hive DML 操作
数据导入
load data [local] inpath '数据的 path' [overwrite] into table
student [partition (partcol1=val1,…)];
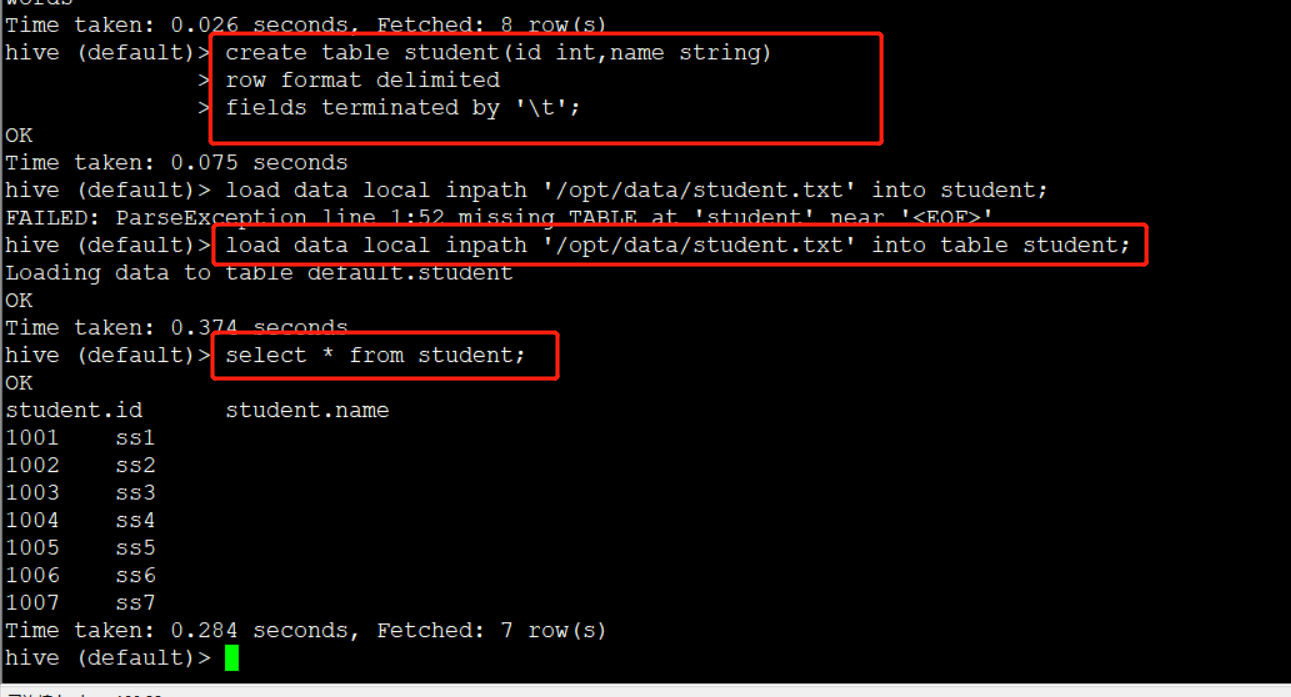
创建表
create table student(id string, name string) row format
delimited fields terminated by '\t';
load data local inpath
'/opt/module/data/student.txt' into table default.student;

(0)创建一张表
create table student(id string, name string) row format
delimited fields terminated by '\t';
(1)加载本地文件到 hive
load data local inpath
'/opt/module/hive/datas/student.txt' into table default.student;
(2)加载 HDFS 文件到 hive 中
上传文件到 HDFS
hive (default)> dfs -put /opt/module/hive/data/student.txt
/user/atguigu/hive;
加载 HDFS 上数据
load data inpath '/user/atguigu/hive/student.txt' into table default.student;
(3)加载数据覆盖表中已有的数据
上传文件到 HDFS
hive (default)> dfs -put /opt/module/data/student.txt /user/atguigu/hive;
加载数据覆盖表中已有的数据
hive (default)> load data inpath '/user/atguigu/hive/student.txt'
overwrite into table default.student;
1)创建一张表
hive (default)> create table student_par(id int, name string) row format
delimited fields terminated by '\t';
2)基本插入数据
hive (default)> insert into table student_par
values(1,'wangwu'),(2,'zhaoliu');
3)基本模式插入(根据单张表查询结果)
hive (default)> insert overwrite table student_par
select id, name from student where month='201709';
insert into:以追加数据的方式插入到表或分区,原有数据不会删除
insert overwrite:会覆盖表中已存在的数据
注意:insert 不支持插入部分字段
4)多表(多分区)插入模式(根据多张表查询结果)
hive (default)> from student
insert overwrite table student partition(month='201707')
select id, name where month='201709'
insert overwrite table student partition(month='201706')
select id, name where month='201709';
根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student3
as select id, name from student;
4.创建表时通过 Location 指定加载数据路径
1)上传数据到 hdfs 上
hive (default)> dfs -mkdir /student;
hive (default)> dfs -put /opt/module/datas/student.txt /student; 2)创建表,并指定在 hdfs 上的位置
hive (default)> create external table if not exists student5(
id int, name string
)
row format delimited fields terminated by '\t'
location '/student;
Import 数据到指定 Hive 表中
数据导出
1 Insert 导出
hive (default)> insert overwrite local directory
'/opt/module/hive/data/export/student'
select * from student;
hive(default)>insert overwrite local directory
'/opt/module/hive/data/export/student1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
hive (default)> insert overwrite directory '/user/atguigu/student2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
2 Hadoop 命令导出到本地
hive (default)> dfs -get /user/hive/warehouse/student/student.txt
/opt/module/data/export/student3.txt;
Export 导出到 HDFS 上
清除表中数据(Truncate)
注意:Truncate 只能删除管理表,不能删除外部表中数据
查询
hive DML 操作的更多相关文章
- hive DML操作
1.数据导入 1)向表中装载数据(load) 语法 hive> load data [local] inpath '/opt/module/datas/student.txt' [overwri ...
