墨天轮访谈 | SelectDB 衣国垒:Apache Doris(incubating)1.0版本特性解析与未来规划
分享嘉宾:衣国垒 Apache Doris Committer、SelectDB 联合创始人&CTO
整理:墨天轮社区
导读
大家好,我是来自Apache Doris社区的衣国垒,也是SelectDB的联合创始人,今天为大家分享的内容是《Apache Doris(incubating)1.0版本特性解析与未来规划》。
Apache Doris 介绍
1、Apache Doris 发展历程
Apache Doris(incubating)是一个高性能、简单易用、支持实时的MPP架构分析型数据库,最早发源于百度内部的广告统计报表场景中,后来随着系统的多次优化迭代开始在百度内部得到大范围推广,成为百度统一的OLAP分析平台。2017年正式在GitHub上开源,2018年被捐献给Apache基金会进行孵化并正式更名为Apache Doris(incubating)。
据粗略统计,目前在全球范围内有超过500家企业使用Apache Doris,百度、美团、小米、京东、腾讯、网易、字节、新浪等众多一线互联网公司长期运行Apache Doris 在其生产环境中。
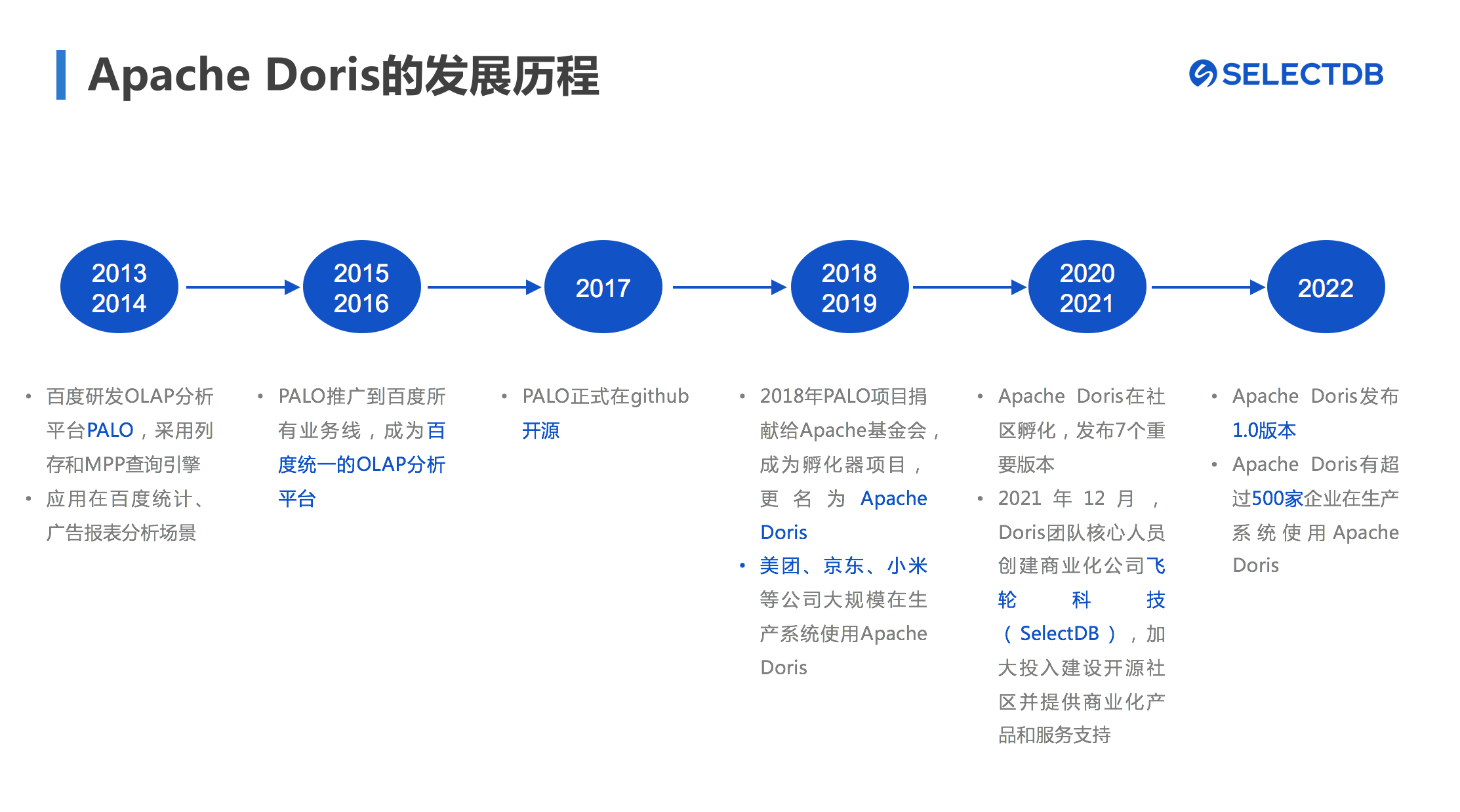
图1 Apache Doris发展历程
2、Apache Doris 在数据分析中的定位
