「Spark从精通到重新入门(一)」Spark 中不可不知的动态优化

前言
Apache Spark 自 2010 年面世,到现在已经发展为大数据批计算的首选引擎。而在 2020 年 6 月份发布的Spark 3.0 版本也是 Spark 有史以来最大的 Release,其中将近一半的 issue 都属于 SparkSQL。这也迎合我们现在的主要场景(90% 是 SQL),同时也是优化痛点和主要功能点。我们 Erda 的 FDP 平台(Fast Data Platform)也从 Spark 2.4 升级到 Spark 3.0 并做了一系列的相关优化,本文将主要结合 Spark 3.0 版本进行探讨研究。
为什么 Spark 3.0 能够“神功大成”,在速度和性能方面有质的突破?本文就为大家介绍 Spark 3.0 中 SQL Engine 的“天榜第一”——自适应查询框架 AQE(Adaptive Query Execution)。
AQE,你是谁?
简单来说,自适应查询就是在运行时不断优化执行逻辑。
Spark 3.0 版本之前,Spark 执行 SQL 是先确定 shuffle 分区数或者选择 Join 策略后,再按规划执行,过程中不够灵活;现在,在执行完部分的查询后,Spark 利用收集到结果的统计信息再对查询规划重新进行优化。这个优化的过程不是一次性的,而是随着查询会不断进行优化, 让整个查询优化变得更加灵活和自适应。这一改动让我们告别之前无休止的被动优化。

AQE,你会啥?
