PyFlink 开发环境利器:Zeppelin Notebook
简介: 在 Zeppelin notebook 里利用 Conda 来创建 Python env 自动部署到 Yarn 集群中。
PyFlink 作为 Flink 的 Python 语言入口,其 Python 语言的确很简单易学,但是 PyFlink 的开发环境却不容易搭建,稍有不慎,PyFlink 环境就会乱掉,而且很难排查原因。今天给大家介绍一款能够帮你解决这些问题的 PyFlink 开发环境利器:Zeppelin Notebook。主要内容为:
- 准备工作
- 搭建 PyFlink 环境
- 总结与未来
也许你早就听说过 Zeppelin,但是之前的文章都偏重讲述如何在 Zeppelin 里开发 Flink SQL,今天则来介绍下如何在 Zeppelin 里高效的开发 PyFlink Job,特别是解决 PyFlink 的环境问题。
一句来总结这篇文章的主题,就是在 Zeppelin notebook 里利用 Conda 来创建 Python env 自动部署到 Yarn 集群中,你无需手动在集群上去安装任何 PyFlink 的包,并且你可以在一个 Yarn 集群里同时使用互相隔离的多个版本的 PyFlink。最后你能看到的效果就是这样:
1. 能够在 PyFlink 客户端使用第三方 Python 库,比如 matplotlib:
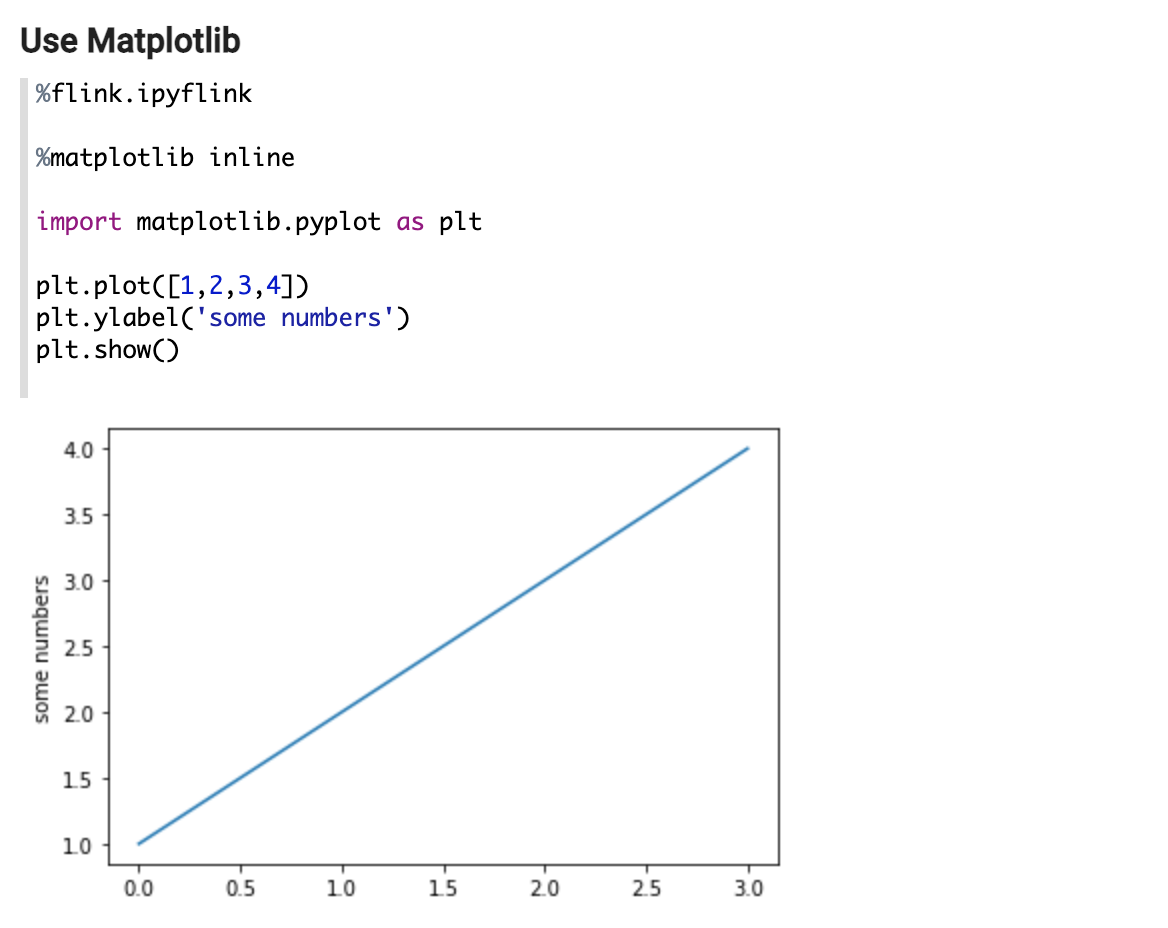
2. 可以在 PyFlink UDF 里使用第三方 Python 库,如:
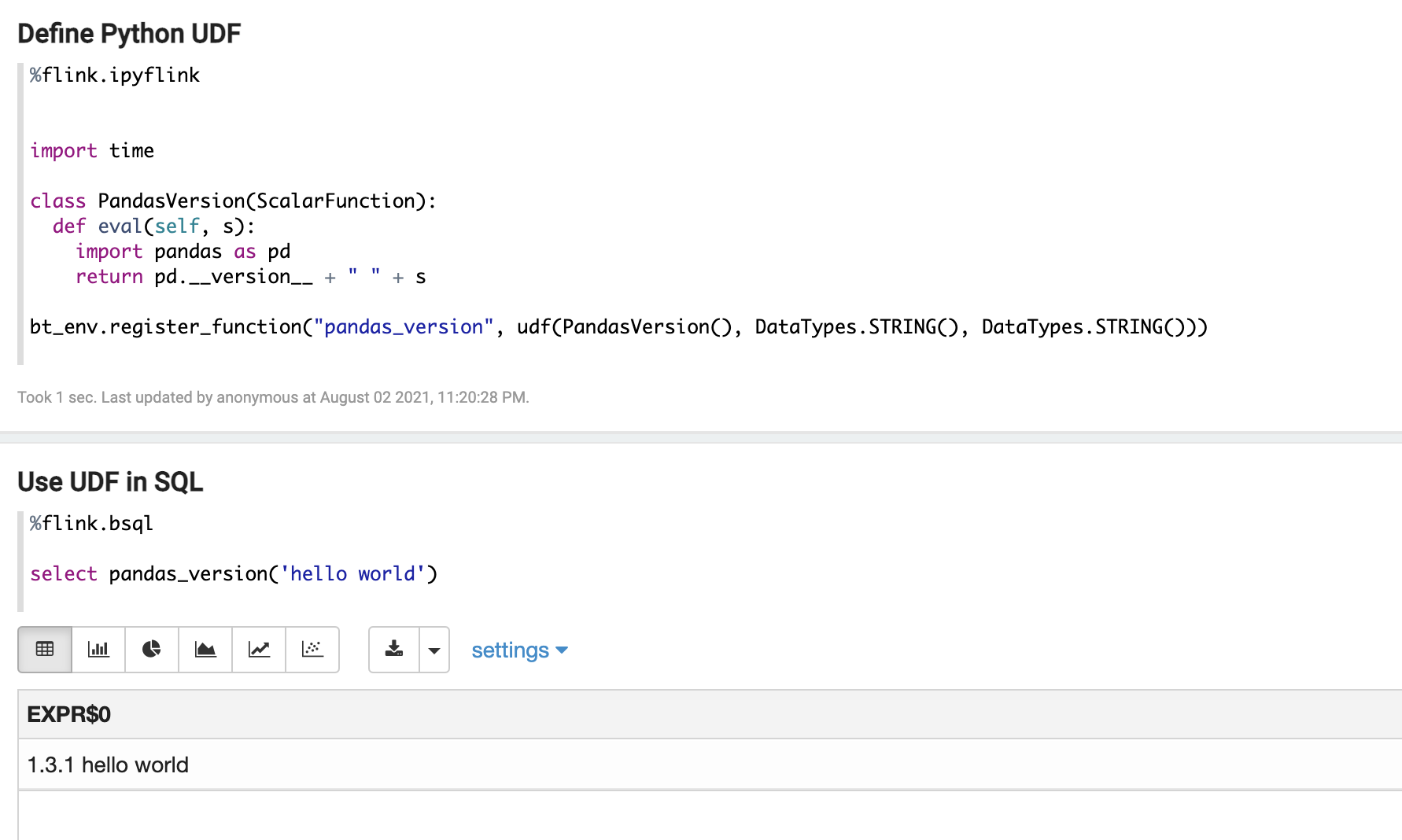
接下来看看如何来实现。
一、准备工作
Step 1.