作为一款极速易用的分析型数据库,Apache Doris提供了丰富的数据接入方式,存储在RDBMS、日志或业务系统等源端的数据可以通过多种方式导入Doris,也可以通过CDC、Kafka消息队列、流处理或批处理引擎(Flink、Storm、Spark)以及ETL工具等进行数据集成与处理后加载进Doris中,由Doris承接各种分析负载。与此同时,Apache Doris还可以以外部表的方式访问来自Elasticsearch、MySQL、PostgreSQL、Oracle等数据库以及Hive、Iceberg、Hudi等湖仓中的数据,可以加速湖仓查询或者进行跨数据源的联邦查询。
基于Apache Doris出色的查询性能和丰富的数据接入方式,Apache Doris可以高效支持多种业务场景,包括用户行为分析、日志检索分析、交易订单分析、自助BI平台、实时大屏及管理驾驶舱、用户画像等。
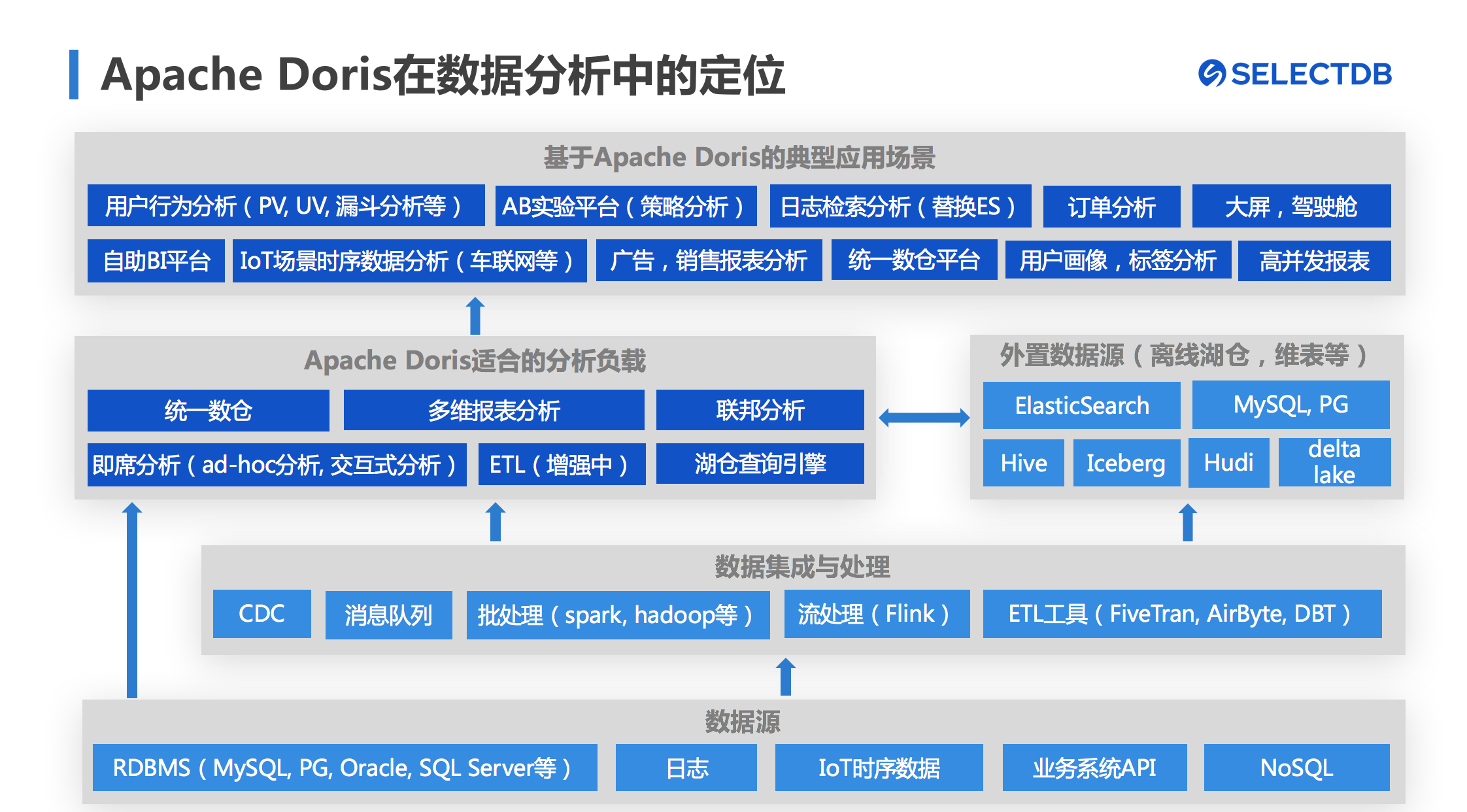
图2 Apache Doris在数据分析中的定位
3、Apache Doris 主要适合的分析负载
Apache Doris 适合的分析负载可以概括为以下四个场景:
多维报表分析:适合面向企业内部业务人员的多维报表,可以高效承载超高并发和毫秒级别查询延时的业务需求。
Ad-hoc分析:适合企业内部数据分析师在自助BI分析平台上进行交互式数据探索,查询模式灵活多变、数据吞吐要求高。
统一数仓:通过一个平台满足统一的数据仓库建设需求,简化繁琐的大数据技术栈,通过资源隔离来同时满足不同业务对数据处理和应用的多样需求。
