探索Redis与MySQL的双写问题
本文已收录至GitHub,推荐阅读 Java随想录
微信公众号:Java随想录
原创不易,注重版权。转载请注明原作者和原文链接
在日常的应用开发中,我们经常会遇到需要使用多种不同类型的数据库管理系统来满足各种业务需求。其中最典型的就是Redis和MySQL的组合使用。
这两者拥有各自的优点,例如Redis为高性能的内存数据库提供了极快的读写速度,而MySQL则是非常强大的关系型数据库,支持事务处理,并且提供了很好的数据一致性。
然而,在实际应用过程中,如何保证Redis和MySQL双写时的数据一致性问题成为了开发者们面临的重要挑战。本文即将针对这个问题进行深入探讨,希望能为广大开发者们提供一些有价值的思路和解决方案。
双写一致问题
双写一致性问题主要是指当我们同时向Redis和MySQL写数据时,由于网络延迟、服务器故障等原因,可能导致数据在两个系统之间产生不一致。
例如,你可能已经更新了MySQL中的数据,但是Redis中的数据还未来得及更新,或者反过来。这样的结果就可能导致用户读到的是旧的、不正确的数据。
比如在现实生活中的购物网站场景:假设用户A在购买一件库存仅剩1件的商品,系统在接收到请求后,先将MySQL中的库存减少1,然后出现了网络延迟或系统故障,Redis中的库存没有减少。此时,用户B看到的是还有1件商品,也发起了购买请求,如果系统又首先更改了MySQL,那么就会出现超卖的情况,即实际库存已经没有,但因为缓存中的信息不准确,导致系统销售了更多的商品。
严格意义上任何非原子操作都不可能保证一致性,除非用阻塞读写实现强一致性,所以对于缓存架构我们追求的目标是最终一致性。
实际上,缓存就是通过牺牲强一致性来提高性能的。这是由CAP理论决定的。缓存系统适用的场景就是非强一致性的场景,它属于CAP中的AP。
缓存读写策略
解决这种问题的常见策略就是“缓存读写策略”。这个策略用于处理先更新数据库还是先更新缓存等场景。
接下来,我们将探讨三种缓存读写策略。这些策略各有优劣,没有绝对的最佳选择。请根据具体的应用场景选择最合适的策略。
Cache-Aside Pattern(旁路缓存模式)
Cache-Aside Pattern,即旁路缓存模式,它的提出是为了尽可能地解决缓存与数据库的数据不一致问题。旁路缓存模式中服务端需要同时维护DB和Cache,并且是以DB的结果为准。
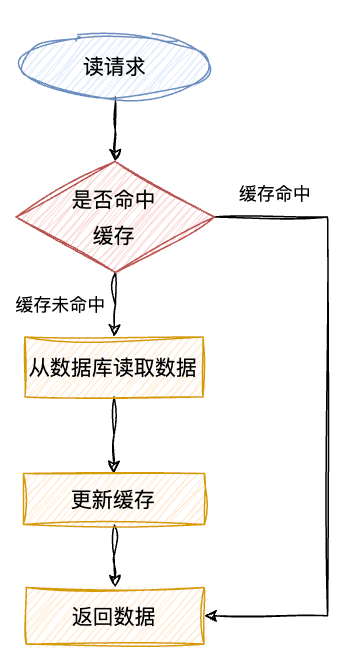
读 :从缓存读取数据,读到直接返回。如果读取不到的话,从数据库加载,写入缓存后,再返回响应。
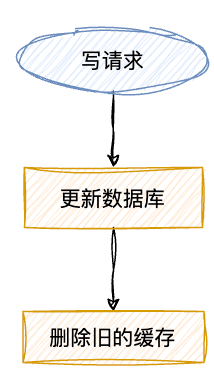
写:更新的时候,先「更新数据库,然后再删除缓存」。
Read/Write Through Pattern(读写穿透模式)
Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 DB,从而减轻了应用程序的职责。
因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入DB的功能,所以使用并不多。

读:从 cache 中读取数据,读取到就直接返回 。读取不到的话,先从 DB 加载,写入到 cache 后返回响应。
从流程图中可以看出,读写穿透模式和旁路缓存模式的读取流程几乎相同。不过,在旁路缓存模式中,客户端需要负责将数据写入cache。而在读写穿透模式中,cache服务自行写入缓存,对客户端来说,这个过程是透明的。