准备好最新版本的 Zeppelin 的搭建,这个就不在这边展开了,如果有问题可以加入 Flink on Zeppelin 钉钉群 (34517043) 咨询。另外需要注意的是,Zeppelin 部署集群需要是 Linux,如果是 Mac 的话,会导致在 Mac 机器上打的 Conda 环境无法在 Yarn 集群里使用 (因为 Conda 包在不同系统间是不兼容的)。
Step 2.
下载 Flink 1.13, 需要注意的是,本文的功能只能用在 Flink 1.13 以上版本,然后:
- 把 flink-Python-*.jar 这个 jar 包 copy 到 Flink 的 lib 文件夹下;
- 把 opt/Python 这个文件夹 copy 到 Flink 的 lib 文件夹下。
Step 3.
安装以下软件 (这些软件是用于创建 Conda env 的):
- miniconda:https://docs.conda.io/en/latest/miniconda.html
- conda pack:https://conda.github.io/conda-pack/
- mamba:https://github.com/mamba-org/mamba
二、搭建 PyFlink 环境
接下来就可以在 Zeppelin 里搭建并且使用 PyFlink 了。
Step 1. 制作 JobManager 上的 PyFlink Conda 环境
因为 Zeppelin 天生支持 Shell,所以可以在 Zeppelin 里用 Shell 来制作 PyFlink 环境。注意这里的 Python 第三方包是在 PyFlink 客户端 (JobManager) 需要的包,比如 Matplotlib 这些,并且确保至少安装了下面这些包:
- 某个版本的 Python (这里用的是 3.7)
- apache-flink (这里用的是 1.13.1)
- jupyter,grpcio,protobuf (这三个包是 Zeppelin 需要的)
剩下的包可以根据需要来指定:
%sh
# make sure you have conda and momba installed.
# install miniconda: https://docs.conda.io/en/latest/miniconda.html
# install mamba: https://github.com/mamba-org/mamba
echo "name: pyflink_env
channels:
- conda-forge
- defaults
dependencies:
- Python=3.7
- pip
- pip:
- apache-flink==1.13.1
- jupyter
- grpcio
- protobuf
- matplotlib
- pandasql
- pandas
- scipy
- seaborn
- plotnine
" > pyflink_env.yml
mamba env remove -n pyflink_env
mamba env create -f pyflink_env.yml运行下面的代码打包 PyFlink 的 Conda 环境并且上传到 HDFS (注意这里打包出来的文件格式是 tar.gz):
%sh
rm -rf pyflink_env.tar.gz
conda pack --ignore-missing-files -n pyflink_env -o pyflink_env.tar.gz
hadoop fs -rmr /tmp/pyflink_env.tar.gz
hadoop fs -put pyflink_env.tar.gz /tmp
# The Python conda tar should be public accessible, so need to change permission here.
hadoop fs -chmod 644 /tmp/pyflink_env.tar.gzStep 2. 制作 TaskManager 上的 PyFlink Conda 环境
运行下面的代码来创建 TaskManager 上的 PyFlink Conda 环境,TaskManager 上的 PyFlink 环境至少包含以下 2 个包:
- 某个版本的 Python (这里用的是 3.7)
- apache-flink (这里用的是 1.13.1)
剩下的包是 Python UDF 需要依赖的包,比如这里指定了 pandas:
echo "name: pyflink_tm_env
channels:
- conda-forge
- defaults
dependencies:
- Python=3.7
- pip
- pip:
- apache-flink==1.13.1
- pandas
" > pyflink_tm_env.yml
mamba env remove -n pyflink_tm_env
mamba env create -f pyflink_tm_env.yml运行下面的代码打包 PyFlink 的 conda 环境并且上传到 HDFS (注意这里使用的是 zip 格式)
%sh
rm -rf pyflink_tm_env.zip
conda pack --ignore-missing-files --zip-symlinks -n pyflink_tm_env -o pyflink_tm_env.zip