湖仓加速和联邦分析:以外表的形式查询位于离线数仓hive以及数据湖Iceberg, Hudi, Delta lake中的数据,借助高效向量化执行引擎和优化器,实现数据分析效率数倍的提升。

图3 Apache Doris 适合分析负载的四个场景
目前,Apache Doris的开源用户遍布国内主流的互联网公司,除此之外、Apache Doris也被应用在物流、制造业,金融业,游戏等领域。

图4 Apache Doris 部分开源用户
4、Apache Doris 核心技术
Apache Doris 的第一个核心技术是简单易用。
首先是架构简单,Doris 只有两个主进程模块,一个是Frontend(FE),可以理解为 Doris 的管控节点,主要负责用户请求的接入、查询计划的解析、元数据的存储和集群管理相关工作。另一个是 Backend(BE),主要负责数据存储、查询计划的执行。Apache Doris 没有任何外部组件(如Zookeeper、HDFS等)依赖的,这种高度集成的架构设计极大的简化了一款分布式系统的运维成本。同时FE和BE这两类进程都是可以横向扩展的,并且扩容缩容过程非常简单。
其次是使用简单,Apache Doris支持标准SQL,可以支持聚合、排序、过滤以及多表Join、子查询、窗口函数等语法并支持UDF和UDAF。并且Apache Doris高度兼容MySQL协议,用户可以使用各类BI以及客户端工具轻松对接Doris。
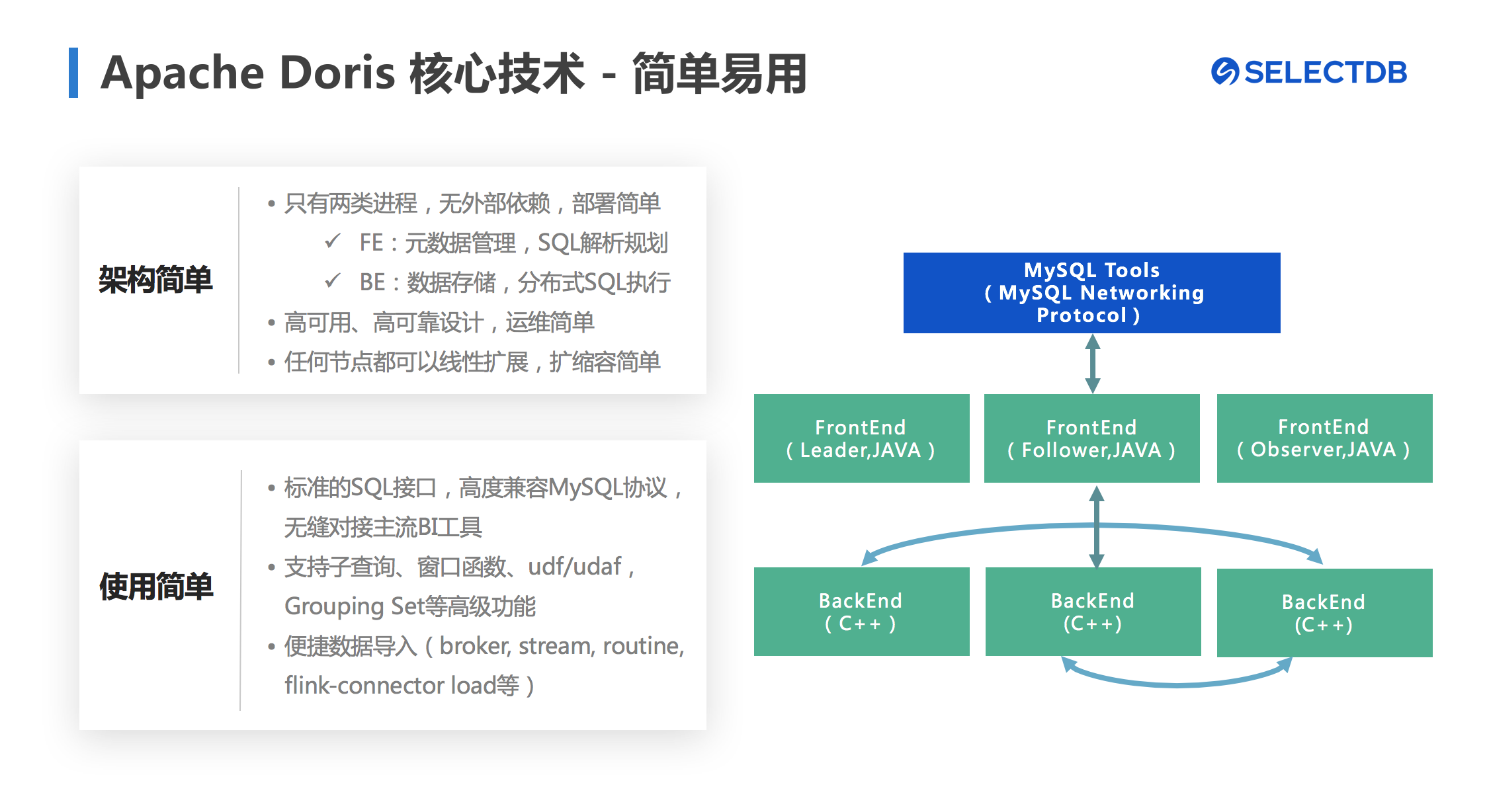
图5 Apache Doris 核心技术:简单易用
Apache Doris 的第二个核心技术是存储引擎的性能卓越。
