大数据开发-Flink-数据流DataStream和DataSet
Flink主要用来处理数据流,所以从抽象上来看就是对数据流的处理,正如前面大数据开发-Flink-体系结构 && 运行架构提到写Flink程序实际上就是在写DataSource、Transformation、Sink.
DataSource是程序的数据源输入,可以通过StreamExecutionEnvironment.addSource(sourceFuntion)为程序
添加一个数据源Transformation是具体的操作,它对一个或多个输入数据源进行计算处理,比如Map、FlatMap和Filter等操作
Sink是程序的输出,它可以把Transformation处理之后的数据输出到指定的存储介质中
DataStream的三种流处理Api
DataSource
Flink针对DataStream提供了两种实现方式的数据源,可以归纳为以下四种:
基于文件
readTextFile(path)读取文本文件,文件遵循TextInputFormat逐行读取规则并返回基于Socket
socketTextStream从Socket中读取数据,元素可以通过一个分隔符分开基于集合
fromCollection(Collection)通过Java的Collection集合创建一个数据流,集合中的所有元素必须是相同类型的,需要注意的是,如果集合里面的元素要识别为POJO,需要满足下面的条件该类有共有的无参构造方法
该类是共有且独立的(没有非静态内部类)
类(及父类)中所有的不被static、transient修饰的属性要么有公有的(且不被final修饰),要么是包含公有的getter和setter方法,这些方法遵循java bean命名规范
总结:上面的要求其实就是为了让Flink可以方便地序列化和反序列化这些对象为数据流
自定义Source
使用
StreamExecutionEnvironment.addSource(sourceFunction)将一个流式数据源加到程序中,具体这个sourceFunction是为非并行源implements SourceFunction,或者为并行源implements ParallelSourceFunction接口,或者extends RichParallelSourceFunction,对于自定义Source,Sink, Flink内置了下面几种Connector
| 连接器 | 是否提供Source支持 | 是否提供Sink支持 |
|---|---|---|
| Apache Kafka | 是 | 是 |
| ElasticSearch | 否 | 是 |
| HDFS | 否 | 是 |
| Twitter Streaming PI | 是 | 否 |
对于Source的使用,其实较简单,这里给一个较常用的自定义Source的KafaSource的使用例子。更多相关源码可以查看:
package com.hoult.stream;
public class SourceFromKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
String topic = "animalN";
Properties props = new Properties();
props.put("bootstrap.servers", "linux121:9092");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), props);
DataStreamSource<String> data = env.addSource(consumer);
SingleOutputStreamOperator<Tuple2<Long, Long>> maped = data.map(new MapFunction<String, Tuple2<Long, Long>>() {
@Override
public Tuple2<Long, Long> map(String value) throws Exception {
System.out.println(value);
Tuple2<Long,Long> t = new Tuple2<Long,Long>(0l,0l);
String[] split = value.split(",");
try{
t = new Tuple2<Long, Long>(Long.valueOf(split[0]), Long.valueOf(split[1]));
} catch (Exception e) {
e.printStackTrace();
}
return t;
}
});
KeyedStream<Tuple2<Long,Long>, Long> keyed = maped.keyBy(value -> value.f0);
//按照key分组策略,对流式数据调用状态化处理
SingleOutputStreamOperator<Tuple2<Long, Long>> flatMaped = keyed.flatMap(new RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>>() {
ValueState<Tuple2<Long, Long>> sumState;
@Override
public void open(Configuration parameters) throws Exception {
//在open方法中做出State
ValueStateDescriptor<Tuple2<Long, Long>> descriptor = new ValueStateDescriptor<>(
"average",
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {
}),
Tuple2.of(0L, 0L)
);
sumState = getRuntimeContext().getState(descriptor);
// super.open(parameters);
}
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, Long>> out) throws Exception {
//在flatMap方法中,更新State
Tuple2<Long, Long> currentSum = sumState.value();
currentSum.f0 += 1;
currentSum.f1 += value.f1;
sumState.update(currentSum);
out.collect(currentSum);
/*if (currentSum.f0 == 2) {
long avarage = currentSum.f1 / currentSum.f0;
out.collect(new Tuple2<>(value.f0, avarage));
sumState.clear();
}*/
}
});
flatMaped.print();
env.execute();
}
}
Transformation
对于Transformation ,Flink提供了很多的算子,
map
DataStream → DataStream Takes one element and produces one element. A map function that doubles the values of the input stream:
DataStream<Integer> dataStream = //...
dataStream.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer value) throws Exception {
return 2 * value;
}
});
flatMap
DataStream → DataStream Takes one element and produces zero, one, or more elements. A flatmap function that splits sentences to words:
dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
for(String word: value.split(" ")){
out.collect(word);
}
}
});
filter
DataStream → DataStream Evaluates a boolean function for each element and retains those for which the function returns true. A filter that filters out zero values:
dataStream.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value != 0;
}
});
keyBy
DataStream → KeyedStream Logically partitions a stream into disjoint partitions. All records with the same key are assigned to the same partition. Internally, keyBy() is implemented with hash partitioning. There are different ways to specify keys.
