使用mmdetection训练自己的coco数据集(免费分享自制数据集文件)
首先需要准备好数据集,这里有labelme标签数据转coco数据集标签的说明:labelme转coco数据集 - 一届书生 - 博客园 (cnblogs.com)
1. 准备工作目录
我们的工作目录,也就是mmdetection目录,如下所示:
|-- configs
| |-- _base_
| |--- .......
|-- data
| |--- coco
| | |--- annotations
| | |--- train2017
| | |--- val2017
| | |--- visualization
|-- mmdet
| |--- core
| |--- datasets
| |--- .......
|-- tools
configs就是我们的配置文件,里边包含所有的文件。
data就是我们的数据集文件,文件目录如上。
mmdet是我们所需要修改的目录。
tools是我们的mmdetection提供的工具箱,里边包含我们要用的训练和测试文件。
2. 修改mmdetection模型的配置
1️⃣ 如果自己的GPU显存不够用,修改下面文件里的img_scale=(1333, 800),改成小一点的数值。三个文件都要改。
configs/_base_/datasets/coco_detection.py
configs/_base_/datasets/coco_instance.py
configs/_base_/datasets/coco_instance_semantic.py
2️⃣ 选择你要训练的模型对应的配置文件修改,假如我要训练的模型是mask_rcnn_r101_fpn_2x_coco.py,我打开configs/mask_rcnn/mask_rcnn_r101_fpn_2x_coco.py,内容如下:
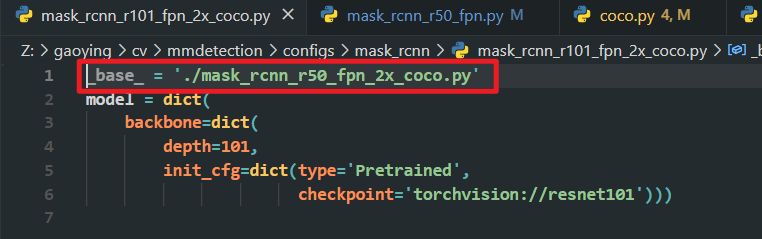
然后我们找到这个目录下的文件,修改文件里的 num_classes=80 ,修改成自己的类别数目。
configs/_base_/models/mask_rcnn_r50_fpn.py
3️⃣ 修改我们的类别名,两个文件需要修改,第一个文件是:
mmdet/core/evaluation/class_names.py
修改里边的def coco_classes(): ,将return内容修改成自己的类别。
第二个文件:
mmdet/datasets/coco.py
修改里边的class CocoDataset(CustomDataset): ,将 CLASSES = () 修改成自己的类别。
至此,修改结束,我们还需要重新编译一遍,这样才能生效,在我们的mmdetection目录下运行:
python setup.py install
3. 开始训练
1️⃣ 单GPU训练
python tools/train.py configs/mask_rcnn/mask_rcnn_r101_fpn_2x_coco.py
- configs/mask_rcnn/mask_rcnn_r101_fpn_2x_coco.py 就是我们要训练的模型
2️⃣ 多GPU训练
bash ./tools/dist_train.sh configs/mask_rcnn/mask_rcnn_r101_fpn_2x_coco.py 2
- configs/mask_rcnn/mask_rcnn_r101_fpn_2x_coco.py 就是我们要训练的模型
- 2 是我们的GPU数目
3️⃣ 我们可以刚开始训练便停止,对训练的一些配置进行修改。它会在你的mmdetection目录下自动生成一个work_dirs文件夹,里边包含你模型的配置文件,打开里边的.py文件,例如我的:
mmdetection/work_dirs/mask_rcnn_r101_fpn_2x_coco/mask_rcnn_r101_fpn_2x_coco.py
一般我们进行修改的就是下面这些,官方给的配置文件中所有参数的解释说明:mmdetection-readthedocs-io-zh_CN-latest.pdf