首先表现在列式存储引擎,数据按照列存储,在查询时可以减少无用数据的扫描,并且通过多种编码方式实现了超高的数据压缩比,同时丰富的索引结构也可以进一步减少数据扫描量。当前Apache Doris 支持sorted short key、Min/max、Bloom filter、invert index等多种索数据引。
其次Apache Doris的性能卓越还表现在场景优化的存储模型,aggregate key模型可以通过预聚合大幅提升性能、unique key模型可以在相同key列上进行数据覆盖、实现行级别数据更新,duplicate key模型可以保存最明细数据。在数据模型之上,Apache Doris还提供了强一致的物化视图,物化视图表与基表的数据始终保持一致性,用户查询时还可以自动匹配最优的物化视图返回查询结果。

图6 Apache Doris 存储引擎的卓越性能
Apache Doris 的第三个核心技术是查询引擎的性能卓越。
首先是向量化执行引擎。向量化执行引擎是Apache Doris在1.0版本新增的功能,过去 Apache Doris 的 SQL 执行引擎是基于行式内存格式以及基于传统的火山模型进行设计的,在进行 SQL 算子与函数运算时存在非必要的开销,导致 Apache Doris 执行引擎的效率受限,并不适应现代 CPU 的体系结构。向量化执行引擎的目标是替换 Apache Doris 当前的行式 SQL 执行引擎,充分释放现代 CPU 的计算能力,突破在 SQL 执行引擎上的性能限制,发挥出极致的性能表现。