This transformation returns a KeyedStream, which is, among other things, required to use keyed state.Attention A type cannot be a key if:
fold
aggregation
window/windowAll/window.apply/window.reduce/window.fold/window.aggregation
dataStream.keyBy(value -> value.getSomeKey()) // Key by field "someKey"
dataStream.keyBy(value -> value.f0) // Key by the first element of a Tuple
更多算子操作可以查看官网,官网写的很好:https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/dev/datastream/operators/overview/
Sink
Flink针对DataStream提供了大量的已经实现的数据目的地(Sink),具体如下所示
writeAsText():讲元素以字符串形式逐行写入,这些字符串通过调用每个元素的toString()方法来获取
print()/printToErr():打印每个元素的toString()方法的值到标准输出或者标准错误输出流中
自定义输出:addSink可以实现把数据输出到第三方存储介质中, Flink提供了一批内置的Connector,其中有的Connector会提供对应的Sink支持
这里举一个常见的例子,下层到Kafka
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
public class StreamToKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> data = env.socketTextStream("teacher2", 7777);
String brokerList = "teacher2:9092";
String topic = "mytopic2";
FlinkKafkaProducer producer = new FlinkKafkaProducer(brokerList, topic, new SimpleStringSchema());
data.addSink(producer);
env.execute();
}
}
DataSet的常用Api
DataSource
对DataSet批处理而言,较为频繁的操作是读取HDFS中的文件数据,因为这里主要介绍两个DataSource组件
基于集合 ,用来测试和DataStream类似
基于文件 readTextFile....
Transformation
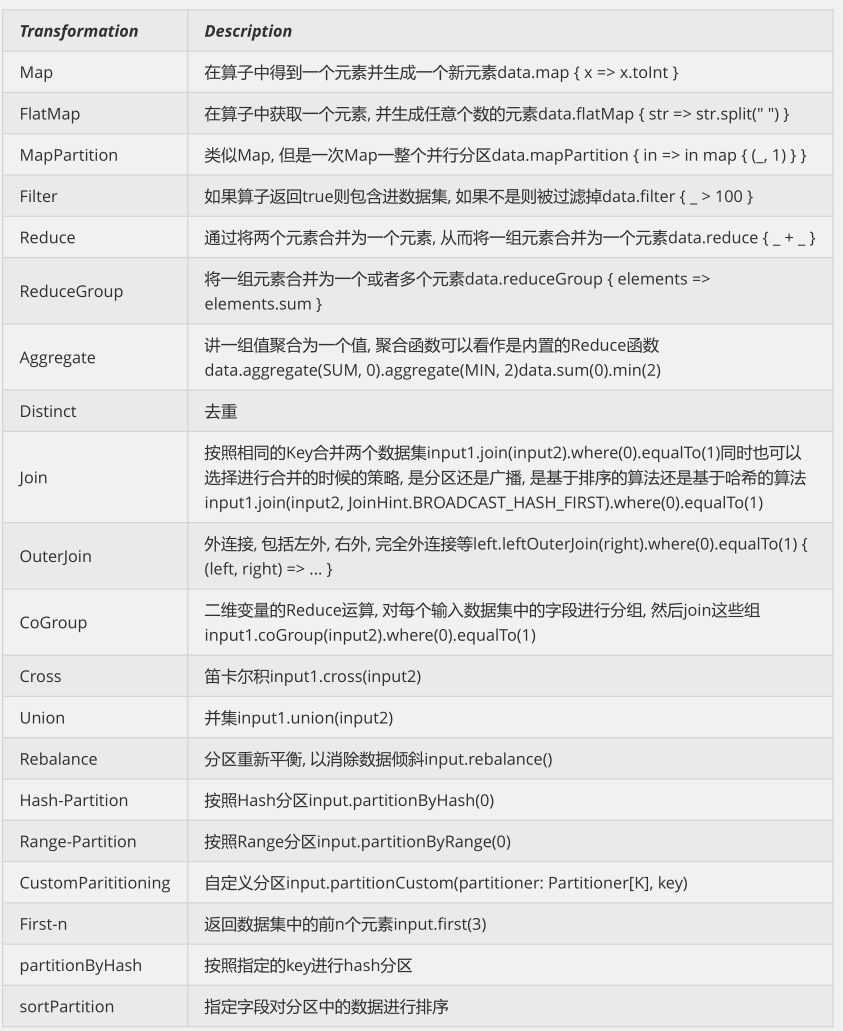
更多算子可以查看官网:https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/dev/dataset/overview/
Sink
Flink针对DataStream提供了大量的已经实现的数据目的地(Sink),具体如下所示
writeAsText():将元素以字符串形式逐行写入,这些字符串通过调用每个元素的toString()方法来获取
writeAsCsv():将元组以逗号分隔写入文件中,行及字段之间的分隔是可配置的,每个字段的值来自对象的
toString()方法
print()/pringToErr():打印每个元素的toString()方法的值到标准输出或者标准错误输出流中
Flink提供了一批内置的Connector,其中有的Connector会提供对应的Sink支持,如1.1节中表所示
吴邪,小三爷,混迹于后台,大数据,人工智能领域的小菜鸟。
更多请关注

大数据开发-Flink-数据流DataStream和DataSet的更多相关文章
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- 详解Kafka: 大数据开发最火的核心技术
详解Kafka: 大数据开发最火的核心技术 架构师技术联盟 2019-06-10 09:23:51 本文共3268个字,预计阅读需要9分钟. 广告 大数据时代来临,如果你还不知道Kafka那你就真 ...
