq::index_params::from_dataset(dataset);
ivf_pq::search_params search_params;
auto knn_graph = raft::make_host_matrix<IdxT, IdxT>(dataset.extent(0), 128);
// create knn graph
cagra::build_knn_graph(res, dataset, knn_graph.view(), 2, build_params, search_params);
auto optimized_gaph = raft::make_host_matrix<IdxT, IdxT>(dataset.extent(0), 64);
cagra::optimize(res, dataset, knn_graph.view(), optimized_graph.view());
// Construct an index from dataset and optimized knn_graph
auto index = cagra::index<T, IdxT>(res, build_params.metric(), dataset,
optimized_graph.view());
CAGRA构建的图有几个不同之处:
- 每个节点有固定的出度
- 构建的图是一个有向图
- 不同于HNSW,CAGRA构建的图是单层的
构建
为了满足GPU加速的要求,并行度要高、且召回率也要准确,构建的图得满足:
任意节点间的遍历能力:这是为了确保图中的所有节点都是相互可达的。如果一个图中存在某些节点无法从其他节点访问,那么这些孤立的节点在搜索过程中将永远不会被考虑,这可能导致搜索结果的不完整或不准确。确保所有节点都是相互可达的,有助于提高搜索算法的覆盖率和准确性。
指定遍历次数内的节点访问数量:这个指标用来衡量从任一节点出发,在有限的步骤内能够探索到的节点的多样性和数量。在ANNS中,通常希望在较少的遍历步骤内能够访问到更多的节点,这样可以更快地找到可能的最近邻。如果一个节点在几步之内能够访问到很多其他节点,那么搜索算法的效率和召回率(即找到真正最近邻的概率)可能会更高。
所以就涉及到了图构建过程中的优化目标:
强连通分量(Strong Connected Components, CC) 的个数
通过计算图中的强连通分量数量来评估图中任意节点是否能够到达其他任意节点。强连通分量是图中的子图,其中每个节点都可以直接或间接地到达子图中的任何其他节点。A smaller number of strong CC are preferred because a larger number of CC can lead to more unreachable nodes starting from a search start node.
平均 2 跳节点数(Average 2-hop Node Count):
这个指标衡量的是从任一节点在两次遍历内能够到达的节点数量,用以评估在特定搜索迭代步骤中可以探索的节点数量。
构建过程