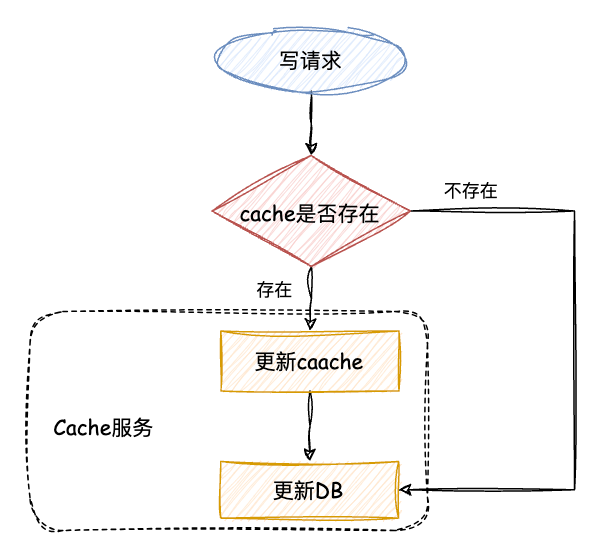
写:先查 cache,cache 中不存在,直接更新 DB。cache 中存在,则先更新 cache,然后 cache 服务自己更新 DB(同步更新 cache和DB)。
Write Behind Pattern(异步缓存写入模式)
Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 DB 的读写。
但是,两个又有很大的不同:Read/Write Through 是同步更新 cache 和 DB,而 Write Behind Caching 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。
很明显,这种方式对数据一致性带来了更大的挑战,比如cache数据可能还没异步更新DB的话,cache服务可能就挂掉了,反而会带来更大的灾难。
这种策略在我们平时开发过程中也非常非常少见,但是不代表它的应用场景少,比如消息队列中消息的异步写入磁盘、MySQL 的 InnoDB Buffer Pool 机制都用到了这种策略。
Write Behind Pattern 下 DB 的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量等。
旁路缓存模式解析
Cache Aside Pattern 的一些疑问
旁路缓存模式是我们平时中使用最多的,根据该模式,我们可能会有以下几个疑问。
为什么写操作是删除缓存,而不是更新缓存
答:假设线程A先发起一个写操作,第一步先更新数据库。线程B再发起一个写操作,紧接着也更新了数据库。由于网络等原因,线程B比线程A先更新了缓存,然后线程A更新缓存。
这时候,缓存保存的是A的数据(老数据),而数据库保存的是B的数据(新数据),数据就不一致了,脏数据出现啦。如果是「删除缓存取代更新缓存」则不会出现这个脏数据问题。
实际上要写操作的时候更新缓存也是可以的,不过我们需要加一个锁/分布式锁来保证更新cache的时候不存在线程安全问题。
在写数据的过程中,为什么要先更新DB再删除缓存
答:假设请求1 是写操作,要是先删除缓存A,这时候来了请求2,请求2是读操作,先读缓存A,发现缓存被删除了(被请求1删除了),然后去读数据库,但是此时请求1还没来得及把数据及时更新,那么请求2读的就是旧数据,并且请求2还会把读到的旧数据放到缓存中,造成了数据的不一致。
其实要先删缓存,再更新数据库也是可以,如采用「延时双删策略」。
休眠一段时间,再次淘汰缓存。这么做,可以将这段时间内所造成的缓存脏数据,再次删除。
注意sleep休眠的时间不能小于修改数据库数据的时间小,基本上1秒就够了。
在写数据的过程中,先更新DB,后删除cache就没有问题了么?
答: 理论上来说还是可能会出现数据不一致性的问题,不过概率非常小。
假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生:
- 缓存刚好失效。
- 请求A查询数据库,得一个旧值。
- 请求B将新值写入数据库。
- 请求B删除缓存。
- 请求A将查到的旧值写入缓存 ok,如果发生上述情况,确实是会发生脏数据。
然而,发生这种情况的概率并不高
发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。
可是,仔细想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。
还有其他造成不一致的原因么?