基于现代 CPU 的特点与火山模型的执行特点,向量化执行引擎重新设计了在列式存储系统的 SQL 执行引擎:
重新组织内存的数据结构,用 Column替换 Tuple,提高了计算时 Cache 亲和度,分支预测与预取内存的友好度
分批进行类型判断,在本次批次中都使用类型判断时确定的类型,将每一行类型判断的虚函数开销分摊到批量级别。
通过批级别的类型判断,消除了虚函数的调用,让编译器有函数内联以及 SIMD 优化的机会
基于以上特性,向量化执行引擎大大提高了 CPU 在 SQL 执行时的效率,经过内部测试,在款表聚合场景下性能有5-10倍的提升。
其次是基于分布式MPP的查询框架,Doris在执行SQL时可以在节点间与节点内并行执行,大幅提升了SQL执行的效率,同时也支持大表的shuffle 分布式Join,进一步利用多节点资源进行并行数据处理。
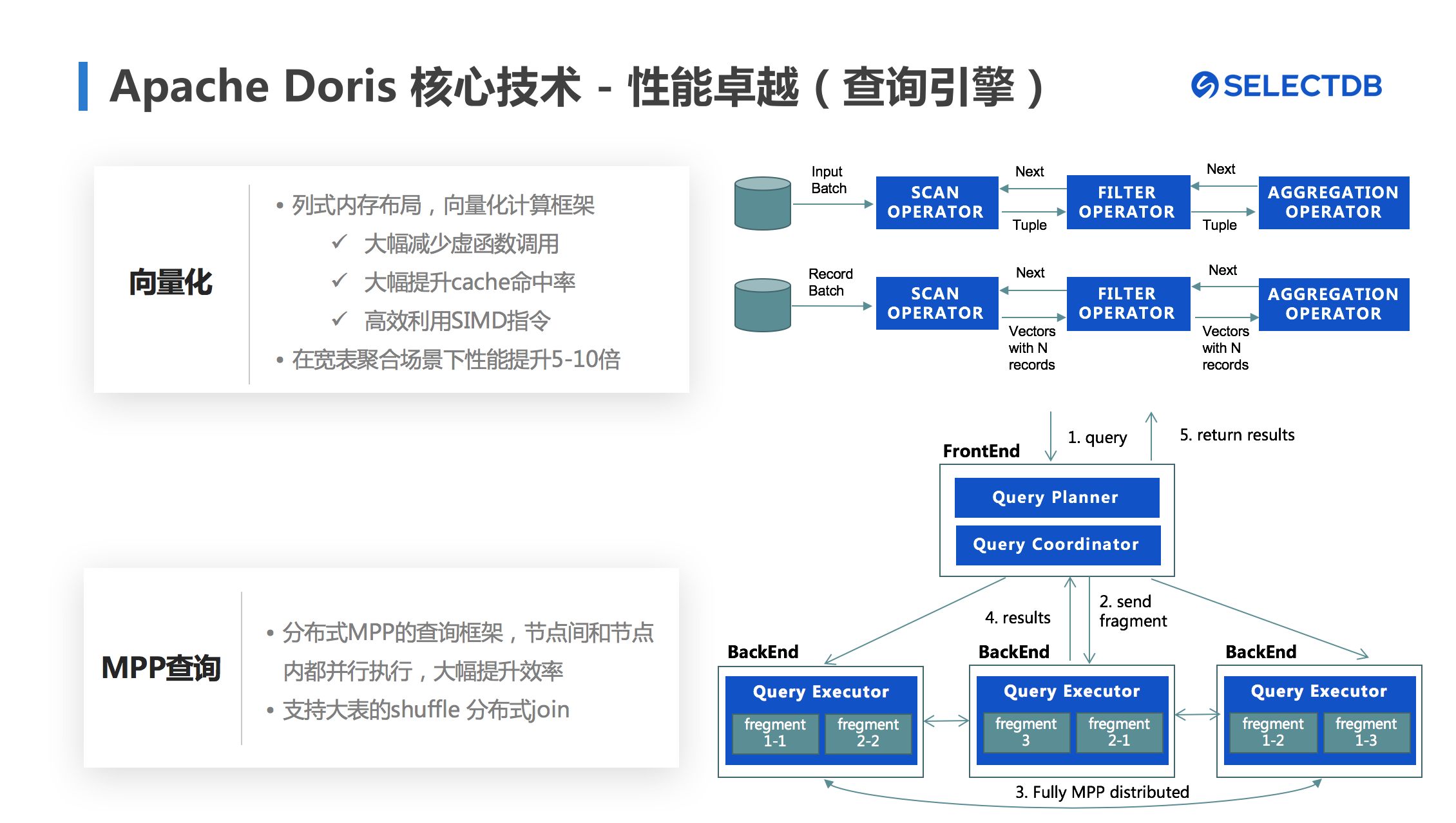
图7 Apache Doris 查询引擎的卓越性能
同时,我们对查询引擎的多种算子进行优化。例如对原本阻塞型的聚合算子做了自适应两阶段的优化,避免数据聚合时不必要的等待时间。同时针对Join算子设计了Runtime Fliter,在左右表进行Join的时候为连接列生成了过滤结构推给左表,大大减小了Probe Table需要传输的数据量。针对不同类型的数据,实现了In/Min/Max/Bloom Filter等不同类型的Filter,并且Filter可以穿透吓退到最底层的扫描节点。