- 大数据开发实战:HDFS和MapReduce优缺点分析
一. HDFS和MapReduce优缺点 1.HDFS的优势 HDFS的英文全称是 Hadoop Distributed File System,即Hadoop分布式文件系统,它是Hadoop的核心子 ...
- 大数据开发实战:Stream SQL实时开发三
4.聚合操作 4.1.group by 操作 group by操作是实际业务场景(如实时报表.实时大屏等)中使用最为频繁的操作.通常实时聚合的主要源头数据流不会包含丰富的上下文信息,而是经常需要实时关 ...
- 大数据开发实战:Stream SQL实时开发二
1.介绍 本节主要利用Stream SQL进行实时开发实战,回顾Beam的API和Hadoop MapReduce的API,会发现Google将实际业务对数据的各种操作进行了抽象,多变的数据需求抽象为 ...
- 大数据开发实战:Stream SQL实时开发一
1.流计算SQL原理和架构 流计算SQL通常是一个类SQL的声明式语言,主要用于对流式数据(Streams)的持续性查询,目的是在常见流计算平台和框架(如Storm.Spark Streaming.F ...
- 大数据开发实战:Storm流计算开发
Storm是一个分布式.高容错.高可靠性的实时计算系统,它对于实时计算的意义相当于Hadoop对于批处理的意义.Hadoop提供了Map和Reduce原语.同样,Storm也对数据的实时处理提供了简单 ...
- BAT推荐免费下载JAVA转型大数据开发全链路教程(视频+源码)价值19880元
如今随着环境的改变,物联网.AI.大数据.人工智能等,是未来的大趋势,而大数据是这些基石,万物互联,机器学习都是大数据应用场景! 为什么要学习大数据?我们JAVA到底要不要转型大数据? 好比问一个程序 ...
- Java转型大数据开发全套教程,都在这儿!
众所周知,很多语言技术已经在长久的历史发展中掩埋,这期间不同的程序员也走出的自己的发展道路. 有的去了解新的发展趋势的语言,了解新的技术,利用自己原先的思维顺利改变自己的title. 比如我自己,也都 ...
随机推荐
- Min25筛求1-n内的素数和
1 //#include <bits/stdc++.h> 2 #include<cstdio> 3 #include<cstring> 4 #include< ...
- P1579_哥德巴赫猜想(JAVA语言)
题目背景 1742年6月7日哥德巴赫写信给当时的大数学家欧拉,正式提出了以下的猜想:任何一个大于9的奇数都可以表示成3个质数之和.质数是指除了1和本身之外没有其他约数的数,如2和11都是质数,而6不是 ...
- Windows下解析命令行参数
linux通常使用GNU C提供的函数getopt.getopt_long.getopt_long_only函数来解析命令行参数. 移植到Windows下 getopt.h #ifndef _GETO ...
- 翻译:《实用的Python编程》08_01_Testing
目录 | 上一节 (7.5 装饰方法 | 下一节 (8.2 日志) 8.1 测试 多测试,少调试(Testing Rocks, Debugging Sucks) Python 的动态性质使得测试对大多 ...
- css详解position五种属性用法及其含义
position(定位) position - 作为css属性三巨头(position.display.float)之一,它的作用是用来决定元素在文档中的定位方式.其属性值有五种,分别是 - stat ...
- PBRT阅读笔记——COLOR AND RADIOMETRY
四个关键概念 Energy(Q) 每一个光子都有特定的波长并携带特定的能量: 其中c为光速,h为普朗克常量. Flux(Φ) 辐射通量,可以直观理解为功率.是能量对时间微分得到的 ...
- 02 . MongoDB复制集,分片集,备份与恢复
复制集 MongoDB复制集RS(ReplicationSet): 基本构成是1主2从的结构,自带互相监控投票机制(Raft(MongoDB)Paxos(mysql MGR 用的是变种)) 如果发生主 ...
- try - with - resource
本文详细介绍了自 JDK 7 引入的 try-with-resources 语句的原理和用法,以及介绍了 JDK 9 对 try-with-resources 的改进,使得用户可以更加方便.简洁的使用 ...
- Spring(11) - Introductions进行类扩展方法
Introductions(引用),在 Aspect 中称为类型间的声明,使切面能够声明被通知的对象(拦截的对象)实现给定的接口,并提供该接口的实现. 简单点说可以将一个类的实现方法复制到未实现的类中 ...
- matlab帮助文档
matlab的纯文本帮助命令有多种,help.lookfor.which.doc.get.type等 help命令 help命令用来查询一个函数的使用方式. help fun %fun是函数名称 ...