了解了 AQE 是什么之后,我们再看看自适应查询 AQE 的“三板斧”:
- 动态合并 Shuffle 分区
- 动态调整 Join 策略
- 动态优化数据倾斜
动态合并 shuffle 分区
如果你之前使用过 Spark,也许某些“调优宝典”会告诉你调整 shuffle 的 partitions 数量,默认是 200。但是在不同 shuffle 中,数据的大小和分布基本都是不同的,那么简单地用一个配置,让所有的 shuffle 来遵循,显然不是最优的。
分区过小会导致每个 partition 处理的数据较大,可能需要将数据溢写到磁盘,从而减慢查询速度;分区过大又会带来 GC 压力和低效 I/O 等问题。因此,动态合并 shuffle 分区是非常必要的。AQE 可以在运行期间动态调整分区数来达到性能最优。
如下图所示,如果没有 AQE,shuffle 分区数为 5,对应执行的 Task 数为 5,但是其中有三个的数据量很少,任务分配不平衡,浪费了资源,降低了处理效率。
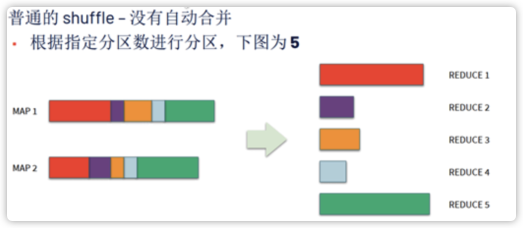
而 AQE 会合并三个小分区,最终只执行三个 Task,这样就不会出现之前 Task 空转的资源浪费情况。

动态调整 join 策略
SparkJoin 策略大致可以分三种,分别是 Broadcast Hash Join、Shuffle Hash Join 和 SortMerge Join。其中 Broadcast 通常是性能最好的,Spark 会在执行前选择合适的 Join 策略。
