Java并发容器篇
作者:汤圆
个人博客:javalover.cc
前言
断断续续一个多月,也写了十几篇原创文章,感觉真的很不一样;
不能说技术有很大的进步,但是想法确实跟以前有所不同;
还没开始的时候,想着要学的东西太多,总觉得无从下手;
但是当你真正下定决心去做了几天后,就会发现 原来路真的是一步步走出来的;
如果总是原地踏步东张西望,对自己不会有帮助;
好了,下面开始今天的话题,并发容器篇
简介
前面我们介绍了同步容器,它的很大一个缺点就是在高并发下的环境下,性能差;
针对这个,于是就有了专门为高并发设计的并发容器类;
因为并发容器类都位于java.util.concurrent下,所以我们也习惯把并发容器简称为JUC容器;
相对应的还有JUC原子类、JUC锁、JUC工具类等等(这些后面再介绍)
今天就让我们简单来了解下JUC中并发容器的相关知识点
文章如果有问题,欢迎大家批评指正,在此谢过啦
目录
- 什么是并发容器
- 为什么会有并发容器
- 并发容器、同步容器、普通容器的区别
正文
1. 什么是并发容器
并发容器是针对高并发专门设计的一些类,用来替代性能较低的同步容器
常见的并发容器类如下所示:
这节我们主要以第一个ConcurrentHashMap为例子来介绍并发容器
其他的以后有空会单独开篇分析
2. 为什么会有并发容器
其实跟同步容器的出现的道理是一样的:
同步容器是为了让我们在编写多线程代码时,不用自己手动去同步加锁,为我们解放了双手,去做更多有意义的事情(有意义?双手?);
而并发容器则又是为了提高同步容器的性能,相当于同步容器的升级版;
这也是为什么Java一直在被人唱衰,却又一直没有衰退的原因(大佬们也很焦虑啊!!!);
不过话说回来,大佬们焦虑地有点过头了;不敢想Java现在都升到16级了,而我们始终还在8级徘徊。
3. 并发容器、同步容器、普通容器的区别
这里的普通容器,指的是没有同步和并发的容器类,比如HashMap
三个对比着来介绍,这样会更加清晰一点
下面我们分别以HashMap, HashTable, ConcurrentHashMap为例来介绍
性能分析
下面我们来分析下他们三个之间的性能区别:
注:这里普通容器用的是单线程来测试的,因为多线程不安全,所以我们就不考虑了
有的朋友可能会说,你这不公平啊,可是没办法呀,谁让她多线程不安全呢。
如果非要让我在安全和性能之间选一个的话,那我选 ConcurrentHashMap(我都要)
他们三个之间的关系,如下图
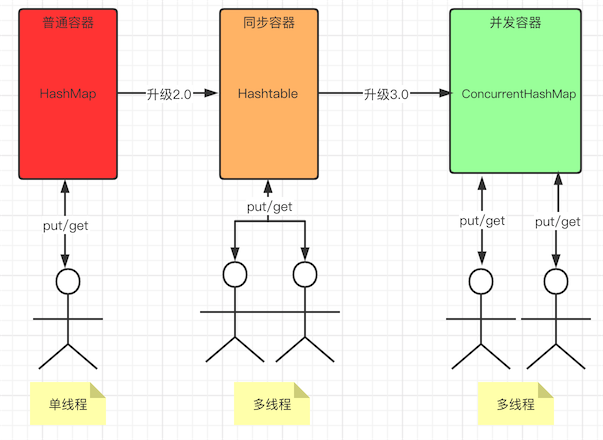
(红色表示堵的厉害,橙色表示堵的一般,绿色表示畅通)
可以看到:
在单线程中操作普通容器时,代码都是串行执行的,同一时刻只能put或get一个数据到容器中
在多线程中操作同步容器时,可以多个线程排队去执行,同一时刻也是只能put或get一个数据到同步容器中
在多线程中操作并发容器时,可以多个线程同时去执行,也就是说同一时刻可以有多个线程去put或get多个数据到并发容器中(可同时读读,可同时读写,可同时写写-有可能会阻塞,这里是以ConcurrentHashMap为参考)
下面我们用代码来复现下上面图中所示的效果(慢-中-快)
- HashMap 测试方法
public static void hashMapTest(){
Map<String, String> map = new HashMap<>();
long start = System.nanoTime();
// 创建10万条数据 单线程
for (int i = 0; i < 100_000; i++) {
// 用UUID作为key,保证key的唯一
map.put(UUID.randomUUID().toString(), String.valueOf(i));
map.get(UUID.randomUUID().toString());
}
long end = System.nanoTime();
System.out.println("hashMap耗时:");
System.out.println(end - start);
}
- HashTable 测试方法
public static void hashTableTest(){
Map<String, String> map = new Hashtable<>();
long start = System.nanoTime();
// 创建10个线程 - 多线程
for (int i = 0; i < 10; i++) {
new Thread(()->{
// 每个线程创建1万条数据
for (int j = 0; j < 10000; j++) {
// UUID保证key的唯一性
map.put(UUID.randomUUID().toString(), String.valueOf(j));
map.get(UUID.randomUUID().toString());
}
}).start();
}
// 这里是为了等待上面的线程执行结束,之所以判断>2,是因为在IDEA中除了main thread,还有一个monitor thread
while (Thread.activeCount()>2){
Thread.yield();
}
long end = System.nanoTime();
System.out.println("hashTable耗时:");
System.out.println(end - start);
}
- concurrentHashMap 测试方法