Runtime Filter是非常重要的一个优化手段,经过我们测试,它对SSB标准测试数据集的部分查询有2-10倍提升。
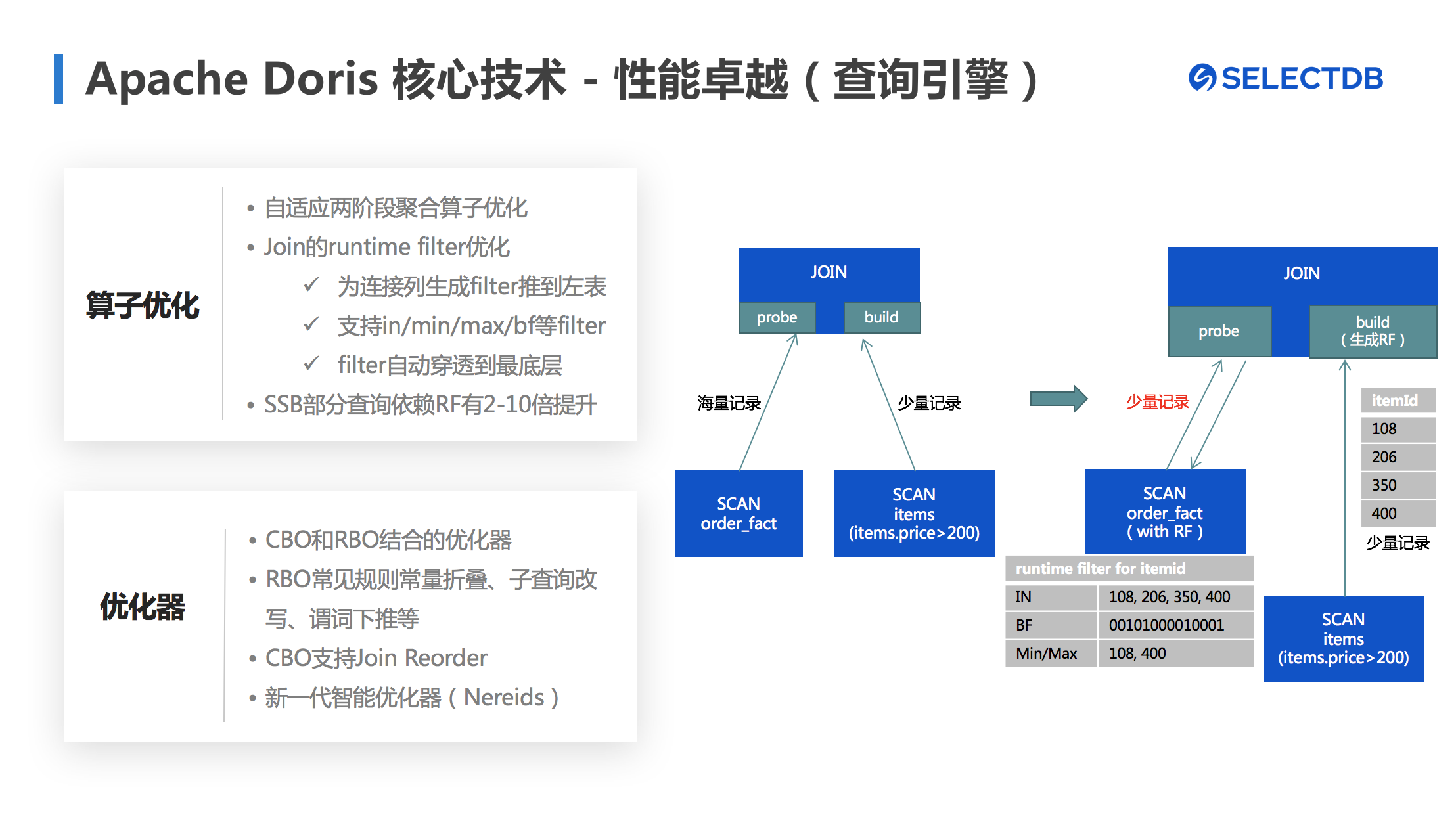
图8 Apache Doris 核心技术:查询引擎的卓越性能
稳定可靠是Apache Doris 的第四个核心技术,分别体现在元数据、数据管理、导入事务、备份恢复上这四个方面。
元数据管理:元数据采取内存结构+Log的方式存储,可以保证高性能、高可用和高可靠。Log存储使用BDBJE,同时使用类Paxos的一致性协议复制到多节点。FE可以通过配置多个节点来保证服务的高可用性以及查询性能的线型拓展。
数据管理:数据可以根据Range/List分区和Bucket Hash分桶后划分成多个Tablet(数据分片),每个Tablet都可以以多副本的形式复制到多台机器上存储,在节点下线或扩容时,数据分片能自动在多台节点上自动负载均衡。
导入事务:通过两阶段提交保证多表导入的原子性,使用MVCC机制来做并发控制,通过外部导入的最少一次以及Doris内部的lable机制保证最多一次,最终实现Exactly Once,数据不丢不重。
备份恢复:Doris支持将数据以文件的形式,备份到远端存储系统中。并通过恢复命令恢复到任意Doris集群基于此功能可以对数据定期的进行快照备份,也可以通过这个功能,在不同集群间进行数据迁移。

图9 Apache Doris 核心技术:稳定可靠
未来规划
Apache Doris 社区的发展逐渐繁荣,累计贡献者规模已经增至323名,并处于持续增长中;月活跃贡献者已接近70人,提交超过300个Commits。