例如下面两个表的大小分别为 100 MB 和 30 MB,小表超过 10 MB (spark.sql.autoBroadcastJoinThreshold = 10 MB),所以在 Spark 2.4 中,执行前就选择了 SortMerge Join 的策略,但是这个方案并没有考虑 Table2 经过条件过滤之后的大小实际只有 8 MB。
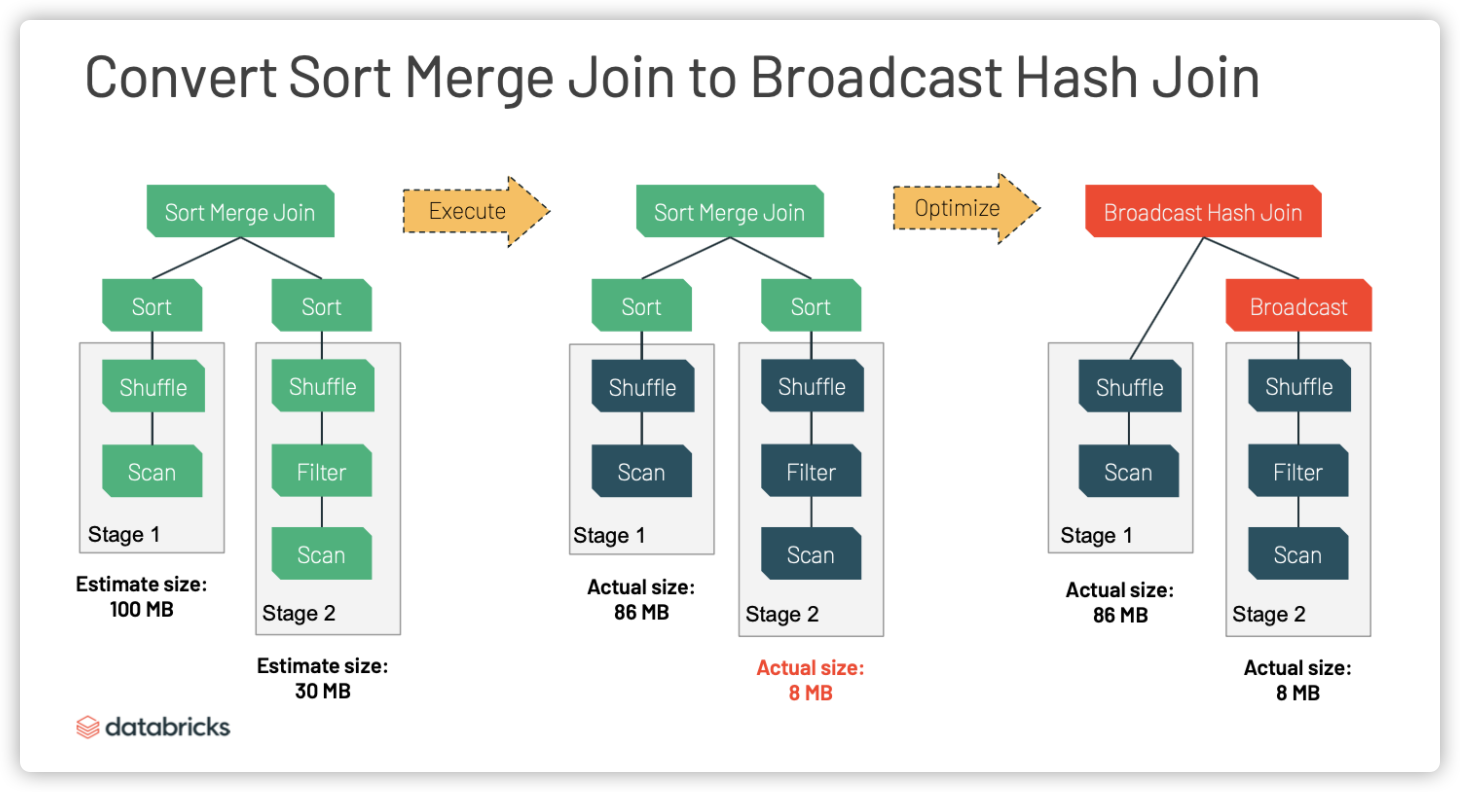
AQE 可以基于运行期间的统计信息,将 SortMerge Join 转换为 Broadcast Hash Join。
在上图中,Table2 经过条件过滤后真正参与 Join 的数据只有 8 MB,因此 Broadcast Hash Join 策略更优,Spark 3.0 会及时选择适合的 Join 策略来提高查询性能。
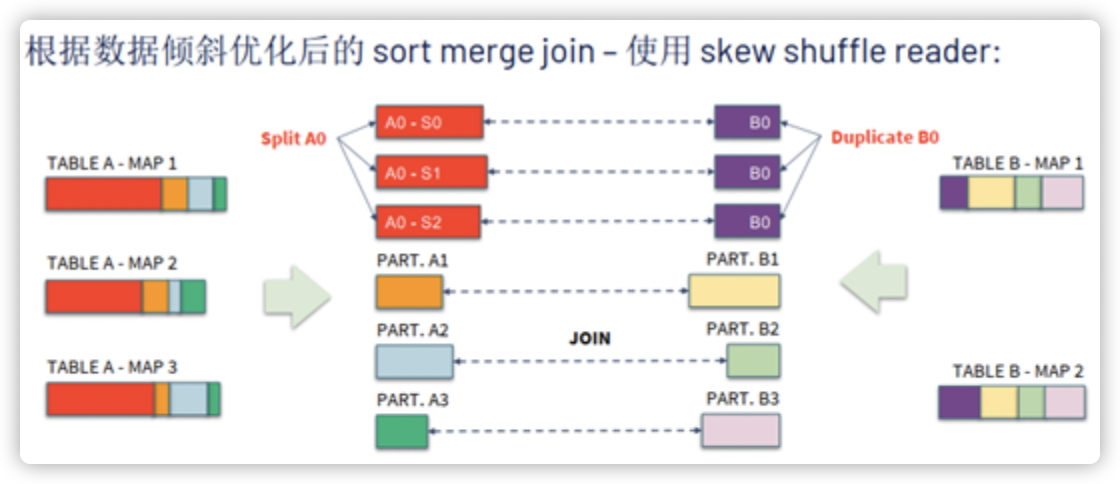
动态优化数据倾斜
数据倾斜一直是我们数据处理中的常见问题。当将相同 key 的数据拉取到一个 Task 中处理时,如果某个 key 对应的数据量特别大的话,就会发生数据倾斜,如下图一样产生长尾任务导致整个 Stage 耗时增加甚至 OOM。之前的解决方法比如重写 query 或者增加 key 消除数据分布不均,都非常浪费时间且后期难以维护。
AQE 可以检查分区数据是否倾斜,如果分区数据过大,就将其分隔成更小的分区,通过分而治之来提升总体性能。