runner = dict(type='EpochBasedRunner', max_epochs=24)
# 最大的epochs,根据自己的情况来调整。
checkpoint_config = dict(interval=1)
# 模型权重的保存的间隔,建议调大一点,否则会保存大量模型权重,占用存储空间,例如interval=8。模型会默认保存最后一次训练的权重
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
# 日志的输出间隔,建议调小一点,例如interval=4
需要注意的是,修改完配置文件,再训练的时候,训练语句指定的配置文件就是你刚刚修改的了,也就是work_dirs目录下面的。
修改完配置文件后,单 GPU训练
python tools/train.py work_dirs/mask_rcnn_r101_fpn_2x_coco/mask_rcnn_r101_fpn_2x_coco.py
修改完配置文件后,多GPU训练
bash ./tools/dist_train.sh work_dirs/mask_rcnn_r101_fpn_2x_coco/mask_rcnn_r101_fpn_2x_coco.py 2
4. 模型测试
python tools/test.py work_dirs/mask_rcnn_r101_fpn_2x_coco/mask_rcnn_r101_fpn_2x_coco.py work_dirs/mask_rcnn_r101_fpn_2x_coco/latest.pth --show-dir work_dirs/mask_rcnn_r101_fpn_2x_coco/test_show
我是一共有十张图片,7张图片用于训练,3张图片用于测试。有个缺点我没解决,就是螺母的中间,应该为背景,我在用labelme标注过程中都已经标注为_background_,训练的时候,我是用的num_classes=2,我再测试测试。
我自己标注的数据集链接放在这:「螺丝螺母标注数据集全文件」
可视化结果展示:
 24epochs 24epochs |
 480epochs 480epochs |
同时我们的 work_dirs/mask_rcnn_r101_fpn_2x_coco/ 目录下还会有个json文件,可以可视化我们的一些评价指标的变化情况。
python tools/analysis_tools/analyze_logs.py plot_curve work_dirs/mask_rcnn_r101_fpn_2x_coco/20211015_112915.log.json --keys bbox_mAP segm_mAP
显示结果如下图:
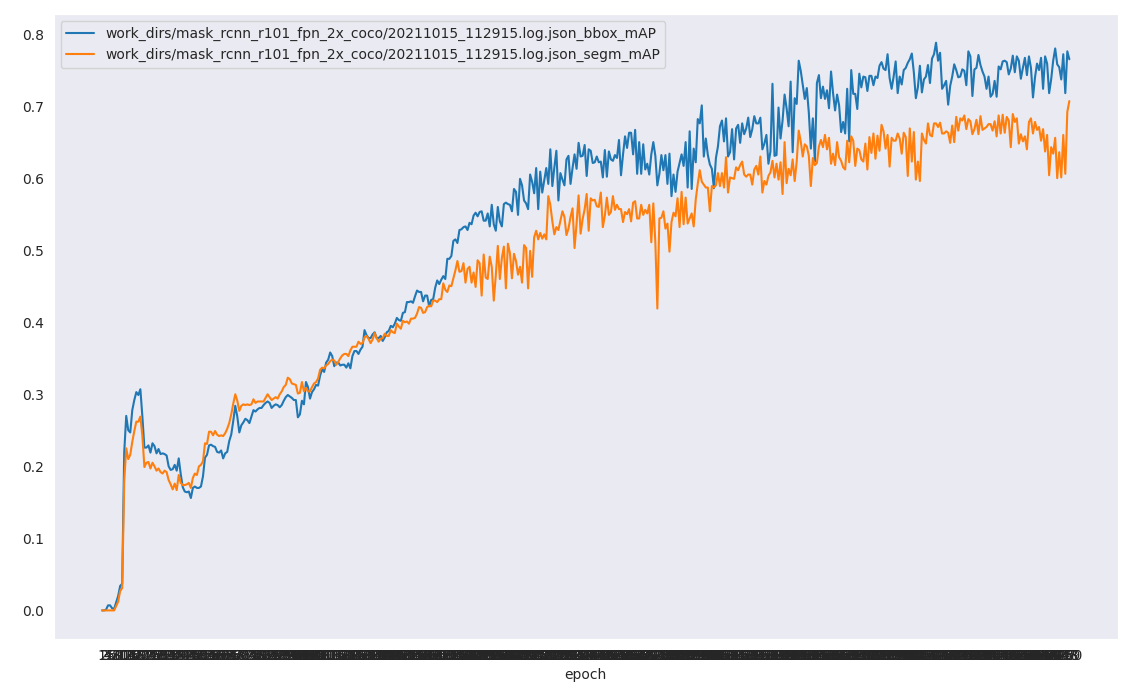
文章到此结束了,还有一些小bug,例如上边提到的螺母中间的标注问题,以及最终的评价指标的横坐标epoch显示过于紧密。后续改后对文章继续修改。
使用mmdetection训练自己的coco数据集(免费分享自制数据集文件)的更多相关文章
- 人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载
人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载 ImageNet挑战赛中超越人类的计算机视觉系统微软亚洲研究院视觉计算组基于深度卷积神经网络(CNN)的计 ...
- TensorFlow数据集(一)——数据集的基本使用方法
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 例子:从一个张量创建一个数据集,遍历这个数据集,并对每个输入输出y = x^2 的值. #!/usr/bin/en ...
- 【猫狗数据集】谷歌colab之使用pytorch读取自己数据集(猫狗数据集)
之前在:https://www.cnblogs.com/xiximayou/p/12398285.html创建好了数据集,将它上传到谷歌colab 在colab上的目录如下: 在utils中的rdat ...