public static void concurrentHashMapTest(){
Map<String, String> map = new ConcurrentHashMap<>();
long start = System.nanoTime();
// 创建10个线程 - 多线程
for (int i = 0; i < 10; i++) {
new Thread(()->{
// 每个线程创建1万条数据
for (int j = 0; j < 10000; j++) {
// UUID作为key,保证唯一性
map.put(UUID.randomUUID().toString(), String.valueOf(j));
map.get(UUID.randomUUID().toString());
}
}).start();
}
// 这里是为了等待上面的线程执行结束,之所以判断>2,是因为在IDEA中除了main thread,还有一个monitor thread
while (Thread.activeCount()>2){
Thread.yield();
}
long end = System.nanoTime();
System.out.println("concurrentHashMap耗时:");
System.out.println(end - start);
}
- main 方法分别执行上面的三个测试
public static void main(String[] args) {
hashMapTest();
hashTableTest();
while (Thread.activeCount()>2){
Thread.yield();
}
concurrentHashMapTest();
}
运行可以看到,如下结果(运行多次,数值可能会变好,但是规律基本一致)
hashMap耗时:
754699874 (慢)
hashTable耗时:
609160132(中)
concurrentHashMap耗时:
261617133(快)
结论就是,正常情况下的速度:普通容器 < 同步容器 < 并发容器
但是也不那么绝对,因为这里插入的key都是唯一的,所以看起来正常一点
那如果我们不正常一点呢?比如极端到BT的那种
下面我们就不停地插入同一条数据,上面的所有put/get都改为下面的代码:
map.put("a", "a");
map.get("a");
运行后,你会发现,又是另外一个结论(大家感兴趣的可以敲出来试试)
不过结论不结论的,意义不是很大;
锁分析
普通容器没锁
同步容器中锁的都是方法级别,也就是说锁的是整个容器,我们先来看下HashTable的锁
public synchronized V put(K key, V value) {}
public synchronized V remove(Object key) {}
可以看到:因为锁是内置锁,锁住的是整个容器
所以我们在put的时候,其他线程都不能put/get
而我们在get的时候,其他线程也都不能put/get
所以同步容器的效率会比较低
并发容器,我们以1.7的ConcurrentHashMap为例来说下(之所以选1.7,是因为它里面涉及的内容都是前面章节介绍过的)
它的锁粒度很小,它不会给整个容器上锁,而是分段上锁;
分段的依据就是key.hash,根据不同的hash值映射到不同的段(默认16个段),然后插入数据时,根据这个hash值去给对应的段上锁,此时其他段还是可以被其他线程读写的;
所以这就是文章开头所说的,为啥ConcurrentHashMap会支持多个线程同时写(因为只要插入的key的hashCode不会映射到同一个段里,那就不会冲突,此时就可以同时写)
读因为没有上锁,所以当然也支持同时读
如果读操作没有锁,那么它怎么保证数据的一致性呢?
答案就是以前介绍过的volatile(保证可见性、禁止重排序),它修饰在节点Node和值val上,保证了你get的值永远是最新的
下面是ConcurrentHashMap部分源码,可以看到val和net节点都是volatile类型
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
总结下来就是:并发容器ConcurrentHashMap中,多个线程可同时读,多个线程可同时写,多个线程同时读和写
总结
- 什么是并发容器:并发容器是针对高并发专门设计的一些类,用来替代性能较低的同步容器
- 为什么会有并发容器:为了提高同步容器的性能
- 并发容器、同步容器、普通容器的区别:
- 性能:高 - 中 - 低
- 锁:粒度小 - 粒度大 - 无
- 场景:高并发 - 中并发 - 单线程
参考内容:
- 《Java并发编程实战》
- 《实战Java高并发》
- 《深入理解Java虚拟机》
后记
我这里介绍的都是比较浅的东西,其实并发容器的知识深入起来有很多;
但是因为这节是并发系列的比较靠前的,还有很多东西没涉及到,所以就分析地比较浅;
等到并发系列的内容都涉及地差不多了,再回过头来深入分析。
写在最后:
愿你的意中人亦是中意你之人。
Java并发容器篇的更多相关文章
- java 并发容器一之BoundedConcurrentHashMap(基于JDK1.8)
最近开始学习java并发容器,以补充自己在并发方面的知识,从源码上进行.如有不正确之处,还请各位大神批评指正. 前言: 本人个人理解,看一个类的源码要先从构造器入手,然后再看方法.下面看Bounded ...
