我对《RAG/大模型/非结构化数据知识库类产品》技术架构的思考、杂谈
1、前言
在6.28/29的稀土掘金开发者大会RAG专场上,我们公司CEO员外代表TorchV分享了我们在《RAG在企业应用中落地的难点与创新》
其中最后分享了两个观点:
- AI在应用场景落地时有三个特点:功能小、质量高、价值大

- 如果说做产品是把一横做好的话,那么去做企业落地服务就是一竖,从需求和方案,再到 POC,和最后交付。

对于AI应用的三个特点,我们在落地的时候,其实碰到的问题蛮多的,但是用过大模型或者AI产品的人应该都知道,目前基于大模型应用开发的C端产品其实在整体给人的感觉都是相对较小的工具居多,在帮助人类提效这件事上,借助于AI工具,能很好的完成日常繁杂的工作和学习任务。比如AI翻译、网页总结插件等等。这类产品更多的是偏C端为主,借助于互联网的生态以及开源技术的发展,只要功能/交互满足用户的要求,很快就能打动C端用户进行尝鲜试用甚至付费。
但是做B端类的产品,整个交付的过程就明显和C端不一样,在B端我们除了产品本身需要功能足够强大之外,我们还需要做AI的落地交付,这里面包含私有化定制/客户培训/私有化部署/软硬件适配等等繁杂的工作,整个交付周期漫长的多。这明显是和上面第二个观点相呼应的,产品+服务才能综合服务好B端的客户。
本篇是结合我们公司在B端RAG/大模型应用产品的落地交付的场景考虑,以实际场景出发,谈谈我对知识库类产品的技术架构的思考总结。
2、业务功能/技术组件拆解抽象
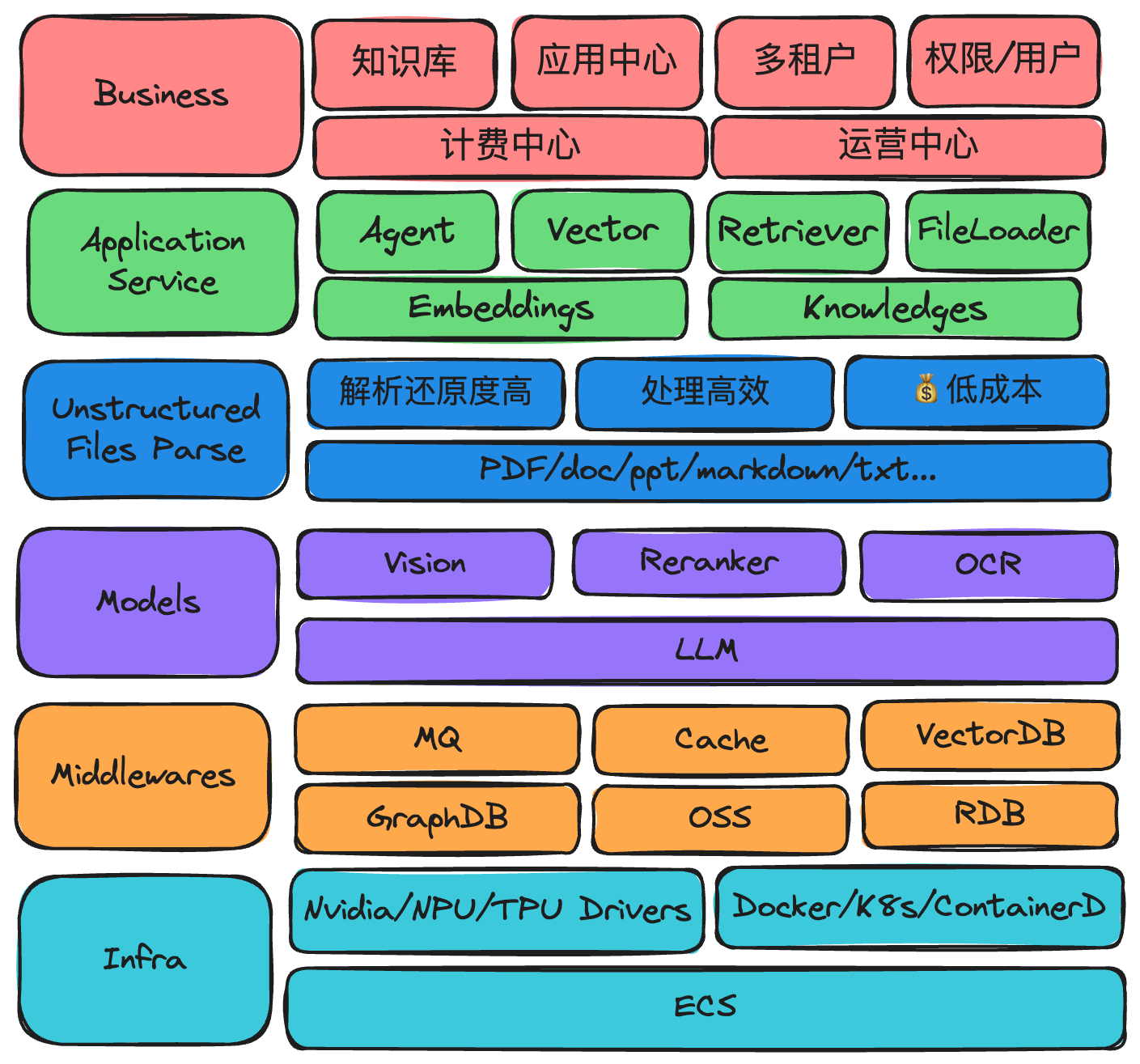
图3-业务架构
在文章的标题中,我已经标注了范围: RAG、大模型、非结构化数据
我们从这三个方面出发,在软件层面,我们如何来考虑这些新型的技术名词,将他们从技术/产品功能的角度进行拆解,实现对应的功能交付给我们的客户。
从业务的功能诉求来看,主要有几个方面:
