我用Awesome-Graphs看论文:解读X-Stream
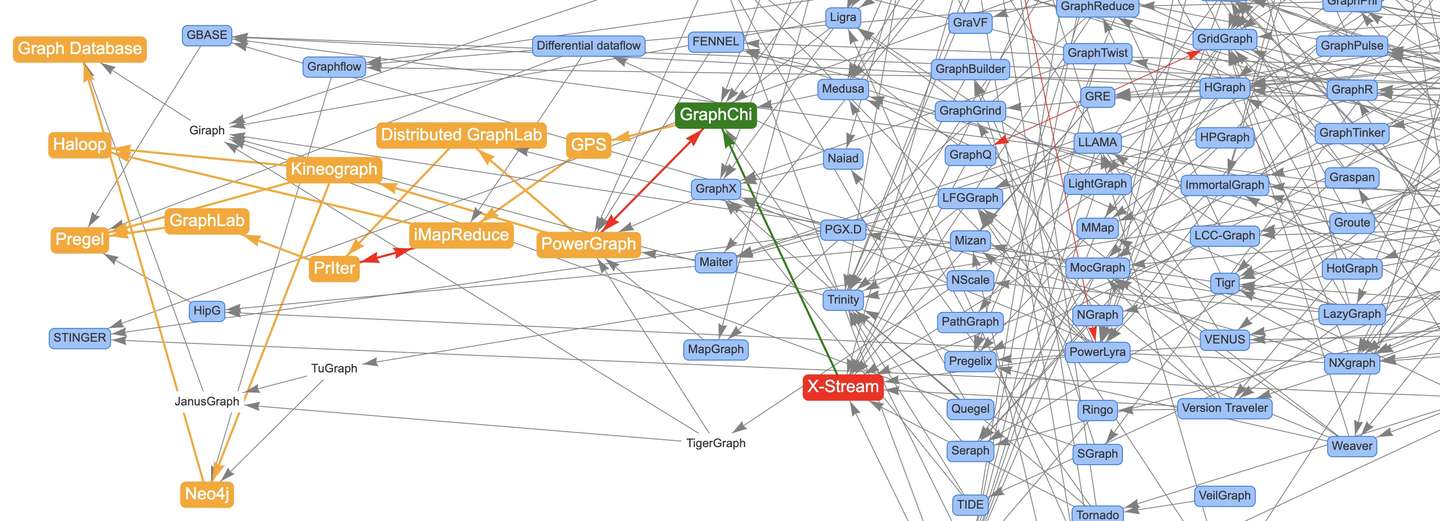
X-Stream论文:《X-Stream: Edge-centric Graph Processing using Streaming Partitions》
前面通过文章《论文图谱当如是:Awesome-Graphs用200篇图系统论文打个样》向大家介绍了论文图谱项目Awesome-Graphs,并分享了Google的Pregel以及OSDI 2012上的PowerGraph。这次向大家分享发表在SOSP 2013上的另一篇经典图计算框架论文X-Stream,构建了单机上基于外存的Scatter-Gather图处理框架。
对图计算技术感兴趣的同学可以多做了解,也非常欢迎大家关注和参与论文图谱的开源项目:
- Awesome-Graphs:https://github.com/TuGraph-family/Awesome-Graphs
- OSGraph:https://github.com/TuGraph-family/OSGraph
提前感谢给项目点Star的小伙伴,接下来我们直接进入正文!
