leaflet利用hotline实现河流差值渲染热力图
实现效果(这里做了1条主河道和5个支流):
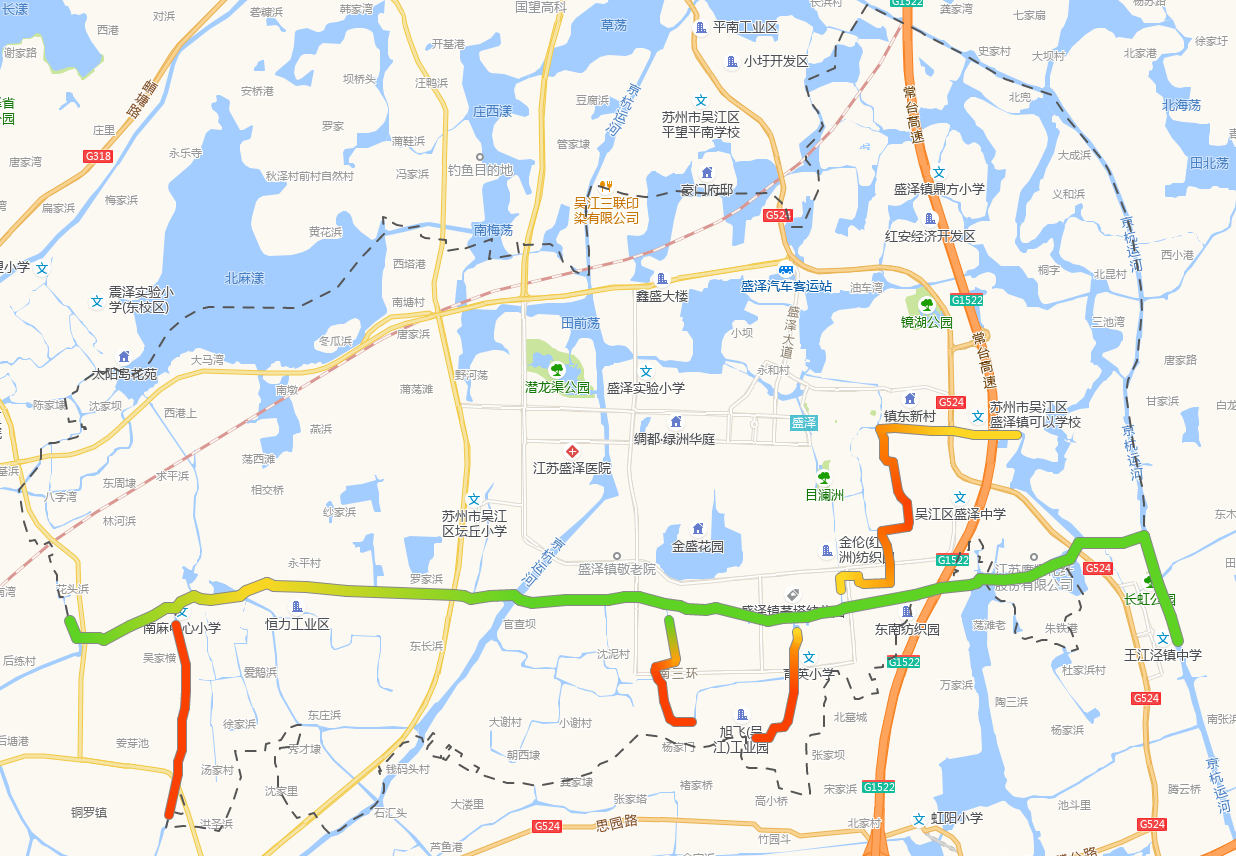
核心代码使用了Leaflet.hotline插件,github下载地址链接
核心代码逻辑:
// 处理河流数据以及渲染热线图
let coorObj = this.handleRiverData(this.waterPolType)
//渲染热力图
this.setHotline(coorObj)
//处理河流的数据
handleRiverData(type) {
const coordinateObj = {
//分离出坐标数组,同时将各个河流的经纬度进行调换
riverJson: riverJson.geometries.map(item => [item.coordinates[1], item.coordinates[0]]),
branch1: branch1.geometries.map(item => [item.coordinates[1], item.coordinates[0]]),
branch2: branch2.geometries.map(item => [item.coordinates[1], item.coordinates[0]]),
branch3: branch3.geometries.map(item => [item.coordinates[1], item.coordinates[0]]),
branch4: branch4.geometries.map(item => [item.coordinates[1], item.coordinates[0]]),
branch5: branch5.geometries.map(item => [item.coordinates[1], item.coordinates[0]])
}
let riverSiteObj = {} //站点在各个河流中的所分属的分段的索引信息
//通过riverNameArr河流名称数组将各个河流的坐标点以站点进行分段,以及计算监测因子在不同河段的值
this.riverNameArr.forEach(key => {
let arr = [] //获取站点在河流上所属河段索引起始数值和结尾的数值
if (this.siteInfoObj[key].length > 1) {
this.siteInfoObj[key].reduce((pre, val, index) => {
let startIndex = coordinateObj[key].findIndex(el => el[1] == pre.lon2 && el[0] == pre.lat2) //计算前一个站点在当前河流中的索引
let endIndex = coordinateObj[key].findIndex(el => el[1] == val.lon2 && el[0] == val.lat2) //计算后一个站点在当前河流中的索引
let startValue = pre[type] !== '-' ? getNumber(pre[type]) : val[type] !== '-' ? getNumber(val[type]) : 4 //河段的监测因子开始数值
let endValue = val[type] !== '-' ? getNumber(val[type]) :pre[type] !=='-'? getNumber(pre[type]) : 4 //河段的监测因子结束数值
let diff = startValue - endValue //河段首尾监测因子的差值
let obj = {
startIndex: startIndex,
endIndex: endIndex,
startValue: startValue,
endValue: endValue,
diff: diff
}
if (index == 1 && startIndex !== 0) {
//由于河流的首段没有站点提取出来分段,所以截取河流首段
let newobj = {
startIndex: 0,
endIndex: startIndex,
startValue: startValue,
endValue: startValue,
diff: 0
}
arr.push(newobj)
}
arr.push(obj)
if (index == this.siteInfoObj[key].length - 1) {
//由于河流的最后一段没有末尾站点提取出来分段,所以截取河流末段
let newobj = {
startIndex: endIndex,
endIndex: coordinateObj[key].length,
startValue: endValue,
endValue: endValue,
diff: 0
}
arr.push(newobj)
}
return val
})
} else {
//由于数组方法reduce无法对只有一项的数组进行运算,单独提取出来进行分段