- 知识库:客户需要将业务数据统一收集处理,形成知识库,以便提供给LLM进行使用
- 应用中心:B端客户需要开箱即用的产品,解决实际工作业务中碰到的问题
- 用户权限:系统提供企业级灵活可控的权限管理,方便企业客户进行统一管理授权。
- 多租户:多租户体系架构是必不可少的,可以保证数据以Schema级别进行隔离,保障数据安全以及上层应用的灵活输出支撑。
- ...
而从技术侧考虑,技术人员需要关注的是:
- 非结构化数据的处理:平台需要支持多种多样的非结构化数据的提取处理工作,将整个文档内容进行chunking、embedding进入数据库,以便进行搜索
- 文件类型广度:提供众多的非结构化数据文档(PDF/PPT/WORD等)的提取支持,是打动B端客户的有利吸引点,
- 文件解析精度:以PDF/PPT/Word为首的文档解析工作困难重重,如何在解析的工作上更进一步,从根源上减少模型在利用已知数据的幻觉问题
- 任务调度:数据的处理依靠稳定的任务调度平台,保证数据处理的最终有序执行。
- 模型服务:从LLM大语言模型、Reranker模型、embedding、OCR模型、视觉模型等等,保证模型的幂等输出,为上层应用提供稳定可靠的服务支撑。
- LLM模型:提供一系列Agent服务,保证上层业务能够灵活调用大模型获取满意的结果
- ReRanker模型:重排序模型是问答二阶段召回提高准确率的关键手段,不可忽虑
- Embedding模型:向量化嵌入,提供对知识文本的表征提取向量工作,不可忽虑
- OCR/视觉模型:辅助非结构化数据提取在规则提取不满足的情况下,启动OCR及视觉模型,增强非结构化数据的提供效果
- 向量数据库(VectorDB): 需要结合实际业务诉求,从性能/空间/生态等多方面考量VectorDB等选型
技术的角度拆分,其实技术人员关注的点非常的多,每一项工作其实都可以是独立的中间件产品,要把这些全部整合到一块,并非易事。
3、微服务/分布式/云原生?