摘要
- X-Stream是一个单机共享内存的既可以处理内存图也可以处理外存图的图处理系统。
- 特点:
- 以边为中心的计算模型。
- 流式访问无序边,而不是随机访问。
1. 介绍
传统的以点为中心的处理:
- scatter函数将点状态传播给邻居点。
- gather函数累计更新,并重新计算点状态。

顺序/随机访问不同存储介质的性能差异:
- 磁盘:500x
- SSD:30x
- 内存:1.8x - 4.6x
X-Stream的以边为中心的处理:
- scatter/gather在边/更新上迭代,而不是在点上迭代。
- 使用流式分区缓解点集的随机访问。
- 将边和源点划分到同一个分区。

X-Stream主要贡献:
- 边中心处理模型。
- 流式分区。
- 不同存储介质上的良好扩展性。
- 高性能。
2. X-Stream处理模型
API设计:
- Scatter:根据边和源点,计算目标点更新。
- Gather:根据目标点收到更新,重新计算目标点状态。
2.1 流
X-Stream使用流的方式执行Scatter+Gather。边和更新是顺序访问的,但是点是随机访问的。
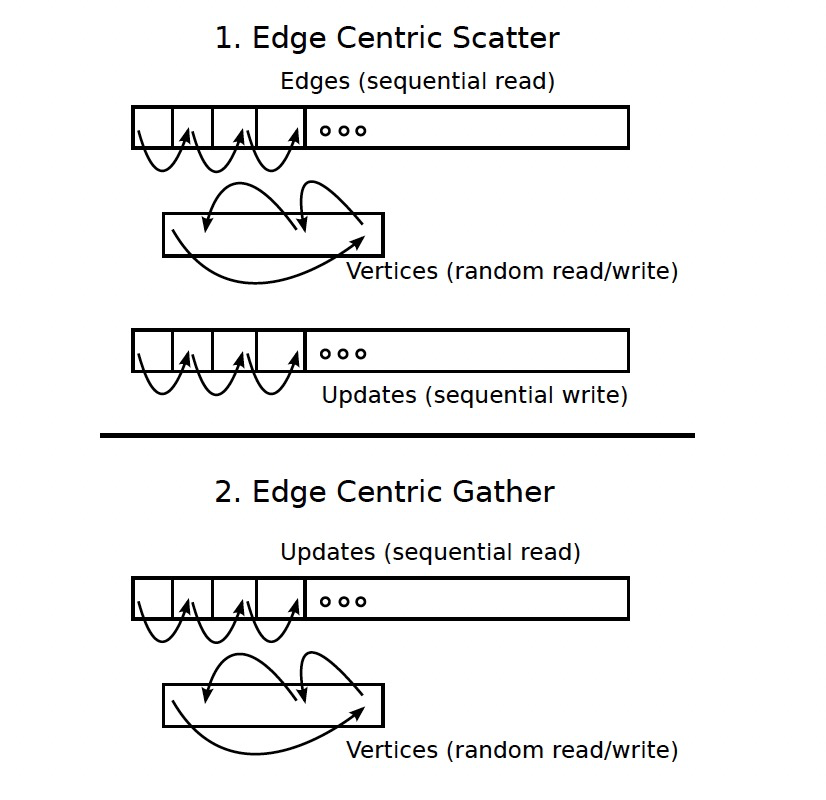
2.2 流式分区
流式分区包含:
- 点集:分区上的点子集。
- 边列表:源点的边。
- 更新列表:目标点的更新。
2.3 分区上的Scatter-Gather
Scatter + Shuffle + Gather:

2.4 分区的大小和数量
- 一方面为了让点集合尽量加载到快存储,分区数不能太小。
- 另一方面为了最大化利用慢存储的顺序读写能力,分区数不能太大。
- 通过固定分区点集合大小的方式进行分区。
2.5 API限制和扩展
- 虽然不能遍历点上的所有边,但是可以对所有的点进行迭代,并提供自定义的点函数。
- 不仅限于支持scatter-gather模型,也可以支持semi-streaming、W-Stream模型等。
3. 基于外存的流式引擎
每个流式分区维护三个磁盘文件:点文件、边文件、更新文件。
难点在于实现shuffle节点的顺序访问,通过合并scatter+shuffle阶段,更新写入到内存buffer,buffer满时执行内存shuffle追加到目标分区磁盘文件。
3.1 内存数据结构
stream buffer设计:
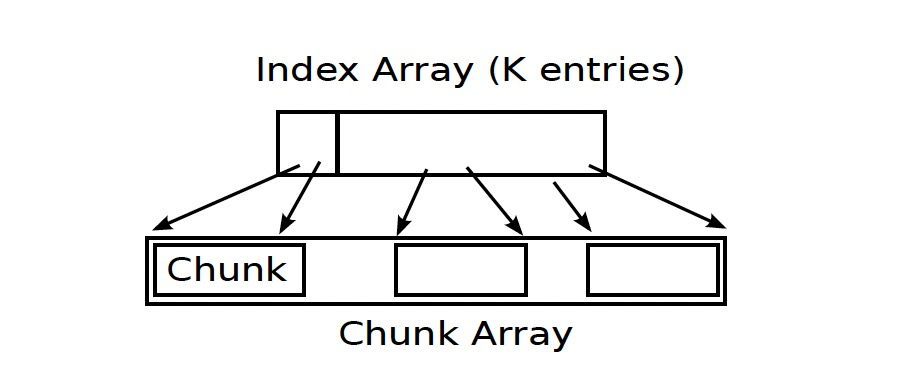