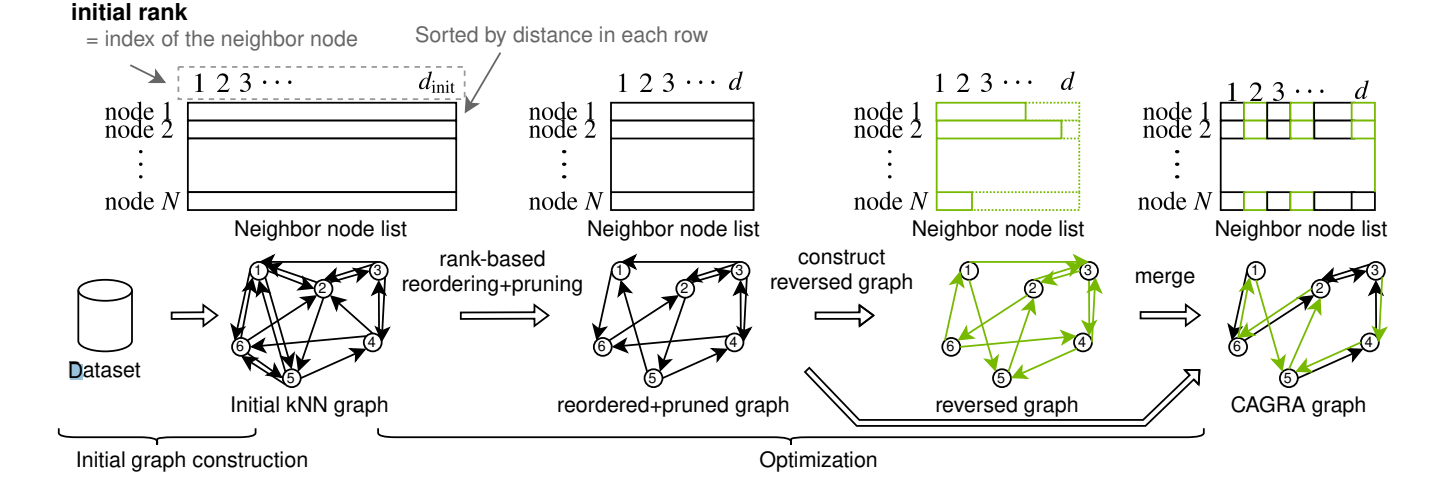
CAGRA算法的构建训练过程,先初始化一个knn graph,然后优化其中的边关系。
- 初始knn-graph创建:比较简单,这里实际上可以理论上依赖任何一种已有的算法,但在实现上选了IVF-PQ、和NN-Descent算法。这里就不过多展开了
步骤一结束后,每个节点都有k个邻居节点,并且通常按距离排序
- 基于rank的重排序:这里每个节点出边按照初始rank重新排序,并且过滤掉一些边
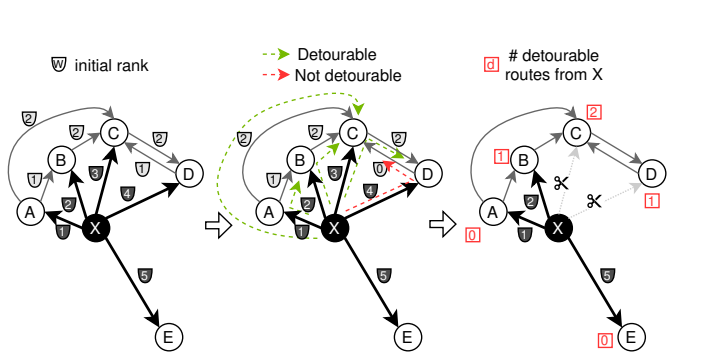
左侧:来自节点X及其他相关边的初始排名。
中间:可能的两跳路径(XAB、XBC、XCD、XAC、XDC),根据方程3被分类为可绕路和不可绕路的。我们使用排名代替距离。
\[\]\[\]右侧:连接到节点X的每个节点的可绕路路径数量。根据可绕路路径数量,从列表末尾开始丢弃边。
- 构建反向图
同样的思路构建反向图。 - 融合两张图
查找
之前的HNSW一类算法之所以不能满足GPU计算主要原因就是并行度不够,很难去发挥GPU多线程计算的优势。CAGRA不同之处在于在构图的时候尽可能保证了任意两点的可达性,在查找的时候放弃了按照最近路径找到目标节点的优化思路,而是通过提高吞吐量来尽可能覆盖尽可能多的点来提高召回率和GPU利用率。
这里需要特别提一点就是这里的buffer。其实是两部分的,前半部分top-M的,我猜测是有序的,后半部是候选访问区,不必一定保证有序。
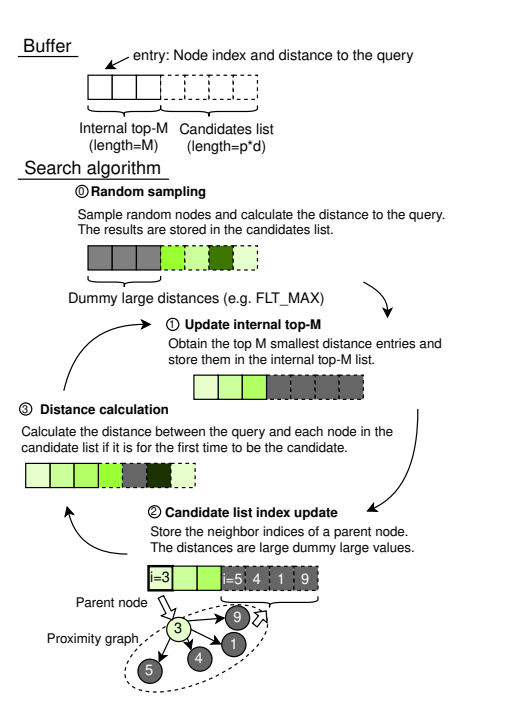
计算过程:
- 随机选取E个节点,计算他们与 query 的距离,并存在 candidate buffer 中
- 在 top-M buffer(这里应该是上一轮的结果,初始阶段为空) 和 candidate buffer 中选取 top M 个结果存储在 Top-M buffer中
- 在Top-M buffer中选取一个还没有被 traverse 的离 query 最近的节点
- 选取与 Step 3 中选择的节点近邻的E个没有访问的节点,并计算他们与query的距离,然后存储在 Candidate buffer 中
一直计算到收敛(topM buffer全部是已访问状态)
参考:
Nivdia向量数据库图检索最新标杆——CAGRA的更多相关文章
- sqlserver mdf向上兼容附加数据库(无法打开数据库 'xxxxx' 版本 611。请将该数据库升级为最新版本。)
最近工作中有一个sqlserver2005版本的mdf文件,还没有log文件,现在需要 附加到sqlserver2012,经过网上一顿搜索,把完整的过程奉上,供大家参考 首先创建数据库 再设置数据库的 ...
- MariaDb数据库管理系统学习(二)使用HeidiSQL数据库图形化界面管理工具
HeidiSQL 是一款用于简单化的 MySQL server和数据库管理的图形化界面.该软件同意你浏览你的数据库,管理表,浏览和编辑记录,管理用户权限等等.此外,你能够从文本文件导入数据,执行 SQ ...