写过Java的估计对上面这三个名词都已经滚瓜乱熟了,我记得很早之前,说面试你如果不会微服务,那都找不到工作(PS:现在好像不管你会什么,也同样都找不到)。
对于AI应用,可能更多的软件生态是由Python带动起来的,包括一些工具库LangChain、LlamaIndex等都是Python,虽然Java中也不乏有一些,比如LangChain4j、Spring-AI等组件,都是后起之秀,在整个生态稳定性等方面确实是落后了一节。
但可能很多人都在用过LangChain等框架后有一个共识,那就是当作工具用没有问题,但是上生产?问题太多了。我觉得主要的几个点:
- LangChain的过度封装,对于应用层而言,不管是Agent,还是RAG,其实蛮简单的一件事情,和大模型API接口对接就好了,但是你去看LangChain的源码,整个调用链路封装的极其复杂,改都没法改。
- 上层的业务需求变化太大了,有时候是需要结合自己公司的实际业务情况来进行处理的,这种情况下,还不如自己写来的快,其实调用的链路并不复杂
- 就稳定性/事务/数据一致性而言,Python作为企业服务接口主语言是否合适呢?
而我们今天讨论的是整个产品的技术架构的选择,其实在上面业务功能/技术组件抽象那一节,我们已经拆分了功能和技术点,从技术点去看,这已经是一个集众多服务于一体的综合技术解决方案了。在应用层面的功能,我们是否还需要像以前那样,整一套微服务架构出来来开发业务功能?
我的个人看法是:根据团队配置,微服务可用可不用。但是应用程序必须天然分布式,支持横向扩展集群,弹性伸缩。
目前这个环境,项目搞微服务,最后的困境可能就是所有服务都是你一个人负责,写完a服务写b服务,再来个rpc调用,还要考虑数据熔断、可用性等等,小团队我觉得完全没必要折腾!
主要考虑的点:
1、海量非结构化数据处理的提效
在处理RAG产品类中,非结构化数据的处理除了快速解析之外,还需要将文本进行向量化,而我们在技术架构中需要能够快速的处理这些文件,通过Pipeline的方式,将非结构化数据最终存储到向量数据库中,这里面传统的做法不得不用消息中间件MQ,而应用层面的程序则可以通过考虑弹性伸缩的方式,扩充消费节点,以提高整体的处理效率
2、海量向量数据的存储/计算召回效率
当我们对非结构化数据进行提取后,需要经过Embedding模型进行向量化,这里面还涉及到文本的Chunking分块,所以底层向量数据的存储和计算必然是一个需要更全面的考虑向量数据库中间件,这其中包括:向量召回的性能、数据的存储/备份、多租户Schema级别数据权限等等
3、数据最终一致性
数据的Embedding处理、大模型调度扣费、缓存等等,在目前已经众多服务组件拆分的情况下,整个数据的处理任务我觉得需要保证数据的最终一致性,在分布式场景下,多节点处理时需要特别注意。
4、应用功能原子性(云原生)
整个应用层的功能,我觉得需要保持独立,并且保障稳定性,这点其实我觉得在私有化部署/交付的环节比较奏效。如果你是一名运维或者主力开发者,在一个完全内网隔离的环境下部署时,你会体会到这种便捷。
总之,我觉得在应用层面服务,服务端应该做的是:减少配置、轻量化、稳定
4、编程语言/中间件选择?