hadoop fs -rmr /tmp/pyflink_tm_env.zip
hadoop fs -put pyflink_tm_env.zip /tmp
# The Python conda tar should be public accessible, so need to change permission here.
hadoop fs -chmod 644 /tmp/pyflink_tm_env.zipStep 3. 在 PyFlink 中使用 Conda 环境
接下来就可以在 Zeppelin 中使用上面创建的 Conda 环境了,首先需要在 Zeppelin 里配置 Flink,主要配置的选项有:
- flink.execution.mode 为 yarn-application, 本文所讲的方法只适用于 yarn-application 模式;
- 指定 yarn.ship-archives,zeppelin.pyflink.Python 以及 zeppelin.interpreter.conda.env.name 来配置 JobManager 侧的 PyFlink Conda 环境;
- 指定 Python.archives 以及 Python.executable 来指定 TaskManager 侧的 PyFlink Conda 环境;
- 指定其他可选的 Flink 配置,比如这里的 flink.jm.memory 和 flink.tm.memory。
%flink.conf
flink.execution.mode yarn-application
yarn.ship-archives /mnt/disk1/jzhang/zeppelin/pyflink_env.tar.gz
zeppelin.pyflink.Python pyflink_env.tar.gz/bin/Python
zeppelin.interpreter.conda.env.name pyflink_env.tar.gz
Python.archives hdfs:///tmp/pyflink_tm_env.zip
Python.executable pyflink_tm_env.zip/bin/Python3.7
flink.jm.memory 2048
flink.tm.memory 2048接下来就可以如一开始所说的那样在 Zeppelin 里使用 PyFlink 以及指定的 Conda 环境了。有 2 种场景:
- 下面的例子里,可以在 PyFlink 客户端 (JobManager 侧) 使用上面创建的 JobManager 侧的 Conda 环境,比如下边使用了 Matplotlib。

- 下面的例子是在 PyFlink UDF 里使用上面创建的 TaskManager 侧 Conda 环境里的库,比如下面在 UDF 里使用 Pandas。

三、总结与未来
本文内容就是在 Zeppelin notebook 里利用 Conda 来创建 Python env 自动部署到 Yarn 集群中,无需手动在集群上去安装任何 Pyflink 的包,并且可以在一个 Yarn 集群里同时使用多个版本的 PyFlink。
每个 PyFlink 的环境都是隔离的,而且可以随时定制更改 Conda 环境。可以下载下面这个 note 并导入到 Zeppelin,就可以复现今天讲的内容:http://23.254.161.240/#/notebook/2G8N1WTTS
此外还有很多可以改进的地方:
- 目前我们需要创建 2 个 conda env ,原因是 Zeppelin 支持 tar.gz 格式,而 Flink 只支持 zip 格式。等后期两边统一之后,只要创建一个 conda env 就可以;
- apache-flink 现在包含了 Flink 的 jar 包,这就导致打出来的 conda env 特别大,yarn container 在初始化的时候耗时会比较长,这个需要 Flink 社区提供一个轻量级的 Python 包 (不包含 Flink jar 包),就可以大大减小 conda env 的大小。
本文为阿里云原创内容,未经允许不得转载。
PyFlink 开发环境利器:Zeppelin Notebook的更多相关文章
- 如何基于Jupyter notebook搭建Spark集群开发环境
摘要:本文介绍如何基于Jupyter notebook搭建Spark集群开发环境. 本文分享自华为云社区<基于Jupyter Notebook 搭建Spark集群开发环境>,作者:apr鹏 ...
- ORM 开发环境之利器:MVC 中间件 FreeSql.AdminLTE
前言 这是一篇纯技术干货的分享文章,FreeSql 已经基本完成 .NETCore 最方便的 ORM 使命,我们正在筹备生态的建立,比如 ABP 中如何使用 FreeSql 的实现,需要各种各样的扩展 ...
- 打造TypeScript的Visual Studio Code开发环境
打造TypeScript的Visual Studio Code开发环境 本文转自:https://zhuanlan.zhihu.com/p/21611724 作者: 2gua TypeScript是由 ...
- windows和linux中搭建python集成开发环境IDE——如何设置多个python环境
本系列分为两篇: 1.[转]windows和linux中搭建python集成开发环境IDE 2.[转]linux和windows下安装python集成开发环境及其python包 3.windows和l ...
