ElasticSearch7.3学习(十七)----搜索结果字段解析及time_out字段解析
1、搜索结果字段解析
首先插入一条测试数据
PUT /my_index/_doc/1
{
"title": "2019-09-10"
}
然后无条件搜索所有
GET my_index/_search得到的结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "2019-09-10"
}
}
]
}
}
解释
took:took表示Elasticsearch执行搜索所用的时间,单位是毫秒。这里0毫秒代表特别快,实际上一般都在几十毫秒以上。
timed_out:是否超时,这里是没有
_shards:指示搜索了多少分片,成功几个,跳过几个,失败几个。
hits.total:查询结果的数量,3个document
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的所有详细数据
2、time_out字段解析
例如下图所示:存在一个book索引,2个分片,0副本。
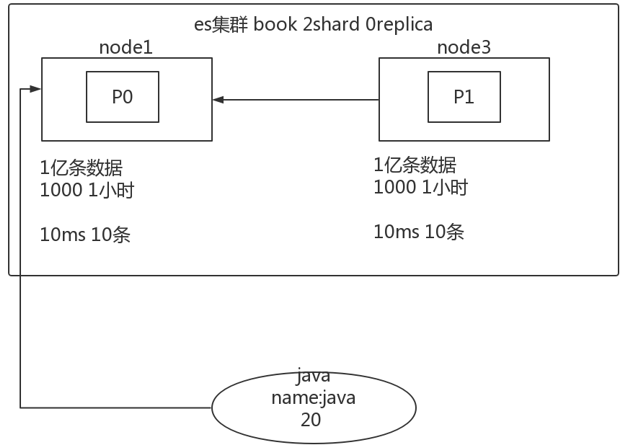
两个节点上都存在1亿条数据,假如说搜索10条,只需要10ms,这样对前端没啥影响,但是数据量太大时,搜索1个分片都需要10分钟的话,而且ES搜索的请求是每个主分片都要进行搜索,那么这个时间还得加长。这样情况下,用户肯定是受不了的。
于是引出time_out机制。指定每个shard只能在给定时间内查询数据,能有几条就返回几条。这样至少能搜索出来结果,用户也能好受一点。
ElasticSearch7.3学习(十七)----搜索结果字段解析及time_out字段解析的更多相关文章
- ElasticSearch7.3学习(二十六)----搜索(Search)参数总结、结果跳跃(bouncing results)问题解析
1.preference 首先引入一个bouncing results问题,两个document排序,field值相同:不同的shard上,可能排序不同:每次请求轮询打到不同的replica shar ...
- ElasticSearch7.3学习(二十五)----Doc value、query phase、fetch phase解析
1.Doc value 搜索的时候,要依靠倒排索引: 排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序. 所谓的正排索引,其实就是doc values. 在建立索引 ...
- 狂神说Elasticsearch7.X学习笔记整理
Elasticsearch概述 一.什么是Elasticsearch? Lucene简介 Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供 Lucene提供了一个简 ...
- ElasticSearch7.3学习(三十二)----logstash三大插件(input、filter、output)及其综合示例
1. Logstash输入插件 1.1 input介绍 logstash支持很多数据源,比如说file,http,jdbc,s3等等 图片上面只是一少部分.详情见网址:https://www.elas ...
- Solr系列五:solr搜索详解(solr搜索流程介绍、查询语法及解析器详解)
一.solr搜索流程介绍 1. 前面我们已经学习过Lucene搜索的流程,让我们再来回顾一下 流程说明: 首先获取用户输入的查询串,使用查询解析器QueryParser解析查询串生成查询对象Query ...
- 重磅 | Elasticsearch7.X学习路线图
原文:重磅 | Elasticsearch7.X学习路线图 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.c ...
- Elasticsearch7.6学习笔记1 Getting start with Elasticsearch
Elasticsearch7.6学习笔记1 Getting start with Elasticsearch 前言 权威指南中文只有2.x, 但现在es已经到7.6. 就安装最新的来学下. 安装 这里 ...
- [Elasticsearch] 多字段搜索 (三) - multi_match查询和多数字段 <译>
multi_match查询 multi_match查询提供了一个简便的方法用来对多个字段执行相同的查询. NOTE 存在几种类型的multi_match查询,其中的3种正好和在“了解你的数据”一节中提 ...
- [Elasticsearch] 多字段搜索 (三) - multi_match查询和多数字段
multi_match查询 multi_match查询提供了一个简便的方法用来对多个字段执行相同的查询. NOTE 存在几种类型的multi_match查询,其中的3种正好和在"了解你的数据 ...
- [Elasticsearch2.x] 多字段搜索 (三) - multi_match查询和多数字段 <译>
multi_match查询 multi_match查询提供了一个简便的方法用来对多个字段执行相同的查询. NOTE 存在几种类型的multi_match查询,其中的3种正好和在“了解你的数据”一节中提 ...
随机推荐
- 活动回顾|阿里云 Serverless 技术实践营 Serverless +AI 专场
8月25日"阿里云Serverless技术实践营( Serverless + AI 专场)"北京站圆满落幕.活动受众以关注 Serverless +AI 技术的开发者.企业决策人. ...
- 更省更快,如何使用 Serverless 搭建个人专属网盘?
作者| 西流 阿里云 Serverless 技术专家 1分钟 Serverless 部署个人网盘,赠好礼 随着全球大数据不断增长,未来数据云存储容量需求也将不断扩大,iiMedia Research( ...
- 3 Englishi 词根
1 -able 能..的:具有...性质的 useable moveable adaptable 2 -al 具有...性质的; 属于...的 personal natural regional - ...
- Redis-有序集合-zset
- [转帖]Oracle中有大量的sniped会话
https://www.cnblogs.com/abclife/p/15699959.html 1 2 3 4 5 6 7 SQL> select status ,count(*) from g ...
- [转帖]KingbaseES和Oracle数据类型的映射表
随着数据库国产化的进程,Oracle向KingbaseES数据库的数据迁移需求也越来越多.数据库之间数据迁移的时候,首先遇到的,并且也是最重要的,就是数据类型之间的转换. 下表为KingbaseES和 ...
- [转帖]Sosreport:收集系统日志和诊断信息的工具
https://zhuanlan.zhihu.com/p/39259107 如果你是 RHEL 管理员,你可能肯定听说过 Sosreport :一个可扩展.可移植的支持数据收集工具.它是一个从类 Un ...
- [转帖]nginx性能和软中断
https://plantegg.github.io/2022/11/04/nginx%E6%80%A7%E8%83%BD%E5%92%8C%E8%BD%AF%E4%B8%AD%E6%96%AD/ n ...
- [转帖]ChatGPT发展历程、原理、技术架构详解和产业未来 (收录于先进AI技术深度解读)
https://zhuanlan.zhihu.com/p/590655677 陈巍谈芯::本文将介绍ChatGPT的特点.功能.技术架构.局限.产业应用.投资机会和未来.作者本人曾担任华为系自然语言处 ...
- [转帖]nginx 启动、重启、关闭命令详解
https://www.jianshu.com/p/d70006f18a6d 作者:Gakki nginx 命令详解 输入命令:nginx -h nginx -h -?,-h:查看帮助 -v:显示 ...