没有 AQE 倾斜优化时,当某个 shuffle 分区的数据量明显高于其他分区,会产生长尾 Task,因为整个 Stage 的结束时间是按它的最后一个 Task 完成时间计算,下一个 Stage 只能等待,这会明显降低查询性能。

开启 AQE 后,会将 A0 分成三个子分区,并将对应的 B0 复制三份,优化后将有 6 个 Task 运行 Join,且每个 Task 耗时差不多,从而获得总体更好的性能。通过对倾斜数据的自适应重分区,解决了倾斜分区导致的整个任务的性能瓶颈,提高了查询处理效率。
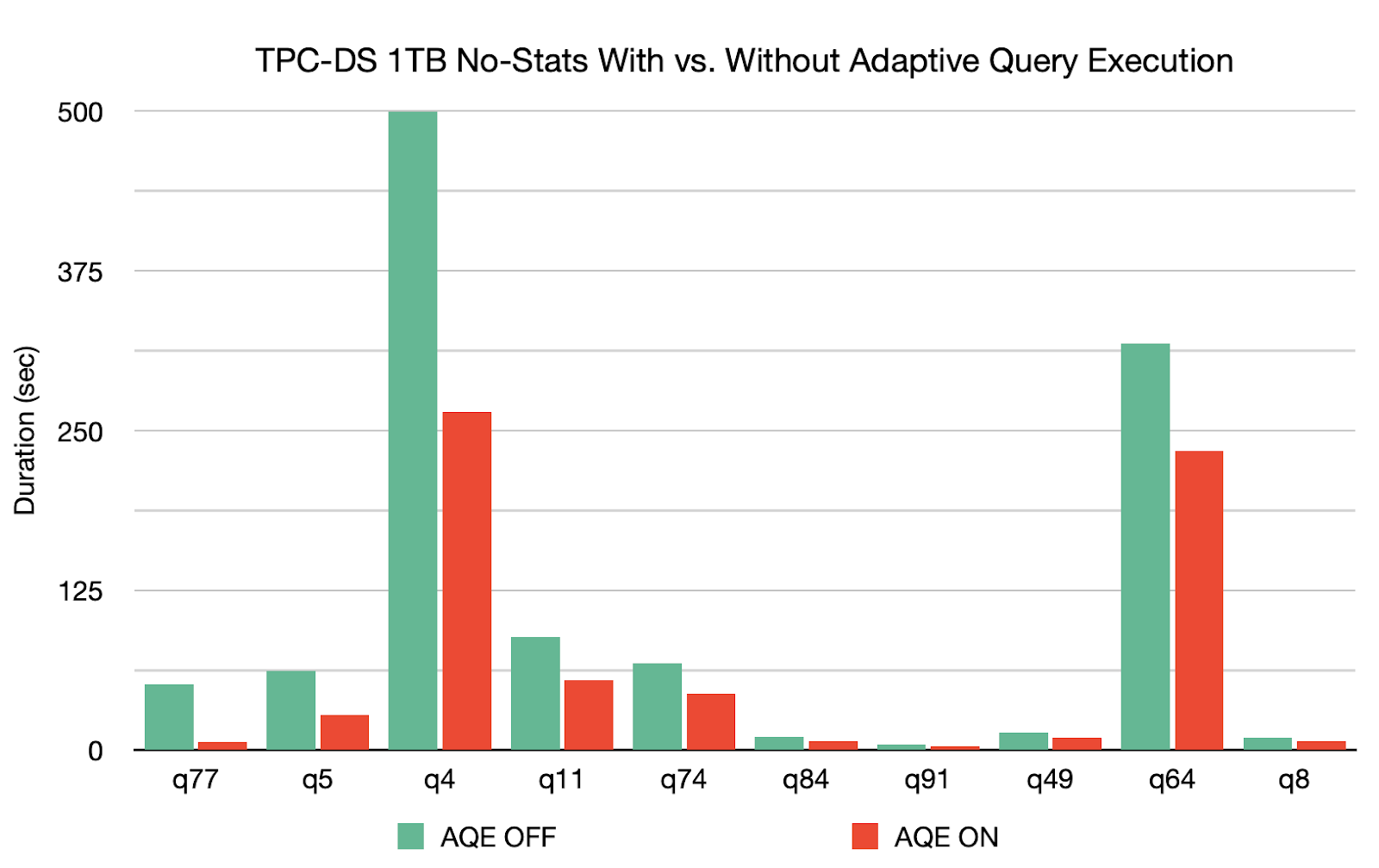
自适应查询 AQE 凭借着自己的“三板斧”,在 1TB TPC-DS 基准中,可以将 q77 的查询速度提高 8 倍,q5 的查询速度提高 2 倍,且对另外 26 个查询的速度提高 1.1 倍以上,这是普通优化无法想象的傲人战绩!
真的吗?我不信

口说无凭,自适应查询 AQE 的优越性到底是如何实现,我们“码”上看看。
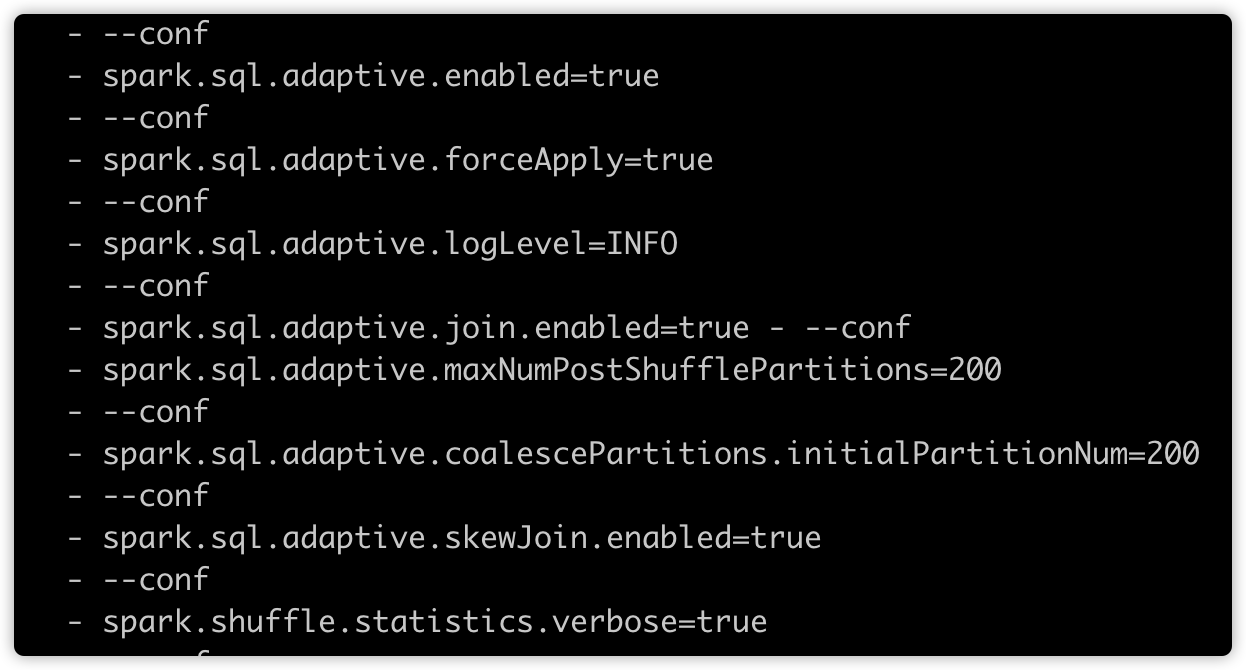
AQE 参数说明
#AQE开关
spark.sql.adaptive.enabled=true #默认false,为true时开启自适应查询,在运行过程中基于统计信息重新优化查询计划
spark.sql.adaptive.forceApply=true #默认false,自适应查询在没有shuffle或子查询时将不适用,设置为true将始终使用