- 老司机学新平台 - Xamarin开发环境及开发框架初探
随着被微软收购,最近一年间,Xamarin的火爆程度与日俱增.免费.更好的VS2015集成.更好的模拟器,甚至,在windows上运行和调试iOS平台程序,让我这样接触了十几年.NET平台的老司机,即 ...
- 使用IntelliJ IDEA 13搭建Android集成开发环境(图文教程)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/ ...
- 【转】windows和linux中搭建python集成开发环境IDE
本系列分为两篇: 1.[转]windows和linux中搭建python集成开发环境IDE 2.[转]linux和windows下安装python集成开发环境及其python包 3.windows和l ...
- Android开发环境配置
由于公司项目需要,最近转做Android开发,这里我来介绍一下Android开发环境的配置过程. 首先,需要下载所需要的软件工具,如下所示: 1.Java:开发基础环境,JDK和JRE这两个都要下载的 ...
- 【Yeoman】热部署web前端开发环境
本文来自 “简时空”:<[Yeoman]热部署web前端开发环境>(自动同步导入到博客园) 1.序言 记得去年的暑假看RequireJS的时候,曾少不更事般地惊为前端利器,写了<Sp ...
- 在Ubuntu下配置舒服的Python开发环境
Ubuntu 提供了一个良好的 Python 开发环境,但如果想使我们的开发效率最大化,还需要进行很多定制化的安装和配置.下面的是我们团队开发人员推荐的一个安装和配置步骤,基于 Ubuntu 12.0 ...
随机推荐
- Redis数据库安装与使用总结
Redis语句总结 一.基本概念 Redis 全称: Remote Dictionary Server(远程字典服务器)的缩写,以字典结构存储数据,并允许其他应用通过TCP协议读写字典中的内容. 使用 ...
- 更智能的广告素材生成!看A/B测试如何驱动AIGC素材调优
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 前言:AIGC大爆发,引发广告营销行业变革 ChatGPT等AI产品引发的AIGC大爆发引起了各行业的震动,其中以 ...
- 从零开始写 Docker(九)---实现 mydocker ps 查看运行中的容器
本文为从零开始写 Docker 系列第九篇,实现类似 docker ps 的功能,使得我们能够查询到后台运行中的所有容器. 完整代码见:https://github.com/lixd/mydocker ...
- Win10 如何在桌面显示我的电脑
Win10桌面右键鼠标,然后在弹出来的选项中选择个性化. 选择了个性化后会弹出设置界面,在设置中选择[主题] 找到[桌面图标设置] 点击[桌面图标设置],会弹出一个对话框,该对话框有可以设置显示的图标 ...
- Spring Boot 工程开发常见问题解决方案,日常开发全覆盖
本文是 SpringBoot 开发的干货集中营,涵盖了日常开发中遇到的诸多问题,通篇着重讲解如何快速解决问题,部分重点问题会讲解原理,以及为什么要这样做.便于大家快速处理实践中经常遇到的小问题,既方便 ...
- java基础 韩顺平老师的 面向对象(高级) 自己记的部分笔记
373,类变量引出 代码就提到了问题分析里的3点 package com.hspedu.static_; public class ChildGame { public static void mai ...
- KingbaseES Json 系列五--Json数据操作函数三
KingbaseES Json 系列五:Json数据操作函数三(JSONB_SET,JSONB_INSERT,JSON_QUERY) JSON 数据类型是用来存储 JSON(JavaScript Ob ...
- #割点,Tarjan#洛谷 5058 [ZJOI2004]嗅探器
题目 询问能编号最小的割点删掉后使\(a\)和\(b\)无法连通 分析 考虑将\(a\)当作根,那么割点的dfn小于等于\(b\)的dfn就可以了, 怎么会呢,如果有一个环呢,所以得要让割点的子节点小 ...
- 前端使用 Konva 实现可视化设计器(2)
作为继续创作的动力,继续求 github Star 能超过 50 个(目前惨淡的 0 个),望多多支持. 源码 示例地址 在上一章,实现了"无限画布"."画布移动&quo ...
- 单元测试篇2-TDD三大法则解密
引言 在我们上一篇文章了解了单元测试的基本概念和用法之后,今天我们来聊一下 TDD(测试驱动开发) 测试驱动开发 (TDD) 测试驱动开发英文全称是Test Driven Development 简称 ...