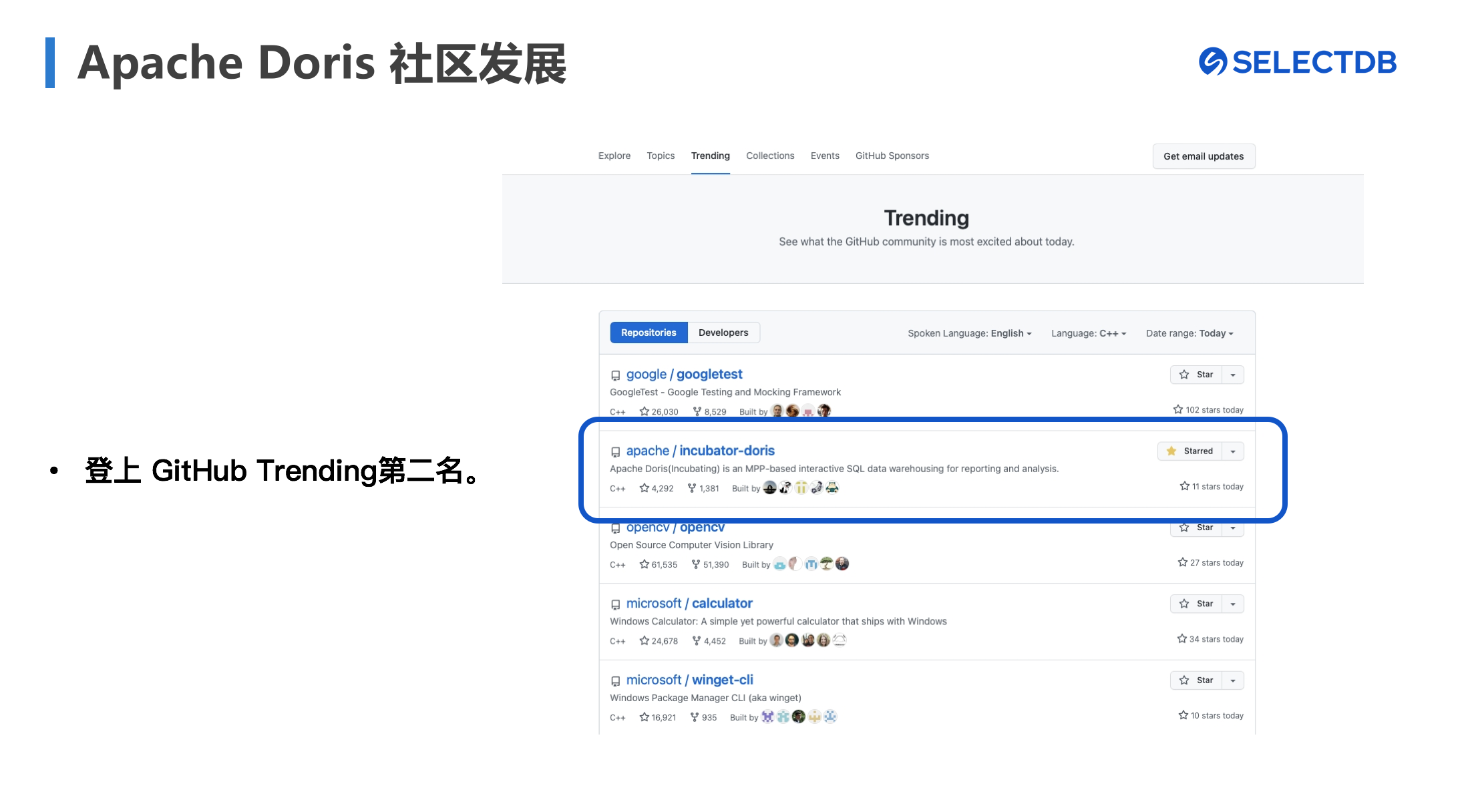
图10 Apache Doris 在C++项目中登上 GitHub Trending第二名
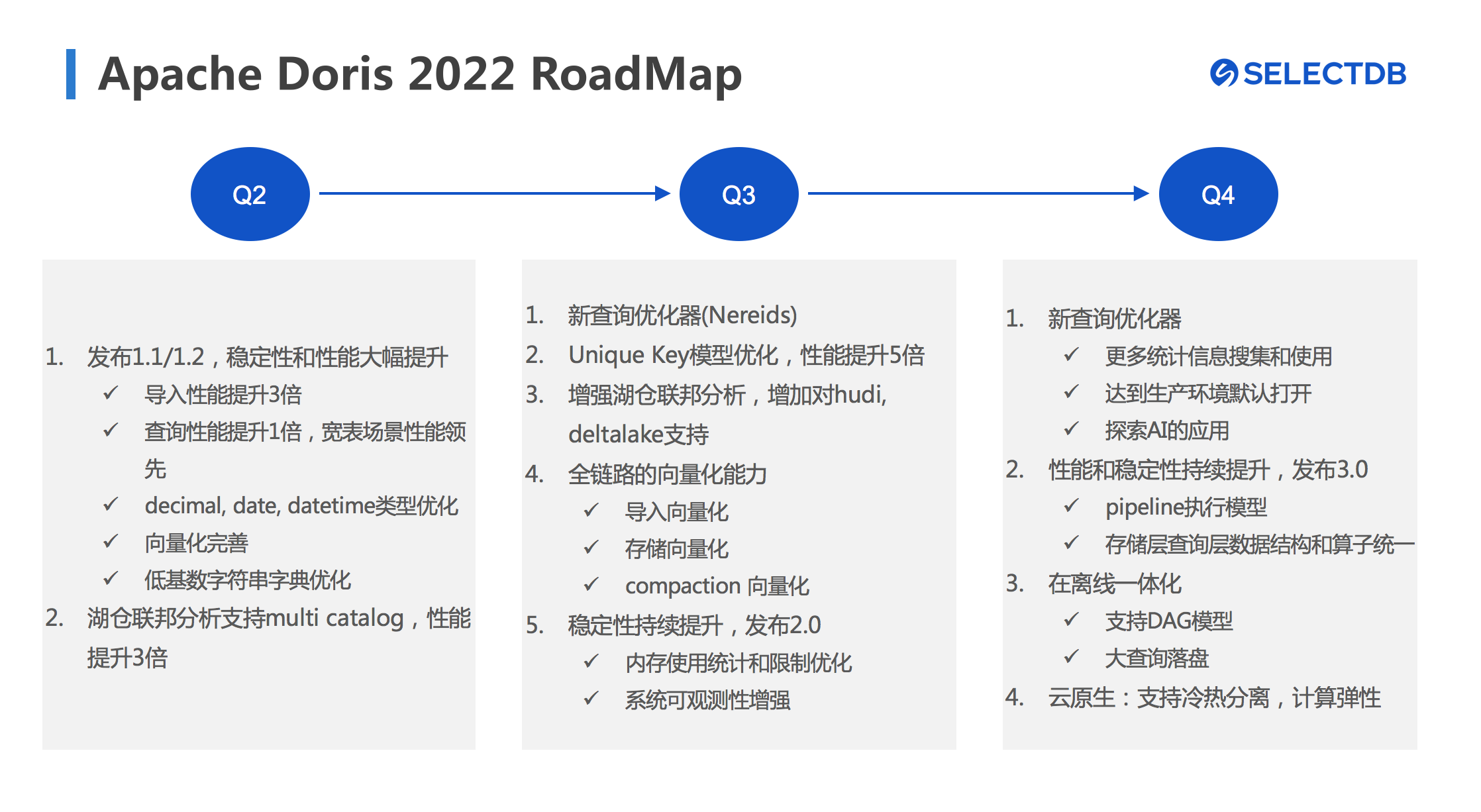
图11 Apache Doris 在2022年的发展规划
关于SelectDB
SelectDB是一家开源技术公司,致力于为Apache Doris社区提供一个由全职工程师、产品经理和支持工程师组成的团队,繁荣开源社区生态,打造实时分析型数据库领域的国际工业界标准。基于Doris研发新一代云原生实时数仓SelectDB,运行云上,为用户和客户提供开箱即用的能力。
目前公司已经完成天使轮和天使+轮融资,融资金额达3亿元人民币。
以下是我们的联系方式,我们很高兴与热爱技术的你共同交流。我今天的分享就到这里,谢谢大家!

问答环节
分享结束后,衣国垒老师也耐心解答观众们在问答区提出的疑问,我们也在此整理成视频,供大家查看、学习。
问题一览
- 向量化引擎在支持simd上是怎么优化的?
- Doris可以替代Greenplum、ES、ClickHouse吗?
- Doris可以跑标准的TPCH和TPC-DS吗?有没有相关的测试脚本分享一下。
- 多个FE是什么机制,属于多主吗,多个FE如何同时处理客户端的增删改查的?
点击原文可查看问题回答视频:https://www.modb.pro/db/407457
以上就是我今天分享的全部内容,谢谢大家!