spark.sql.adaptive.advisoryPartitionSizeInBytes=64M #默认64MB,开启自适应执行后每个分区的大小。合并小分区和分割倾斜分区都会用到这个参数
#开启合并shuffle分区
spark.sql.adaptive.coalescePartitions.enabled=true #当spark.sql.adaptive.enabled也开启时,合并相邻的shuffle分区,避免产生过多小task
spark.sql.adaptive.coalescePartitions.initialPartitionNum=200 #合并之前shuffle分区数的初始值,默认值是spark.sql.shuffle.partitions,可设置高一些
spark.sql.adaptive.coalescePartitions.minPartitionNum=20 #合并后的最小shuffle分区数。默认值是Spark集群的默认并行性
spark.sql.adaptive.maxNumPostShufflePartitions=500 #reduce分区最大值,默认500,可根据资源调整
#开启动态调整Join策略
spark.sql.adaptive.join.enabled=true #与spark.sql.adaptive.enabled都开启的话,开启AQE动态调整Join策略
#开启优化数据倾斜
spark.sql.adaptive.skewJoin.enabled=true #与spark.sql.adaptive.enabled都开启的话,开启AQE动态处理Join时数据倾斜
spark.sql.adaptive.skewedPartitionMaxSplits=5 #处理一个倾斜Partition的task个数上限,默认值为5;
spark.sql.adaptive.skewedPartitionRowCountThreshold=1000000 #倾斜Partition的行数下限,即行数低于该值的Partition不会被当作倾斜,默认值一千万
spark.sql.adaptive.skewedPartitionSizeThreshold=64M #倾斜Partition的大小下限,即大小小于该值的Partition不会被当做倾斜,默认值64M
spark.sql.adaptive.skewedPartitionFactor=5 #倾斜因子,默认为5。判断是否为倾斜的 Partition。如果一个分区(DataSize>64M*5) || (DataNum>(1000w*5)),则视为倾斜分区。
spark.shuffle.statistics.verbose=true #默认false,打开后MapStatus会采集每个partition条数信息,用于倾斜处理
AQE 功能演示
Spark 3.0 默认未开启 AQE 特性,样例 sql 执行耗时 41 s。
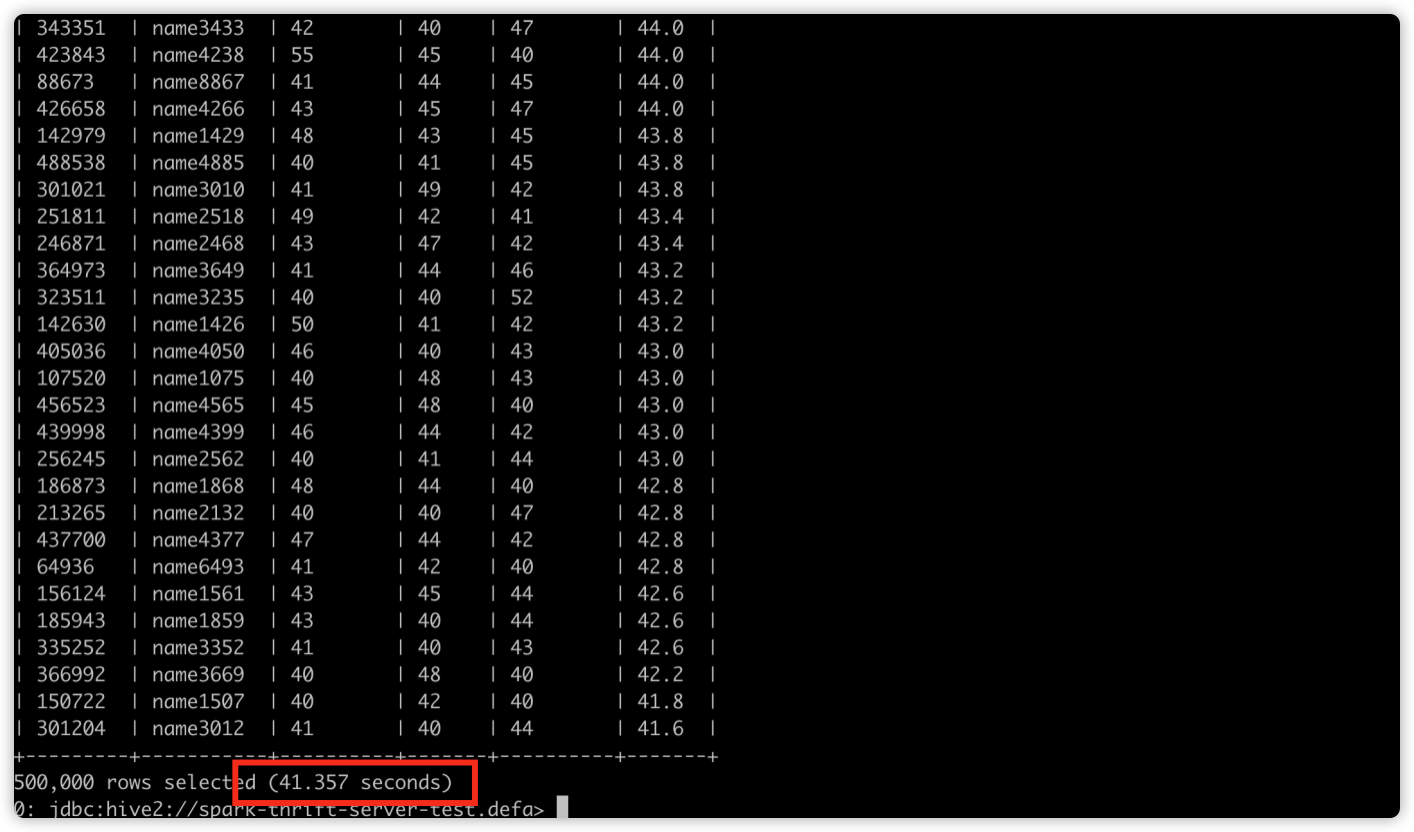
存在 Task 空转情况,shuffle 分区数始终为默认的 200。

开启 AQE 相关配置项,再次执行样例 sql。
样例 sql 执行耗时 18 s,快了一倍以上。