答: 如果删除缓存过程中失败了就会造成不一致问题。可以使用Canal去订阅数据库的binlog,获得需要操作的数据。另起一个程序,获得这个订阅程序传来的信息,进行删除缓存操作。
Cache Aside Pattern 的缺陷
Cache Aside Pattern是一种常见的缓存更新策略,主要在读取数据时用于处理缓存的失效和更新。尽管它有很多优点,但也存在一些缺陷:
缺陷1:首次请求数据一定不在 cache 的问题
解决办法:可以将热点数据提前放入cache 中。
缺陷2:写操作比较频繁的话导致cache中的数据会被频繁被删除,这样会影响缓存命中率 。
- 数据库和缓存数据强一致场景 :更新DB的时候同样更新cache,不过我们需要加一个锁/分布式锁来保证更新cache的时候不存在线程安全问题。
- 可以短暂地允许数据库和缓存数据不一致的场景 :更新DB的时候同样更新cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
延时双删
Redis的延时双删策略主要用于解决分布式系统当中的缓存与数据库数据一致性问题。以下是其基本步骤:
- 先删除缓存。
- 再更新数据库。
- 最后延时再次删除缓存。
该策略的理念是:如果有其他线程在步骤1和步骤2之间查询到旧的数据并写入了缓存,那么步骤3可以保证这部分旧的数据被清除,从而尽可能维持数据库和缓存之间的数据一致性。
以下是使用Java实现的样例代码:
import redis.clients.jedis.Jedis;
public class RedisDoubleDelStrategy {
private Jedis jedis;
private static final long DELAY_MILLIS = 1000L; // 设置为你需要的延时时间
public RedisDoubleDelStrategy(String host, int port) {
this.jedis = new Jedis(host, port);
}
public void updateDBAndCache(String key, String value) {
// Step 1: 删除缓存
jedis.del(key);
// Step 2: 更新数据库,此处以打印输出代替
System.out.println("Update DB with: " + value);
// 延迟任务来完成第二次删除
new Thread(() -> {
try {
Thread.sleep(DELAY_MILLIS);
} catch (InterruptedException e) {
e.printStackTrace();
}
// Step 3: 延时后再次删除缓存
jedis.del(key);
}).start();
}
}
这段代码实现了延时双删策略,但请注意它仍然不能完全保证数据库和缓存之间的一致性。
在某些情况下(比如大量并发情况下),可能仍然会出现不一致的问题。例如,在步骤3之后,如果还有其他线程查询到了旧数据并写入了缓存,那么数据库和缓存的数据就会不一致。因此,在使用该策略时,需要根据你的系统特性和一致性需求来进行权衡。
本篇文章到这就结束了,在探讨Redis与MySQL双写问题的过程中,我们分析了各种可能的场景和解决方案。双写系统不仅考验我们对数据库原理的理解,也展示了协同工作的复杂性。最终,解决这个问题的关键是理解你的用例并根据实际需求选择适当的策略和工具。
而在实际应用中,再完美的方案也可能会遇到挑战和困难。因此,持续监控,频繁测试和及时调整策略都至关重要。希望本文能为你在处理Redis与MySQL双写问题上提供一些思路和灵感,同时,我们也期待在未来看到更多精妙的解决方案诞生。
感谢阅读,如果本篇文章有任何错误和建议,欢迎给我留言指正。
老铁们,关注我的微信公众号「Java 随想录」,专注分享Java技术干货,文章持续更新,可以关注公众号第一时间阅读。
一起交流学习,期待与你共同进步!
探索Redis与MySQL的双写问题的更多相关文章
- 《Redis Mysql 双写一致性问题》
一:序 - 最近在对数据做缓存时候,会涉及到如何保证 数据库/Redis 一致性问题. - 刚好今天来总结下 一致性问题 产生的问题,和可能存在的解决方案. 二:(更新策略)- 先更新数据库,后更新 ...
- Redis Mysql 双写一致性问题
一:序 - 最近在对数据做缓存时候,会涉及到如何保证 数据库/Redis 一致性问题. - 刚好今天来总结下 一致性问题 产生的问题,和可能存在的解决方案. 二:(更新策略)- 先更新数据库,后更新 ...
- 借读:分布式锁和双写Redis
本帖最后由 howtodown 于 2016-10-3 16:01 编辑问题导读1.为什么会产生分布式锁?2.使用分布式锁的方法有哪些?3.本文创造的分布式锁的双写Redis框架都包含哪些内容? ...
- Redis 多级缓存架构和数据库与缓存双写不一致问题
采用三级缓存:nginx本地缓存+redis分布式缓存+tomcat堆缓存的多级缓存架构 时效性要求非常高的数据:库存 一般来说,显示的库存,都是时效性要求会相对高一些,因为随着商品的不断的交易,库存 ...
- Redis面试题记录--缓存双写情况下导致数据不一致问题
转载自:https://blog.csdn.net/lzhcoder/article/details/79469123 https://blog.csdn.net/u013374645/article ...