更多精彩内容,欢迎大家观看现场视频回放:
https://www.modb.pro/video/6388
- 查看原文:https://www.modb.pro/db/407457
- 查看【国产数据库沙龙】实时数仓专场文章、视频回放资源:https://www.modb.pro/topic/405214
欲了解更多可以进入墨天轮,围绕数据人的学习成长提供一站式的全面服务,打造集新闻资讯、在线问答、活动直播、在线课程、文档阅览、资源下载、知识分享及在线运维为一体的统一平台,持续促进数据领域的知识传播和技术创新。
关注官方公众号: 墨天轮、 墨天轮平台、墨天轮成长营、数据库国产化 、数据库资讯
墨天轮访谈 | SelectDB 衣国垒:Apache Doris(incubating)1.0版本特性解析与未来规划的更多相关文章
- Apache Spark 2.2.0 新特性详细介绍
本章内容: 待整理 参考文献: Apache Spark 2.2.0新特性详细介绍 Introducing Apache Spark 2.2
- Apache Flink 1.9.0版本新功能介绍
摘要:Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能.目前,Apache Flink 1.9 ...
- 如何高效解决 C++内存问题,Apache Doris 实践之路|技术解析
导读:Apache Doris 使用 C++ 语言实现了执行引擎,C++ 开发过程中,影响开发效率的一个重要因素是指针的使用,包括非法访问.泄露.强制类型转换等.本文将会通过对 Sanitizer 和 ...
- Apache Spark 2.3.0 重要特性介绍
文章标题 Introducing Apache Spark 2.3 Apache Spark 2.3 介绍 Now Available on Databricks Runtime 4.0 现在可以在D ...
- Apache Spark 2.2.0新特性介绍(转载)
这个版本是 Structured Streaming 的一个重要里程碑,因为其终于可以正式在生产环境中使用,实验标签(experimental tag)已经被移除.在流系统中支持对任意状态进行操作:A ...
- 如何理解Apache License, Version 2.0(整理)
如何理解Apache License, Version 2.0(整理) 问题: 最近看到apache发布了2.0版本的License.而且微软也以此发布了部分源代码.我对OpenSource不是特熟, ...
- Apache Pulsar 2.6.1 版本正式发布:2.6.0 功能增强版,新增 OAuth2 支持
在 Apache Pulsar 2.6.0 版本发布后的 2 个月,2020 年 8 月 21 日,Apache Pulsar 2.6.1 版本正式发布! Apache Pulsar 2.6.1 修复 ...
- [Apache Doris] Apache Doris 元数据设计及DDL操作源码阅读
元数据设计 如上图,Doris 的元数据主要存储4类数据: 用户数据信息.包括数据库.表的 Schema.分片信息等. 各类作业信息.如导入作业,Clone 作业.SchemaChange 作业等. ...
- Apache Dolphin Scheduler 3.0.1 发布,对核心及UI相关进行优化
点亮 ️ Star · 照亮开源之路 GitHub:https://github.com/apache/dolphinscheduler 版本发布 感谢本次的 Release Manager -- ...
- Apache Flume 1.7.0 发布,日志服务器
Apache Flume 1.7.0 发布了,Flume 是一个分布式.可靠和高可用的服务,用于收集.聚合以及移动大量日志数据,使用一个简单灵活的架构,就流数据模型.这是一个可靠.容错的服务. 本次更 ...
随机推荐
- 优化 GitHub 体验的浏览器插件「GitHub 热点速览」
上周,GitHub 有个"安全问题"--CFOR(Cross Fork Object Reference)冲上了热搜,该问题的表现是: 远程仓库的提交内容任何人可以访问,即使已被删 ...
- P1081 [NOIP2012 提高组] 开车旅行
思路: 首先令 \(nxt1_i\) 表示右侧最近的城市距离(\(id1_i\) 为编号),令 \(nxt2_i\) 表示右侧第二近的城市编号(\(id2_i\) 为编号):可以使用 set 找出离这 ...
- 如何在python同一应用下的多模块中共享变量
最近在考虑编码风格的问题,突然想到如何在一个python应用下的多个模块中共享一个变量.最早接触python还是在python2.5版本左右,那个时候由于python的import规则设定的问题导致本 ...
- git 如何删除一个文件名为nul的文件
前提 当我发现存在一个nul的文件,手动删除/移动它,都会提示ms-dos功能无效或文件过大.想一想这个nul应该是某个保留字,所以普通的方式不能删除 解决方案 https://stackoverfl ...
- Temperature 题解
前言 题目链接:洛谷:SPOJ:Hydro & bzoj. 题意简述 有一个长度为 \(n\) 的序列,每个位置值的范围为 \([L_i, R_i]\) 内,求原序列可能的最长不降子串长度. ...
- Opentelemetry collector用法
Opentelemetry collector用法 目录 Opentelemetry collector用法 Service Extensions healthcheckextension Pipel ...
- SMU Summer 2024 Contest Round 3
SMU Summer 2024 Contest Round 3 寻找素数对 题意 给你一个偶数,找到两个最接近的素数,其和等于该偶数. 思路 处理出 1e5 以内的素数,然后遍历,更新最接近的答案. ...
- AtCoder Beginner Contest 314
AtCoder Beginner Contest 314 - AtCoder A - 3.14 (atcoder.jp) 题目提供了100位,所以直接用字符串输出 #include <bits/ ...
- 为什么使用#define 而不是用enum定义常量
typedef enum { IOTAG_PORT__A = (0), IOTAG_PORT__B, IOTAG_PORT__C, IOTAG_PORT__F, IOTAG_PORT__ITEMS } ...
- ARM指令和Thumb指令的区别
ARM处理器的工作状态 https://blog.csdn.net/itismine/article/details/4753701?depth_1-utm_source=distribute.pc_ ...