this.siteInfoObj[key].forEach(item => {
let index = coordinateObj[key].findIndex(el => el[1] == item.lon2 && el[0] == item.lat2)
let value = item[type] !== '-' ? getNumber(item[type]) : 4
//当前河流首段分段的索引
if (index !== 0) {
let obj = {
startIndex: 0,
endIndex: index,
startValue: value,
endValue: value,
diff: 0
}
arr.push(obj)
}
//当前河流末尾分段的河流索引
let endobj = {
startIndex: index,
endIndex: coordinateObj[key].length,
startValue: value,
endValue: value,
diff: 0
}
arr.push(endobj)
})
}
riverSiteObj[key] = arr
}) let riverCoordinateObj = {} //每段河流完成了分段监测因子数值赋值合并后的新数组
//通过上述站点对各个河流的中的分段索引开始进行对河流分割,riverNameArr为各个河流名称数组
this.riverNameArr.forEach(key => {
let sectionRiverArr = [] //当前河流分段数组
//将当前河流数组进行分段处理并给该段河流的各个点位赋值监测因子数值
riverSiteObj[key].forEach(item => {
let arr = coordinateObj[key].slice(item.startIndex, item.endIndex)
let i = item.startValue
arr.forEach((el, index) => {
if (index !== arr.length - 1) {
el[2] = Number(i).toFixed(2)
i = i - item.diff / arr.length
} else {
el[2] = Number(item.endValue).toFixed(2)
}
})
sectionRiverArr.push(arr)
})
//将当前河流的分段河流合并为完整河流
let riverCoordinateArr = []
sectionRiverArr.forEach(item => {
riverCoordinateArr = [...riverCoordinateArr, ...item]
})
riverCoordinateObj[key] = riverCoordinateArr
})
//返回当前河流
return riverCoordinateObj
},
//设置热力图
setHotline(coorObj) {
let hotlineArr = []
this.riverNameArr.forEach(key => {
// hotline接收lnglat格式
let hotlineLayer = L.hotline(coorObj[key], {
min: 1, //z值的最小值
max: 6, //z值的最大值
palette: {
0.0: systemSet.water_rank_color['Ⅰ类'],
0.2: systemSet.water_rank_color['Ⅱ类'],
0.4: systemSet.water_rank_color['Ⅲ类'],
0.6: systemSet.water_rank_color['Ⅳ类'],
0.8: systemSet.water_rank_color['Ⅴ类'],
1.0: systemSet.water_rank_color['劣Ⅴ类']
},
weight: key == 'riverJson' ? 10 : 8, //线条粗细,主流是10,支流是8
outlineColor: '#888888', //边框线颜色
outlineWidth: 1 //边框线粗细
})
hotlineArr.push(hotlineLayer)
})
this.hotlineLayerGroup = L.layerGroup(hotlineArr)
this.hotlineLayerGroup.addTo(this.map)
},
leaflet利用hotline实现河流差值渲染热力图的更多相关文章
- PS图层混合算法之六(差值,溶解, 排除)
差值模式: 查看每个通道中的颜色信息,比较底色和绘图色,用较亮的像素点的像素值减去较暗的像素点的像素值.与白色混合将使底色反相:与黑色混合则不产生变化. 排除模式可生成和差值模式相似的效果,但比差值模 ...
- 差值的再议-Hermite差值
1. 插值法 插值法又称“内插法”,是利用函数f (x)在某区间中已知的若干点的函数值,作出适当的特定函数,在区间的其他点上用这特定函数的值作为函数f (x)的近似值,这种方法称为插值法. 如果这特定 ...