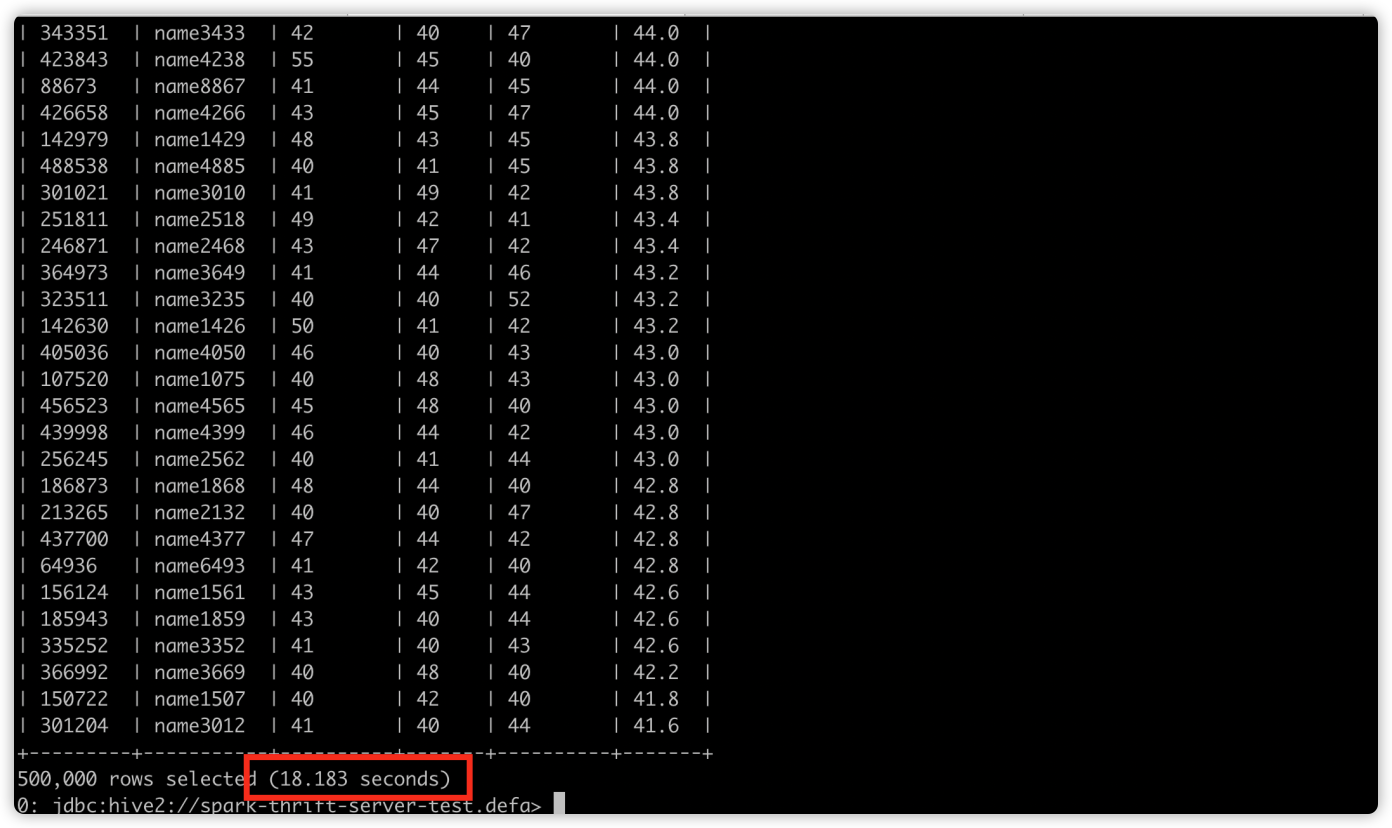
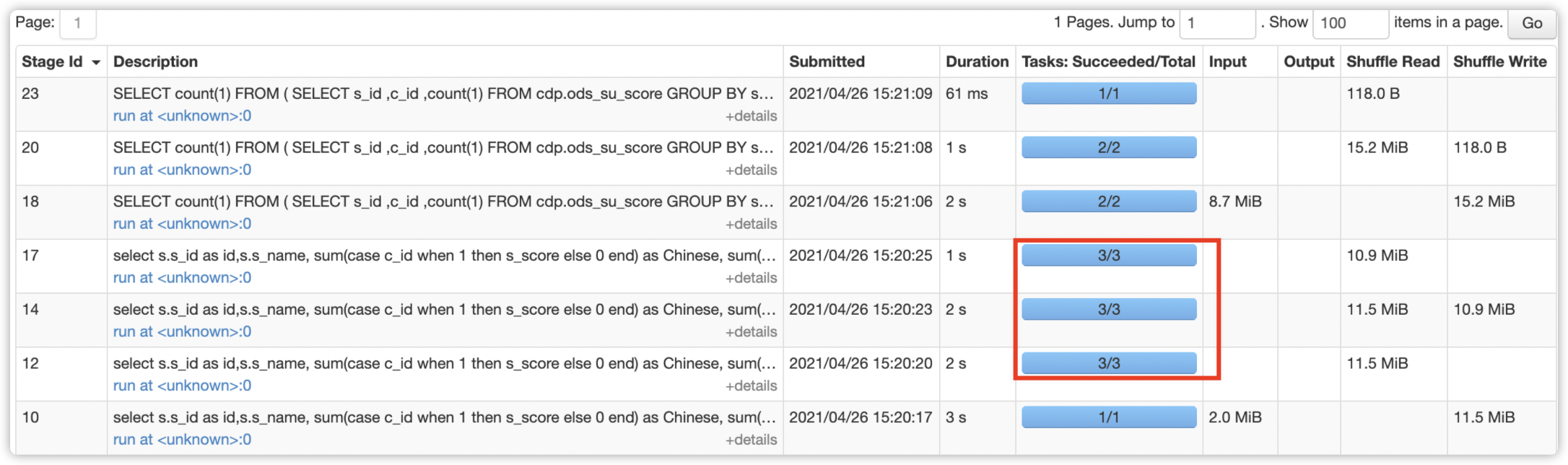
并且每个 Stage 的分区数动态调整,而不是固定的 200。无 task 空转情况,在 DAG 图中也能观察到特性开启。
总结
Spark 3.0 在速度和性能方面得提升有目共睹,它的新特性远不止自适应查询一个,当然也不意味着所有的场景都能有明显的性能提升,还需要我们结合业务和数据进行探索和使用。
注:文中部分图片源自于网络,侵删。
「Spark从精通到重新入门(一)」Spark 中不可不知的动态优化的更多相关文章
- 「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
前言 资源是影响 Spark 应用执行效率的一个重要因素.Spark 应用中真正执行 task 的组件是 Executor,可以通过spark.executor.instances 指定 Spark ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark入门实战系列--7.Spark Streaming(下)--实时流计算Spark Streaming实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .实例演示 1.1 流数据模拟器 1.1.1 流数据说明 在实例演示中模拟实际情况,需要源源 ...
