Handing Incomplete Heterogeneous Data using VAEs
概
这篇文章利用VAE处理缺失数据, 以往的对缺失数据的处理往往是不区分连续离散, 数字符号的, 感觉这里利用分布的处理方式非常精彩.
主要内容
ELBO
首先, 既然是利用VAE, 那么就需要推导出相应的ELBO来.
文章首先假设数据\(x\)和隐变量之间关系满足:
\]
即\(x_n\)的各分量关于\(z_n\)的条件独立的.
进一步引入观测数据\(x^o\)和\(x^m\), 即
\left \{
\begin{array}{ll}
x_{nd}, & d \in \mathcal{O}_n \\
0, & d \in \mathcal{M}_n
\end{array}
\right ., \\
x^{m}_n = x_n - x_{n}^o.
\]
其中\(\mathcal{O}, \mathcal{M}\) 分别是观测的元素和缺失的元素位置, 且彼此是互斥的.
那么
\]
\]
则通过极大似然即可推出ELBO:
\log p(X^o)
&= \sum_{n} \mathbb{E}_{q(z_n|x_n^o)} \log \frac{p(x_n^o, z_n)}{q(z_n|x_n^o)} \frac{q(z_n|x_n^o)}{p(z_n|x^o_n)} \\
&\ge \sum_n \mathbb{E}_{q(z_n|x_n^o)} \log p(x_n^o|z_n)
- \sum_n \mathrm{KL}(q(z_n|x_n^o)\| p(z_n)).
\end{array}
\]
其中\(p(x_n^o|z_n)=\prod_{d \in \mathcal{O}_n} p(x_{nd}|z_n)\).
网络结构
从上面的假设就可以看出, 整体的VAE的结构是这样的:
- 观测数据\(x^o\)经过encoder得到\(\mu_q(x^o), \Sigma_q(x^o)\), 并从高斯分布中采样得到\(z\).
- 隐变量\(z\)经过独立的网络\(h_1, \cdots, h_d\)得到预测的数据\(\gamma_1, \gamma_2, \cdots, \gamma_d\), 这些用于构建各自的分布\(p(x_d|\gamma_d)\), 这个分布是数据的类型而不同.
不同的数据
这对不同的数据类型, 可以假设不同的分布\(p(x_d|\gamma_d)\), 这我认为是非常有趣的一个点.
- 如果\(x_d\)是实值变量, 则可以假设其为高斯分布:
\]
- 如果\(x_d \in \mathbb{R}^+\), 则
\]
- \(x_d \in \{0, 1, 2, \cdots \}\), 则假设poisson分布:
= \frac{\lambda_d(z)^{x_d} \exp (-\lambda_d(z_n))}{x_d!}.
\]
- 类别数据, \(\gamma_d \in \{h_{d0}(z), \cdots, h_{d(R-1)}(z)\}\)此时为logits, 最后的概率分布
\]
- Ordinal data
\]
其中
\]
HI-VAE
上述的假设有些过于强了, 为此, 作者做出了一些调整.
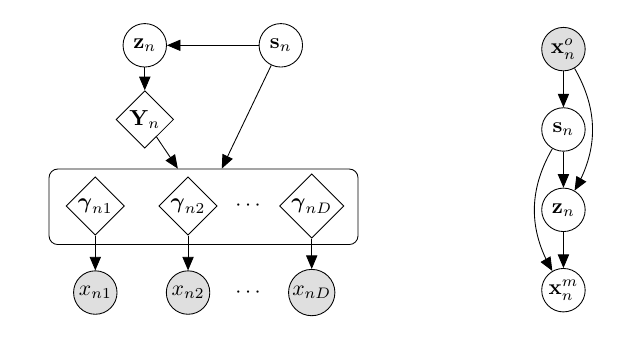
- 假设一个了一个混合的高斯先验: \(p(z|s_n)\);
- 隐变量需要先经过一个共同的变化得到\(Y_n\)再和\(s_n\)一起经过独立的网络得到\(\gamma_1, \gamma_2, \cdots, \gamma_d\).
个人感觉第二点的设计还是不错的.