我们团队目前的开发语言是Java+Python的组合,主要有职责分工:
- Java:上层业务应用的API接口,任务调度、数据处理等等
- Python:和模型、数据处理、NLP等相关任务以接口的形式开放出来,API接口是无状态的,所有的数据状态流转都在Java端实现
这里面很多开发可能会有一些担忧,对于Java语言的选择,是否在目前的RAG/大模型领域合适?其实最困惑的就是非结构化数据的处理,可能很多开发者看到目前开源的众多组件或者平台,都是Python的主技术栈,认为Java处理不了,其实这是完全有误区的,对于最难处理的PDF文件提取,Apache PDFBox绝对是值得你深挖的一个组件,当然Python本来就擅长数据处理/分析,可以根据团队的配置进行执行选择,这里面我觉得主要考虑的几个点:
1、团队人员配置
根据团队当前的主流编程语言去做技术架构上的选型和决策,并没有绝对意义上的以哪个编程语言为主,Java、Python、Go、NodeJS、TypeScript等等都可以。
2、软件生态&技术成熟度
上层应用产品的开发,肯定首先要考虑有哪些成熟的中间件和组件,来开发完成这一众多的需求,总不能从0到1造轮子,造轮子固然能提升开发人员的水平技能,但是在AI日益发展的今天,为公司产品尽早的找到PMF才是首要任务。需要综合考虑。
其他的编程语言我不了解,就非结构化数据的解析这一块,其实Python和Java都相对更加丰富和稳 定。
Java语言中比较好用的包括:Apache PDFBox、POI、Tika
Python中包括:PyMuPDF、pdfplumber、pypdf、camelot、python-docx等等
3、稳定性/集群/高可用
嗯,这里没有高并发,因为大家都没卡
大模型的产品相比较传统的业务在这点上并没有 太多的区别,稳定性/集群等特点也是需要的,技术人员在选择中间件时,也应当考虑这一点。
例如MQ消息中间件、缓存Redis等等
4、部署实施/交付
没错,最后一步部署实施这个环节也需要考虑,Docker确实能带来极大的便利,但是成本也是需要考量的,目前的Python生态打包整个Docker,压缩包动辄2、3G起步,其实也是蛮头疼的,如果你是使用K8s调度来部署,k8s拉取一个10G的镜像也不是那么快的
5、最后
AI应用是一个需要快速试错、功能强大的某一个点去突破,技术架构上,也应当考虑整体的开发效率、生态等等。
这让我想起来十几年前的jQuery,一经面世,得到众多开发者的喜爱,经典名言:
Write Less, Do More!!!
在大模型日益健壮发展的同时,我们的技术架构,是否也应该做一次瘦身呢?
如果你也在关注大模型、RAG检索增强生成技术,欢迎关注我,一起探索学习、成长~!

我对《RAG/大模型/非结构化数据知识库类产品》技术架构的思考、杂谈的更多相关文章
- Spark如何与深度学习框架协作,处理非结构化数据
随着大数据和AI业务的不断融合,大数据分析和处理过程中,通过深度学习技术对非结构化数据(如图片.音频.文本)进行大数据处理的业务场景越来越多.本文会介绍Spark如何与深度学习框架进行协同工作,在大数 ...
- 全网最详细中英文ChatGPT-GPT-4示例文档-从0到1快速入门解析非结构化数据应用——官网推荐的48种最佳应用场景(附python/node.js/curl命令源代码,小白也能学)
目录 Introduce 简介 setting 设置 Prompt 提示 Sample response 回复样本 API request 接口请求 python接口请求示例 node.js接口请求示 ...
- MySQL 5.7:非结构化数据存储的新选择
本文转载自:http://www.innomysql.net/article/23959.html (只作转载, 不代表本站和博主同意文中观点或证实文中信息) 工作10余年,没有一个版本能像MySQL ...
- Python爬虫(九)_非结构化数据与结构化数据
爬虫的一个重要步骤就是页面解析与数据提取.更多内容请参考:Python学习指南 页面解析与数据提取 实际上爬虫一共就四个主要步骤: 定(要知道你准备在哪个范围或者网站去搜索) 爬(将所有的网站的内容全 ...
- 结构化数据(structured),半结构化数据(semi-structured),非结构化数据(unstructured)
概念 结构化数据:即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据. 半结构化数据:介于完全结构化数据(如关系型数据库.面向对象数据库中的数据)和完全无结构的数据(如声音.图像文件等)之 ...