- Spark:Spark 编程模型及快速入门
http://blog.csdn.net/pipisorry/article/details/52366356 Spark编程模型 SparkContext类和SparkConf类 代码中初始化 我们 ...
- Android Studio2.0 教程从入门到精通Windows版 - 入门篇
http://www.open-open.com/lib/view/open1468121363300.html 本文转自:深度开源(open-open.com)原文标题:Android Studio ...
- 大数据学习系列之Hadoop、Spark学习线路(想入门大数据的童鞋,强烈推荐!)
申明:本文出自:http://www.cnblogs.com/zlslch/p/5448857.html(该博客干货较多) 1 Java基础: 视频方面: 推荐<毕向东JAVA ...
- Spark RDD/Core 编程 API入门系列之简单移动互联网数据(五)
通过对移动互联网数据的分析,了解移动终端在互联网上的行为以及各个应用在互联网上的发展情况等信息. 具体包括对不同的应用使用情况的统计.移动互联网上的日常活跃用户(DAU)和月活跃用户(MAU)的统计, ...
- Android精通教程-Android入门简介
前言 大家好,我是 Vic,今天给大家带来Android精通教程-Android入门简介的概述,希望你们喜欢 每日一句 If life were predictable it would cease ...
- 入门大数据---Spark整体复习
一. Spark简介 1.1 前言 Apache Spark是一个基于内存的计算框架,它是Scala语言开发的,而且提供了一站式解决方案,提供了包括内存计算(Spark Core),流式计算(Spar ...
随机推荐
- 数据流中的中位数 牛客网 剑指Offer
数据流中的中位数 牛客网 剑指Offer 题目描述 如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值.如果从数据流中读出偶数个数值,那么中位数就 ...
- PHP笔记2__变量/字符串/类型转换/常量/,,
<?php //可变变量 $a = "ok"; $$a = "fine"; $$$a = "er"; echo $ok; echo & ...
- 恶意代码分析实战四:IDA Pro神器的使用
目录 恶意代码分析实战四:IDA Pro神器的使用 实验: 题目1:利用IDA Pro分析dll的入口点并显示地址 空格切换文本视图: 带地址显示图形界面 题目2:IDA Pro导入表窗口 题目3:交 ...
- 【AI测试】人工智能 (AI) 测试--第二篇
测试用例 人工智能 (AI) 测试 或者说是 算法测试,主要做的有三件事. 收集测试数据 思考需要什么样的测试数据,测试数据的标注 跑测试数据 编写测试脚本批量运行 查看数据结果 统计正确和错误的个数 ...
- 【机器学习基础】关于深度学习的Tips
继续回到神经网络章节,上次只对模型进行了简要的介绍,以及做了一个Hello World的练习,这节主要是对当我们结果不好时具体该去做些什么呢?本节就总结一些在深度学习中一些基本的解决问题的办法. 为什 ...
- tabulate
ValueError: headers for a list of dicts is not a dict or a keyword from: https://bitbucket.org/astan ...
- Integer.valueOf()和Integer.parseInt()区别
他们返回类型的不同是最大的原因. static int parseInt(String s) 将字符串参数作为有符号的十进制整数进行分析. static Integer valueOf(int i) ...
- [cf1392I]Kevin and Grid
令$v$为点数(有公共点的格子中存在红/蓝色).$e$为边数(有公共边的格子中存在红/蓝色).$f$为以此法(即仅考虑这些点和边)所分割出的区域数(包括外面).$s$为连通块个数,将欧拉定理简单扩展, ...
- ES6学习 第二章 变量的解构赋值
前言 该篇笔记是第二篇 变量的解构赋值. 这一章原文链接: 变量的解构赋值 解构赋值 ES6 允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构(Destructuring). 解构 ...
- Plugin [id: 'org.jetbrains.kotlin.jvm'] was not found in any of the following sources: gradle配置:kotlin("jvm")后报错
本来打算兼容java和kotlin,可配置后,项目报错.查看之前项目 再打开当前报错项目: 很明显,报错的原因是jvm的运行文件没有加载进来,多次尝试无果... 只能重新搭建初始化项目了.