- Redis双写一致性与缓存更新策略
一.双写一致性 双写一致性,也就是说 Redis 和 mysql 数据同步 双写一致性数据同步的方案有: 1.先更新数据库,再更新缓存 这个方案一般不用: 因为当有两个请求AB先后更新数据库后,A应该 ...
- 面试前必知Redis面试题—缓存雪崩+穿透+缓存与数据库双写一致问题
今天来分享一下Redis几道常见的面试题: 如何解决缓存雪崩? 如何解决缓存穿透? 如何保证缓存与数据库双写时一致的问题? 一.缓存雪崩 1.1什么是缓存雪崩? 回顾一下我们为什么要用缓存(Redis ...
- (转)面试前必知Redis面试题—缓存雪崩+穿透+缓存与数据库双写一致问题
背景:redis问题在面试过程中经常被问到,对于常见问题一定不能放过. 面试前必知Redis面试题—缓存雪崩+穿透+缓存与数据库双写一致问题 一.缓存雪崩 1.1什么是缓存雪崩? 如果缓存数据设置的过 ...
- 第三节:Redis缓存雪崩、击穿、穿透、双写一致性、并发竞争、热点key重建优化、BigKey的优化 等解决方案
一. 缓存雪崩 1. 含义 同一时刻,大量的缓存同时过期失效. 2. 产生原因和后果 (1). 原因:由于开发人员经验不足或失误,大量热点缓存设置了统一的过期时间. (2). 产生后果:恰逢秒杀高峰, ...
- Redis中如何保证数据库和缓存双写时的数据的一致性?
简单的场景: 直接使用 1. 使用Cache Aside pattern 读取的时候,先读取缓存中是否有数据,缓存中没有数据,再去数据库中进行查询,查询出来以后,然后再存入到缓存中 更新的时候,先删除 ...
随机推荐
- 使用C#编写.NET分析器(三)
译者注 这是在Datadog公司任职的Kevin Gosse大佬使用C#编写.NET分析器的系列文章之一,在国内只有很少很少的人了解和研究.NET分析器,它常被用于APM(应用性能诊断).IDE.诊断 ...
- 利用Aspose.Word对Word文件添加印章处理以及实现业务数据的替换处理
有时候,我们在处理大量文档的时候,需要批量给Word文档添加印章处理,方便打印操作,本篇随笔介绍利用Aspose.Word对Word文件添加印章处理以及实现业务数据的替换处理. 1.利用Aspose. ...
- 使用 Dockerfile 构建生产环境镜像
传统部署的坑: 1202 年了,如果你连 Docker 都不知道是什么,我建议买一本书看看--或者谷歌一下,博客已经写烂了. 为什么有这篇文章,是因为我在真正做容器化改造的时候,发现公司生产环境存在大 ...
- MAUI Blazor项目中如何添加一个返回服务,并支持安卓返回键
前言 MAUI Blazor中,安卓项目的返回键体验很不好,只能如同浏览器一样返回上一页.但很多时候,我们想让他返回的上一页,不一定就是实际上的上一页.而且也想让返回键去支持一些事件,按下返回键触发, ...
- Java并发(十三)----共享存在的问题
1.小故事 老王(操作系统)有一个功能强大的算盘(CPU),现在想把它租出去,赚一点外快 小南.小女(不同的线程)来使用这个算盘来进行一些计算,并按照时间给老王支付费用 但小南不能一天24小时使用算盘 ...
- quarkus实战之七:使用配置
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<quarkus实战>系列 ...
- 使用Docker安装Apollo并使用SpringBoot连接配置中心
上篇文章我们学习了Apollo的本地安装,如果还不会本地安装的朋友可以查看之前的文章进行了解和学习链接地址(https://www.cnblogs.com/eternality/p/17583023. ...
- Canvas好难,如何让研发低成本实现Web端流程图设计功能
摘要:本文由葡萄城技术团队于博客园原创并首发.转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 前言 相信大家在职场中经常会用到流程图,在互联网行业,绘制流程 ...
- 如何创建Windows 10 虚拟机
一 ,新建Windows 10 虚拟机 1.1 创建新的虚拟机 1,点击创建新的虚拟机 2,选择典型,点击下一步 3,选择稍后安装操作系统,点击下一步. 4,操作系统选择windwos,版本选着Win ...
- Python类型提示
摘自:Python 类型提示简介 - FastAPI (tiangolo.com) 快速入门 类型提示用于声明一个变量的类型,在Python 3.6+版本的时候引入. 示例: def get_full ...