- Hive DDL、DML操作
• 一.DDL操作(数据定义语言)包括:Create.Alter.Show.Drop等. • create database- 创建新数据库 • alter database - 修改数据库 • dr ...
- 入门大数据---Hive常用DML操作
Hive 常用DML操作 一.加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename ...
- 23-hadoop-hive的DDL和DML操作
跟mysql类似, hive也有 DDL, 和 DML操作 数据类型: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ ...
- Hive数据库操作
Hive数据结构 除了基本数据类型(与java类似),hive支持三种集合类型 Hive集合类型数据 array.map.structs hive (default)> create table ...
- Vertica并发DML操作性能瓶颈的产生与优化(转)
文章来源:中国联通网研院网优网管部IT技术研究团队 作者:陆昕 1. 引言 众所周知,MPP数据库以其分布式的超大存储能力以及列式的高速汇总能力,已经成为大数据分析比不可少的工具.Vertica就是这 ...
- salesforce 零基础开发入门学习(三)sObject简单介绍以及简单DML操作(SOQL)
salesforce中对于数据库操作和JAVA等语言对于数据库操作是有一定区别的.salesforce中的数据库使用的是Force.com 平台的数据库,数据表一行数据可以理解成一个sObject变量 ...
- Sql Server之旅——第十站 看看DML操作对索引的影响
我们都知道建索引是需要谨慎的,当只有利大于弊的时候才适合建,我们也知道建索引是需要维护成本的,这个维护也就在于DML操作了, 下面我们具体看看到底DML对索引都有哪些内幕.... 一:delete操作 ...
- spark使用Hive表操作
spark Hive表操作 之前很长一段时间是通过hiveServer操作Hive表的,一旦hiveServer宕掉就无法进行操作. 比如说一个修改表分区的操作 一.使用HiveServer的方式 v ...
随机推荐
- 【LeetCode】682. Baseball Game 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 使用栈模拟 日期 题目地址:https://leet ...
- 【LeetCode】47. Permutations II 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 方法一:递归 方法二:回溯法 日期 题目地址:htt ...
- 【LeetCode】707. Design Linked List 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 一、SQL高级语句
摘抄别的博主的博客主要总去CSDN看不太方便自己整理一下加深记忆! 导入文件至数据库 #将脚本导入 source 加文件路径 mysql> source /backup/test.sql; se ...
- Proximal Algorithms 1 介绍
目录 定义 解释 图形解释 梯度解释 一个简单的例子 Proximal Algorithms 定义 令\(f: \mathrm{R}^n \rightarrow \mathrm{R} \cup \{+ ...
- gojs 实用高级用法
大家,新年好! 历史文章: 数据可视化 gojs 简单使用介绍 gojs 如何实现虚线(蚂蚁线)动画? 本文介绍的是在使用 gojs 制作图的过程中,你可能会碰到的问题的一些解决方案. gojs 是一 ...
- 日志收集系统系列(四)之LogAgent优化
实现功能 logagent根据etcd的配置创建多个tailtask logagent实现watch新配置 logagent实现新增收集任务 logagent删除新配置中没有的那个任务 logagen ...
- Vue系列教程(三)之vue-cli脚手架的使用
一.Vue-cli的环境准备 目的:(1)快速管理依赖 (2)确定项目结构 1.安装node.js Node.js是一个可以让前端运行在服务器上的一个工. 下载:https://nodejs.org/ ...
- PAT 乙级 1001. 害死人不偿命的(3n+1)猜想 (15)(C语言描述)
卡拉兹(Callatz)猜想: 对任何一个自然数n,如果它是偶数,那么把它砍掉一半:如果它是奇数,那么把(3n+1)砍掉一半.这样一直反复砍下去,最后一定在某一步得到n=1.卡拉兹在1950年的世界数 ...
- 网络协议学习笔记(四)传输层的UDP和TCP
概述 传输层里比较重要的两个协议,一个是 TCP,一个是 UDP.对于不从事底层开发的人员来讲,或者对于开发应用的人来讲,最常用的就是这两个协议.由于面试的时候,这两个协议经常会被放在一起问,因而我在 ...