- 将TIMESTAMP类型的差值转化为秒的方法
两个TIMESTAMP之差得到的是INTERVAL类型,而有时我们只需要得到两个时间相差的秒数,如果变成INTERVAL之后,想要获取这个值会非常麻烦. 比较常见的方法是使用EXTRACT来抽取获得的 ...
- PHP中比较两个时间的大小与日期的差值
在这里我们全用到时间戳 mktime(hour,minute,second,month,day,year,[is_dst]) 其参数可以从右向左省略,任何省略的参数都会被设置成本地日期和时间的 ...
- 用Scala实现集合中相邻元素间的差值
欢迎转载,转载请注明出处,徽沪一郎. 概要 代码这东西,不写肯定不行,新学Scala不久,将实际遇到的一些问题记录下来,日后也好查找. 今天讲的是如何计算同一集合中元素两两之间的差值,即求开始集合(a ...
- 输出有序数组的中两个元素差值为指定值diff的两个元素
题目: 输出有序数组的中两个元素差值为指定值diff的两个元素. 思路: 这与输出两个元素的和的值为一定值类似,需要两个指针,不同的是:指针不是一左一右,而是一前一后. 如果差值等于diff,则返回: ...
- php 算法之切割数组,不用array_chunk(),算法之二,取数组的差值,不用array_diff()
用php写算法切割数组,不用array_chunk();算法例如以下所看到的. <?php //$array 数组 //$size 每一个数组的个数 //每一个数组元素是否默认键值 functi ...
- 题目1096:日期差值(a-b=(a-c)-(b-c))
http://ac.jobdu.com/problem.php?pid=1096 题目描述: 有两个日期,求两个日期之间的天数,如果两个日期是连续的我们规定他们之间的天数为两天 输入: 有多组数据,每 ...
- LD1-K(求差值最小的生成树)
题目链接 /* *题目大意: *一个简单图,n个点,m条边; *要求一颗生成树,使得其最大边与最小边的差值是所有生成树中最小的,输出最小的那个差值; *算法分析: *枚举最小边,用kruskal求生成 ...
- Hibernate中HQL的日期差值计算,可计算相差多少秒
最近有个业务需求就是计算订单创建时间离现在超过 4 小时的订单都查找出来! 那么就需要用到日期函数了. 网上找了一下总共的日期函数有一下几个: CURRENT_DATE() 返回数据库当前日期 时间函 ...
随机推荐
- list集合中的实现类ArrayList
如上图所示,list集合是 Collection 接口的子接口,它是一个元素有序(每个元素都有对应的顺序索引,第一个元素索引为0).且可重复的集合,他有三个实现类,如下: ArrayList add方 ...
- #拉格朗日插值,线性筛#洛谷 5442 【XR-2】约定 (加强版)
题目 一个\(n\)个点的完全图, 第\(i\)个点到第\(j\)个点的边权是\((i+j)^k\), 现在把这个完全图变成一棵树, 求这棵树边权和的期望值 \((n\leq 10^{10000},k ...
- gRPC入门学习之旅(五)
gRPC入门学习之旅(一) gRPC入门学习之旅(二) gRPC入门学习之旅(三) gRPC入门学习之旅(四) 通过之前的文章,我们已经创建了gRPC的服务端应用程序,那么应该如何来使用这个服务端应用 ...
- Pandas通用函数和运算
Pandas继承了Numpy的运算功能,可以快速对每个元素进行运算,即包括基本运算(加减乘除等),也包括复杂运算(三角函数.指数函数和对数函数等). 通用函数使用 apply和applymap app ...
- 决策树模型(4)Cart算法
Cart算法 Cart是Classification and regression tree的缩写,即分类回归树.它和前面的ID3, C4.5等算法思想一致都是通过对输入空间进行递归划分并确定每个单元 ...
- Python基于Excel数据加以反距离加权空间插值并掩膜图层
本文介绍基于Python中ArcPy模块,实现Excel数据读取并生成矢量图层,同时进行IDW插值与批量掩膜的方法. 1 任务需求 首先,我们来明确一下本文所需实现的需求. 现有一个记录有 ...
- k8s 深入篇———— k8s 的本质[四]
前言 简单整理一下k8s的本质. 正文 首先,Kubernetes 项目要解决的问题是什么? 编排?调度?容器云?还是集群管理? 实际上,这个问题到目前为止都没有固定的答案.因为在不同的发展阶段,Ku ...
- nginx重新整理——————nginx 的设计模型[八]
前言 简单介绍一下nginx的设计模型,对我们设计程序还是有一定帮助的. 正文 这里先列一下模型哈,后面有深入篇,介绍的比较清楚. nginx 的处理模型: nginx 进程模型: 可以看到下面列出了 ...
- locust分布式压测的Step Load及no web模式下的报表自动生成
Running Locust in Step Load ModeIf you want to monitor your service performance with different user ...
- 使用JSZip实现在浏览器中操作文件与文件夹
1. 引言 浏览器中如何创建文件夹.写入文件呢? 答曰:可以借助JSZip这个库来实现在浏览器内存中创建文件与文件夹,最后只需下载这个.zip文件,就是最终得结果 类似的使用场景如下: 在线下载很多图 ...