- 结构化数据、半结构化数据、非结构化数据——Hadoop处理非结构化数据
刚开始接触Hadoop ,指南中说Hadoop处理非结构化数据,学习数据库的时候,老师总提结构化数据,就是一张二维表,那非结构化数据是什么呢?难道是文本那样的文件?经过上网搜索,感觉这个帖子不错 网址 ...
- spark 解析非结构化数据存储至hive的scala代码
//提交代码包 // /usr/local/spark/bin$ spark-submit --class "getkv" /data/chun/sparktes.jar impo ...
- hbase非结构化数据库与结构化数据库比较
目的:了解hbase与支持海量数据查询的特性以及实现方式 传统关系型数据库特点及局限 传统数据库事务性特别强,要求数据完整性及安全性,造成系统可用性以及伸缩性大打折扣.对于高并发的访问量,数据库性能不 ...
- Apache Sqoop 结构化、非结构化数据转换工具
简介: Apache Sqoop 是一种用于 Apache Hadoop 与关系型数据库之间结构化.非结构化数据转换的工具. 一.安装 MySQL.导入测试数据 1.文档链接:http://www.c ...
- p2p gossip 结构化 非结构化
p2p P2P中文名字叫对等网络,网络中节点地位一致. QQ其实不算P2P,因为QQ利用了中央服务器. Hbase这样的分布式系统,因为有Hmaster节点,也不算是P2P网络: cas ...
随机推荐
- 03. go-zero简介及如何学go-zero
目录 一.go-zero简介及如何学go-zero 1.go-zero官方文档 2.go-zero微服务框架入门教程 3.go-zero最佳实践 4.学习资料 二.go-zero环境搭建 1.GO环境 ...
- ruby中的Hash排序
参考: https://blog.csdn.net/xing102172/article/details/9163607 For example: h={'a'=>2, 'c'=>1, ' ...
- linux基础命令及bash shell特性
linux基础命令及bash shell特性 目录 linux基础命令及bash shell特性 1.linux基础命令 1.1 查看内核版本和linux发行版本 1.2 查看服务器硬件信息 1.3 ...
- CompletableFuture学习总结
CompletableFuture 简介 在Java8中,CompletableFuture提供了非常强大的Future的扩展功能,可以帮助我们简化异步编程的复杂性,并且提供了函数式编程的能力,可以通 ...
- sql 查找是否存在的记录
场景:根据条件从数据库表中查询 『有』与『没有』,只有两种状态 方法1: SELECT count(*) FROM table WHERE a = 1 方法2: SELECT 1 FROM table ...
- centos 文件系统权限
模板:drwxrwxrwx r表是读 (Read) .w表示写 (Write) .x表示执行 (eXecute) 读.写.运行三项权限可以用数字表示,就是r=4,w=2,x=1, 777就是rwxrw ...
- 4G EPS 中的 PDN Connection
目录 文章目录 目录 前文列表 PDN PDN Connection APN APN 与 PGW POOL APN 与 vPGW APN 与漫游 PDN Type IP 类型 Non-IP 类型 MM ...
- WPF使用Shape实现复杂线条动画
看到巧用 CSS/SVG 实现复杂线条光效动画的文章,便也想尝试用WPF的Shape配合动画实现同样的效果.ChokCoco大佬的文章中介绍了基于SVG的线条动画效果和通过角向渐变配合 MASK 实现 ...
- WPF摄像头使用(WPFMediaKit)
添加WPFMediaKit引用 使用WPFMediaKit操作摄像头需要安装WPFMediaKit相关的Nuget包.选中需要进行摄像头操作的项目,然后通过Nuget安装即可. 页面代码 引入命名空间 ...
- Linux-线程优先级学习
概念 Linux系统中常用的几种调度类为SCHED_NORMAL.SCHED_FIFO.SCHED_RR. SCHED_NORMAL:用于普通线程的调度类 SCHED_FIFO和SCHED_RR是用于 ...