基于stream buffer,一个buffer用于存储scatter的更新,另一个存储内存shuffle的结果。
3.2 操作
初始化边分区可以使用内存shuffle方式实现。

3.3 磁盘IO
- X-Stream的stream buffer采用异步Direct I/O,而不是OS页面缓存(4K)。
- 预读和块写提高磁盘利用率,但是需要额外的stream buffer。
- 使用RAID实现读写分离。
- 使用SSD存储TRIM操作实现truncate。
3.4 分区数量
假设分区的更新满足均匀分布,则有如下内存公式:
- N:点集合内存总量。
- S:最大带宽IO请求包大小。
- K:分区数。
- M:内存总量。
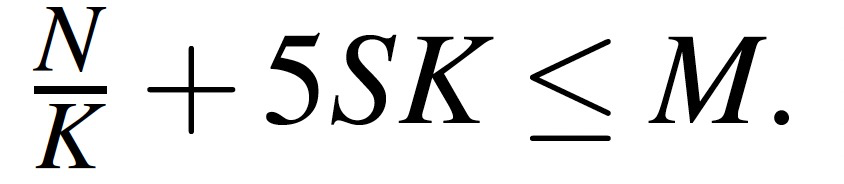
4. 基于内存的流式引擎
4.1 并行Scatter-Gather
- 每个线程写自由缓存,再统一flush到贡献的输出数据块。
- 通过worker stealing避免倾斜。
4.2 并行多阶段shuffle
- 将分区使用树形结构组织起来,分支因子F(扇出度大小),树的每一层对应一步shuffle。
- 因此对于K个分区,一共需要logFK步shuffle。
- 使用两个stream buffer轮换输入输出角色实现shuffle。
- 论文将F设置为CPU cache的可用行数。
4.3 磁盘流的分层
内存引擎逻辑上在外存引擎上层,外存引擎可以自由选择使用内存引擎处理的分区数量,以最大化利用内存和计算资源。
5. 评估
- 256M内存cache大小,在16core时达到最大内存带宽25GB/s。
- 16M IO请求包大小。
我用Awesome-Graphs看论文:解读X-Stream的更多相关文章
- 论文解读《The Emerging Field of Signal Processing on Graphs》
感悟 看完图卷积一代.二代,深感图卷积的强大,刚开始接触图卷积的时候完全不懂为什么要使用拉普拉斯矩阵( $L=D-W$),主要是其背后的物理意义.通过借鉴前辈们的论文.博客.评论逐渐对图卷积有了一定的 ...
- 论文解读(MGAE)《MGAE: Masked Autoencoders for Self-Supervised Learning on Graphs》
论文信息 论文标题:MGAE: Masked Autoencoders for Self-Supervised Learning on Graphs论文作者:Qiaoyu Tan, Ninghao L ...