- Java并发编程系列-(5) Java并发容器
5 并发容器 5.1 Hashtable.HashMap.TreeMap.HashSet.LinkedHashMap 在介绍并发容器之前,先分析下普通的容器,以及相应的实现,方便后续的对比. Hash ...
- Java 并发系列之六:java 并发容器(4个)
1. ConcurrentHashMap 2. ConcurrentLinkedQueue 3. ConcurrentSkipListMap 4. ConcurrentSkipListSet 5. t ...
- 《Java并发编程的艺术》第6/7/8章 Java并发容器与框架/13个原子操作/并发工具类
第6章 Java并发容器和框架 6.1 ConcurrentHashMap(线程安全的HashMap.锁分段技术) 6.1.1 为什么要使用ConcurrentHashMap 在并发编程中使用Has ...
- 【Java面试】- 并发容器篇
JDK 提供的并发容器 ConcurrentHashMap: 线程安全的 HashMap CopyOnWriteArrayList: 线程安全的 List,在读多写少的场合性能非常好,远远好于 Vec ...
- Java并发指南14:Java并发容器ConcurrentSkipListMap与CopyOnWriteArrayList
原文出处http://cmsblogs.com/ 『chenssy』 到目前为止,我们在Java世界里看到了两种实现key-value的数据结构:Hash.TreeMap,这两种数据结构各自都有着优缺 ...
- 【Java并发工具类】Java并发容器
前言 Java并发包有很大一部分都是关于并发容器的.Java在5.0版本之前线程安全的容器称之为同步容器.同步容器实现线程安全的方式:是将每个公有方法都使用synchronized修饰,保证每次只有一 ...
- java并发容器(Map、List、BlockingQueue)
转发: 大海巨浪 Java库本身就有多种线程安全的容器和同步工具,其中同步容器包括两部分:一个是Vector和Hashtable.另外还有JDK1.2中加入的同步包装类,这些类都是由Collectio ...
- java并发容器
同步容器将所有对容器状态的访问都串行化,以实现线程安全性.这种方式的缺点是严重降低并发性.Java 5.0提供了多种并发容器来改进同步容器的性能.如ConcurrentHashMap代替同步且基于散列 ...
随机推荐
- python的模块(module)和包(package)机制:import和from..import..
在python用import或者from...import来导入相应的模块. 模块其实就一些函数和类的集合文件,它能实现一些相应的功能,当我们需要使用这些功能的时候,直接把相应的模块导入到我们的程序中 ...
- 关于搬运CSDN上学生信息管理系统的阅读与二次开发
关于本篇博客内容,我大概分成了三个部分进行讲述:对于源代码的解读.二次重开发后程序的介绍和自己在做完对他人代码的解读和重开发后自己的一些感想. 一. 源代码的解读 在本部分的解读中主要分为三部分:该 ...
- linux库文件编程
参考博文链接: https://www.cnblogs.com/guochaoxxl/p/7141447.html https://www.cnblogs.com/tuhooo/p/8757192.h ...
- Balanced Diet Gym - 102220B
题目链接:https://vjudge.net/problem/Gym-102220B 题意:每组数据 给了 N和M表示有M种类型的糖果,这些糖果一共N个.接下了是 M 组数据,表示如果你选第 i 中 ...
- windows创建签名文件pfx
https://stackoverflow.com/questions/84847/how-do-i-create-a-self-signed-certificate-for-code-signing ...
- 微服务面试必问的Dubbo,这么详细还怕自己找不到工作?
大家好,我是小羽. Dubbo 起源于阿里巴巴,对于我们做电商开发的人来说,基本是首选的技术,那么为何一个区区 soa 服务治理框架,会受到这么多人的青睐呢? 今天就跟着小羽一起看看这个微服务框架之一 ...
- 201871030102_崔红梅 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
项目 内容 课程班级博客链接 班级博客 这个作业要求链接 作业要求 我的课程学习目标 1.体验软件项目开发中的两人合作,练习结对编程2. 掌握Github协作开发程序的操作方法.3.阅读<现代软 ...
- DDD实战让中台和微服务的落地如虎添翼
微服务到底怎么拆分和设计才算合理,拆多小才叫微服务?有没有好的方法来指导微服务和中台的设计呢? 深入DDD的核心知识体系与设计思想,带你掌握一套完整而系统的基于DDD的微服务拆分与设计方法,助力落地边 ...
- Spring Authorization Server 全新授权服务器整合使用
前言 Spring Authorization Server 是 Spring 团队最新开发适配 OAuth 协议的授权服务器项目,旨在替代原有的 Spring Security OAuth 经过半年 ...
- C++ 内存模型之单独编译
单独编译得意义 将一个程序分成多个文件按保存,如果过对程序修改,找到要修改得文件进行修改后重新编译,则可以之重新编译该文件,然后后将他于其他文件得编译版本链接,是的大程序得管理更加高效便捷. 将单文件 ...