- 把w3schools英文版的所有属性扒下来了,免费分享。
为了方便查手册等,把w3schools上的所以属性弄成json版的了,到时候再修改一下,查起来就比较方便了,这里免费分享一下.一共为两份,一份为选择器部分,还有一部分是属性. 选择器部分json 属性 ...
- hadoop基础教程免费分享
提起Hadoop相信大家还是很陌生的,但大数据呢?大数据可是红遍每一个角落,大数据的到来为我们社会带来三方面变革:思维变革.商业变革.管理变革,各行业将大数据纳入企业日常配置已成必然之势.阿里巴巴创办 ...
- Python Flask高级编程之RESTFul API前后端分离精讲 (网盘免费分享)
Python Flask高级编程之RESTFul API前后端分离精讲 (免费分享) 点击链接或搜索QQ号直接加群获取其它资料: 链接:https://pan.baidu.com/s/12eKrJK ...
- Python视频教程免费分享(2020年最新版)
为期92天的全套Python视频教程免费分享,总计57G! 里面还有我的笔记,希望对大家有帮助哈~ 1-32天 … … 65-92天 百度云网盘: 链接: https://pan.baidu.com/ ...
- mmdetection训练出现nan
训练出现nan 在使用MMDetection训练模型时,发现打印信息中出现了很多nan.现象是,loss在正常训练下降的过程中,突然变为nan. 梯度裁减 在模型配置中加上grad_clip: opt ...
- GPS轨迹数据集免费下载资源整理
https://blog.csdn.net/liangyihuai/article/details/58335510
- 自制 COCO api 直接读取类 COCO 的标注数据的压缩文件
第6章 COCO API 的使用 COCO 数据库是由微软发布的一个大型图像数据集,该数据集专为对象检测.分割.人体关键点检测.语义分割和字幕生成而设计.如果你要了解 COCO 数据库的一些细节,你可 ...
随机推荐
- Kafka的Controller
控制器组件(Controller),是 Apache Kafka 的核心组件.它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群.集群中任意一台 Broker ...
- Python面向对象之派生和组合
[一]什么是派生 派生是指,子类继承父类,派生出自己的属性与方法,并且重用父类的属性与方法 [二]派生的方法 子类可以派生出自己新的属性,在进行属性查找时,子类中的属性名会优先于父类被查找 例如每个老 ...
- vscode 尾逗号不自动删除 'comma-dangle': 'off' eslint vue
vscode 尾逗号不自动删除 'comma-dangle': 'off' eslint 外层环境说明 vscode eslint - .elintrs.js vue - vue开发 vetur - ...
- 2023中山市第三届香山杯网络安全大赛初赛wp
序 被带飞了 PWN move 先往变量 sskd 写入 0x20 字节,往第二个输入点输入 0x12345678 即可进入到第三个输入点,存在 0x8 字节的溢出.思路是在第一个输入点布置 rop ...
- 心电芯片ADS1292 KS1081 AD8232等的比较
首先看ADS1292, 从品牌和信誉,TI出品,这个来说应该是相对好一点的,医疗级水准的信号.内置24位的ADC,,噪声和整体功能都很全面,放大倍数1-12倍.应用在穿戴场合的缺点是:这个芯片封装尺寸 ...
- Android Studio自带模拟器无法访问网络问题解决
测试APP的时候,发现Android Studio自带的模拟器访问不了百度等网站,之前一直用的好好的,觉得可能是版本的问题,也有可能是公司网络的问题(因为在家里的电脑的Android Studio的模 ...
- 记录--微信小程序跳转H5、小程序、App
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 在业务中接触了微信小程序,客户对引流用户非常在意,每次都会提该需求,经常做就存档一下.使用的小程序账户都是企业版非个人版本. 跳转H5 在 ...
- 开发必会系列:《Java多线程编程实战》读书笔记
如何判断是否开启超线程 一 基础 进程是程序向操作系统申请资源(如内存空间和文件句柄)的基本单位.线程是进程中可独立执行的最小单位. 在Java平台中创建一个线程就是创建一个Thread类(或其子类 ...
- ssm整合简单配置
最近由于系统重装,之前已经写好了的框架都被我删的一干二净,于是自己动手重新搭了个简单的ssm(spring springmvc mybatis) 运行环境 (java1.8,Tomcat8.5,mav ...
- 《Effective Java》笔记
2. 创建和销毁对象 1. 静态工厂方法替代构造器 优点: 名称清晰 每次调用不必new对象 可以返回原返回类型任意子类型对象 返回的对象可以随着调用而发生改变 返回的对象所属的类,在编写该静态工厂方 ...