代码
Handing Incomplete Heterogeneous Data using VAEs的更多相关文章
- RFC destination fails with error Incomplete Logon Data after system copy
1. 问题现象 1.1在system copy后,提示RFC报错Unable to configure STMS 2. 重要的参考文件: 2.1RFC passwords not available ...
- Interviews3D: APlatform for Interactive Handing of Massive Data Sets 读后感
横向比较: Inadequacy of current system design( 现代系统和一些软件的不足) 软件特点: Output sensitivity Out-of core data h ...
- Toward Scalable Systems for Big Data Analytics: A Technology Tutorial (I - III)
ABSTRACT Recent technological advancement have led to a deluge of data from distinctive domains (e.g ...
- MySQL vs. MongoDB: Choosing a Data Management Solution
原文地址:http://www.javacodegeeks.com/2015/07/mysql-vs-mongodb.html 1. Introduction It would be fair to ...
- Opaque data type--不透明类型
Opaque:对使用者来说,类型结构和机制明晰即为transparent,否则为Opaque In computer science, an opaque data type is a data ty ...
- 论文翻译:Data mining with big data
原文: Wu X, Zhu X, Wu G Q, et al. Data mining with big data[J]. IEEE transactions on knowledge and dat ...
- Understanding Variational Autoencoders (VAEs)
Understanding Variational Autoencoders (VAEs) 2019-09-29 11:33:18 This blog is from: https://towards ...
- (转) [it-ebooks]电子书列表
[it-ebooks]电子书列表 [2014]: Learning Objective-C by Developing iPhone Games || Leverage Xcode and Obj ...
- Magic Quadrant for Security Information and Event Management
https://www.gartner.com/doc/reprints?id=1-4LC8PAW&ct=171130&st=sb Summary Security and risk ...
随机推荐
- linux 实用指令压缩和解压类
linux 实用指令压缩和解压类 目录 linux 实用指令压缩和解压类 gzip/gunzip指令(不常用) zip/unzip指令 tar指令(常用) gzip/gunzip指令(不常用) 说明 ...
- SpringBoot Logback 日志配置
目录 前言 日志格式 日志输出 日志轮替 日志级别 日志分组 小结 前言 之前使用 SpringBoot 的时候,总是习惯于将日志框架切换为 Log4j2,可能是觉得比较靠谱,也可能年龄大了比较排斥新 ...
- 零基础学习java------day12------数组高级(选择排序,冒泡排序,二分查找),API(Arrays工具类,包装类,BigInteger等数据类型,Math包)
0.数组高级 (1)选择排序 它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的起始位置 ...
- Vue相关,vue父子组件生命周期执行顺序。
一.实例代码 父组件: <template> <div id="parent"> <child></child> </div& ...
- WebService学习总览
[1]WebService简介 https://blog.csdn.net/xtayfjpk/article/details/12256663 [2]CXF中Web服务请求处理流程 https://b ...
- 【Linux】【Services】【VersionControl】git-daemon, httpd, mysql搭建带认证的gitserver
1. 简介: 比较低端的gitserver,使用centos自带的git-daemon搭建gitserver,使用httpd做上传和下载,利用mod_auth_mysql做认证 2. 环境 # Apa ...
- mysql触发器实例说明
触发器是一类特殊的事务 ,可以监视某种数据操作(insert/update/delete),并触发相关操作(insert/update/delete). 看以下事件: 完成下单与减少库存的逻辑 Ins ...
- 监测linux系统负载与CPU、内存、硬盘、用户数的shell脚本
本节主要内容: 利用Shell脚本来监控Linux系统的负载.CPU.内存.硬盘.用户登录数. 一.linux系统告警邮件脚本 # vim /scripts/sys-warning.sh #!/bin ...
- Copy elision in C++
Copy elision (or Copy omission) is a compiler optimization technique that avoids unnecessary copying ...
- Linux运维实战之磁盘分区、格式化及挂载(一)
在网络系统中,磁盘和文件系统管理是两个非常基本.同时也是非常重要的管理任务,特别是文件系统管理,因为它与用户权限和整个网络系统的安全息息相关.本次博文的主题是关于Linux系统中磁盘分区.格式化及挂载 ...