- 【升级至sql 2012】sqlserver mdf向上兼容附加数据库(无法打开数据库 'xxxxx' 版本 611。请将该数据库升级为最新版本。)
sqlserver mdf向上兼容附加数据库(无法打开数据库 'xxxxx' 版本 611.请将该数据库升级为最新版本.) 最近工作中有一个sqlserver2005版本的mdf文件,还没有log文件 ...
- EasyUI 读数据库图
EasyUI 读数据库图 function edit_dg() { //选中一行,获取这一行的主键值 var idImg = $("#tbDeviceClassBrowstab") ...
- Oracle - SQL语句实现数据库快速检索
SQL语句实现数据库快速检索 有时候在数据库Debug过程中,需要快速查找某个关键字. 1:使用PLSQL Dev自带的查找数据库对象,进行对象查找 缺点:查找慢.耗时. 2:使用SQL语句对数据库对 ...
- 开源软件:NoSql数据库 - 图数据库 Neo4j
转载自原文地址:http://www.cnblogs.com/loveis715/p/5277051.html 最近我在用图形数据库来完成对一个初创项目的支持.在使用过程中觉得这种图形数据库实际上挺有 ...
- Scrapy爬虫:抓取大量斗图网站最新表情图片
一:目标 第一次使用Scrapy框架遇到很多坑,坚持去搜索,修改代码就可以解决问题.这次爬取的是一个斗图网站的最新表情图片www.doutula.com/photo/list,练习使用Scrapy ...
- 使用ef code first模式,在部署后服务器端把数据库同步到最新版本的方法
共有两种方法: 1.使用migrate.exe 具体使用方法请参考 msdn migrate使用方法,这里只做介绍 复制migrate.exe 在使用 NuGet 安装实体框架时,migrate.ex ...
- Linux下链接数据库图形化工具
(一).Linux环境下mysql的安装.SQL操作 Linux下安装MySQL (rmp --help) 基本步骤:上传软件->检查当前Linux环境是否已经安装,如发现系统自带的,先卸载-& ...
- 开源软件:NoSql数据库 - 图数据库 Cassandra
转载原文:http://www.cnblogs.com/loveis715/p/5299495.html Cassandra简介 在前面的一篇文章<图形数据库Neo4J简介>中,我们介绍了 ...
随机推荐
- Ubuntu 通过本机代理修复 NuGet 还原 error NU1301 失败
在国内垃圾的网络环境下,我在虚拟机里面安装了 Ubuntu 系统,准备用来测试 MAUI 在 Linux 上的行为,然而使用 dotnet restore 构建时,提示 NU1301 失败.我通过配置 ...
- SQL server 游标使用实例
--创建一个游标 DECLARE my_cursor CURSOR FOR SELECT id, Bran_number, Bran_taxis FROM dbo.Base_Branch; --打开游 ...
- K8s集群中部署SpringCloud在线购物平台(一)
一.安装k8s高可用集群 主机名 IP 配置 网络 master控制节点 192.168.10.10 centos 7.9 4核4G 桥接 node1工作节点 192.168.10.11 centos ...
- linux下安装来自github的package失败
最近使用go来做web服务器,当然还是得使用框架,于是找了几个:beego.echo等,但是我在安装得时候总是出现这类报错 cannot find package "github.com/l ...
- 海康威视web插件安装后,谷歌浏览器还是不能看视频问题
首先要根据弹出的信息提示,下载并安装视频播放插件, 安装完成后重新打开谷歌浏览器,重新登录系统,如果还是不能看视频,请按下面的方法设置: 步骤1:谷歌浏览器,地址栏中输入:chrome://flags ...
- Vue 渲染模板时怎么保留模板中的HTML 注释呢?
在组件中将 comments 选项设置为 true ...
- Docker 必知必会3----使用自己制作的镜像
前面的两篇文章分别讲了,docker的基础概念,设计思路以及docker的基本操作.感兴趣的同学可以查阅: https://www.cnblogs.com/jilodream/p/18177695ht ...
- .NET周刊【5月第2期 2024-05-12】
国内文章 C#在工业数字孪生中的开发路线实践 https://mp.weixin.qq.com/s/b_Pjt2oii0Xa_sZp_9wYWg 这篇文章探讨了C#在工业数字孪生技术中的应用,介绍了三 ...
- redis持久化存储数据(rdb和aof)
rdb持久化存储数据 总的 redis持久化 防止数据丢失,持久化到本地,以文件形式保存 持久化的方式 ,两种 aof和 rdb模式 1.触发机制, - 手动执行save命令 - 或者配置触发条件 s ...
- 【Sqlserver】查看所有数据库的大小 创建日期 名称 版本级别 状态
EXEC sp_helpdb