- 论文解读(ValidUtil)《Rethinking the Setting of Semi-supervised Learning on Graphs》
论文信息 论文标题:Rethinking the Setting of Semi-supervised Learning on Graphs论文作者:Ziang Li, Ming Ding, Weik ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
- 《Stereo R-CNN based 3D Object Detection for Autonomous Driving》论文解读
论文链接:https://arxiv.org/pdf/1902.09738v2.pdf 这两个月忙着做实验 博客都有些荒废了,写篇用于3D检测的论文解读吧,有理解错误的地方,烦请有心人指正). 博客原 ...
- 注意力论文解读(1) | Non-local Neural Network | CVPR2018 | 已复现
文章转自微信公众号:[机器学习炼丹术] 参考目录: 目录 0 概述 1 主要内容 1.1 Non local的优势 1.2 pytorch复现 1.3 代码解读 1.4 论文解读 2 总结 论文名称: ...
- 论文解读丨基于局部特征保留的图卷积神经网络架构(LPD-GCN)
摘要:本文提出一种基于局部特征保留的图卷积网络架构,与最新的对比算法相比,该方法在多个数据集上的图分类性能得到大幅度提升,泛化性能也得到了改善. 本文分享自华为云社区<论文解读:基于局部特征保留 ...
- CVPR2020 论文解读:少点目标检测
CVPR2020 论文解读:具有注意RPN和多关系检测器的少点目标检测 Few-Shot Object Detection with Attention-RPN and Multi-Relation ...
- 图像分类:CVPR2020论文解读
图像分类:CVPR2020论文解读 Towards Robust Image Classification Using Sequential Attention Models 论文链接:https:// ...
随机推荐
- 为UIView自定义Xib
一.需求 通过Interface Builder的形式创建Xib,并将其和一个UIView的子类绑定,如何实现? 二.解决 这个问题通过搜索,有大量的答案,大概答案的代码如下: 也就是在你的子类中,在 ...
- [机器学习] 低代码机器学习工具PyCaret库使用指北
PyCaret是一个开源.低代码Python机器学习库,能够自动化机器学习工作流程.它是一个端到端的机器学习和模型管理工具,极大地加快了实验周期,提高了工作效率.PyCaret本质上是围绕几个机器学习 ...
- Cage 字符串听课笔记
困困困! KMP 注意到 KMP 的复杂度是均摊的,那么是否可以绕开? 注意到 KMP 实际上一个串的 ACAM,那么考虑可以类似的,在加入一个字符的同时维护 ACAM(考虑 ACAM 的构建过程,前 ...
- 小米 红米 Redmi 屏幕录制默认参数设置
小米 红米 Redmi 屏幕录制默认参数设置 视频画质:16Mbps. 帧数:60fps.
- C# .NET Dictionary 将集合key以ascii码从小到大排序
.NET 不加参数,默认不是按ASC II 排序 .JAVA 默认是按ASC II 排序 . Array.Sort(arrKeys, string.CompareOrdinal); 按ASC II 排 ...
- 夜莺监控(Nightingale)上线内置指标功能
Prometheus 生态里如果要查询数据,需要编写 promql,对于普通用户来说,门槛有点高.通常有两种解法,一个是通过 AI 的手段做翻译,你用大白话跟 AI 提出你的诉求,让 AI 帮你写 p ...
- WebStorm 中自定义文档注释模板
WebStorm 中自定义文档注释模板 前提 使用WebStrom写HTML,JavaScript,进行头部注释. 减少重复劳动 养成良好的代码习惯,规范化代码,规范的注释便于后续维护. 头部注释内容 ...
- springboot项目编译时,使用自定义注解类找不到符号
springboot项目编译时,使用自定义注解类找不到符号 Java项目编译时,使用自定义注解类找不到符号Spring-boot项目编辑器:idea问题:编译时找不到符号.项目中用到了自定义注解类.编 ...
- Golang支持重试的http客户端ghttp
简介 官方仓库:https://github.com/GuoFlight/ghttp 重试的逻辑依赖了github.com/avast/retry-go 入门 client := ghttp.Clie ...
- js中对对象经行判空
1.for (... in ...) for(var i in obj){ return true; //如果不为空,返回true } return false; //如果为空,返回false 2.J ...