二叉搜索树、平衡二叉树、红黑树、B树、B+树
完全二叉树:
空树不是完全二叉树,叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。如果遇到一个结点,左孩子不为空,右孩子为空;或者左右孩子都为空;则该节点之后的队列中的结点都为叶子节点;该树才是完全二叉树,否则就不是完全二叉树;
具有n个节点的完全二叉树深为log2x+1(其中x表示不大于n的最大整数)
满二叉树:
除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树。
二叉搜索树(二叉排序树、又称二叉查找树):
可以为空树,或者是具备如下性质:若它的左子树不空,则左子树上的所有结点的值均小于根节点的值;若它的右子树不空,则右子树上的所有结点的值均大于根节点的值,左右子树分别为二叉排序树。
理论上说,二叉搜索树的查询、插入、和删除一个节点的时间复杂度均为O(log(n))
但是还有一种特殊情况:

这种情况下,二叉搜索树已经变更为链表,搜索一个元素的时间复杂度也变成了O(n)
出现这种情况的原因是二叉搜索树没有自平衡的机制,所以就有了平衡二叉树。
平衡二叉树(是一种概念,它有几种实现方式:红黑树、AVL树)
它是一个空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是平衡二叉树

当AVL树插入一个节点时,如果平衡因子已经大于1了,这个时候就要进行左旋、右旋使之平衡因子恢复为1
红黑树
红黑树是一种平衡二叉查找树的变体,它的左右子树高差有可能大于 1,所以红黑树不是严格意义上的平衡二叉树(AVL),但 对之进行平衡的代价较低, 其平均统计性能要强于 AVL 。
红黑树和AVL树的区别:
RB-Tree和AVL树作为BBST,其实现的算法时间复杂度相同,AVL作为最先提出的BBST,貌似RB-tree实现的功能都可以用AVL树是代替,那么为什么还需要引入RB-Tree呢?
- 红黑树不追求"完全平衡",即不像AVL那样要求节点的
|balFact| <= 1,它只要求部分达到平衡,但是提出了为节点增加颜色,红黑是用非严格的平衡来换取增删节点时候旋转次数的降低,任何不平衡都会在三次旋转之内解决,而AVL是严格平衡树,因此在增加或者删除节点的时候,根据不同情况,旋转的次数比红黑树要多。 - 就插入节点导致树失衡的情况,AVL和RB-Tree都是最多两次树旋转来实现复衡rebalance,旋转的量级是O(1)
删除节点导致失衡,AVL需要维护从被删除节点到根节点root这条路径上所有节点的平衡,旋转的量级为O(logN),而RB-Tree最多只需要旋转3次实现复衡,只需O(1),所以说RB-Tree删除节点的rebalance的效率更高,开销更小! - AVL的结构相较于RB-Tree更为平衡,插入和删除引起失衡,如2所述,RB-Tree复衡效率更高;当然,由于AVL高度平衡,因此AVL的Search效率更高啦。
- 针对插入和删除节点导致失衡后的rebalance操作,红黑树能够提供一个比较"便宜"的解决方案,降低开销,是对search,insert ,以及delete效率的折衷,总体来说,RB-Tree的统计性能高于AVL.
- 故引入RB-Tree是功能、性能、空间开销的折中结果。
5.1 AVL更平衡,结构上更加直观,时间效能针对读取而言更高;维护稍慢,空间开销较大。
5.2 红黑树,读取略逊于AVL,维护强于AVL,空间开销与AVL类似,内容极多时略优于AVL,维护优于AVL。
总结:实际应用中,若搜索的次数远远大于插入和删除,那么选择AVL,如果搜索,插入删除次数几乎差不多,应该选择RB-Tree。
红黑树是一种含有红黑结点并能自平衡的二叉查找树。它必须除了满足二叉搜索树的性质外,还要满足下面的性质:
性质1:每个节点要么是黑色,要么是红色。
性质2:根节点是黑色。
性质3:每个叶子节点(NIL)是黑色。
性质4:每个红色结点的两个子结点一定都是黑色。
性质5:任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
我们知道Mysql Innodb存储引擎的索引的数据结构为B+树,那么什么是B+树呢?
先来了解下B树:
一种平衡的多叉树,称为B树(或B-树、B_树)

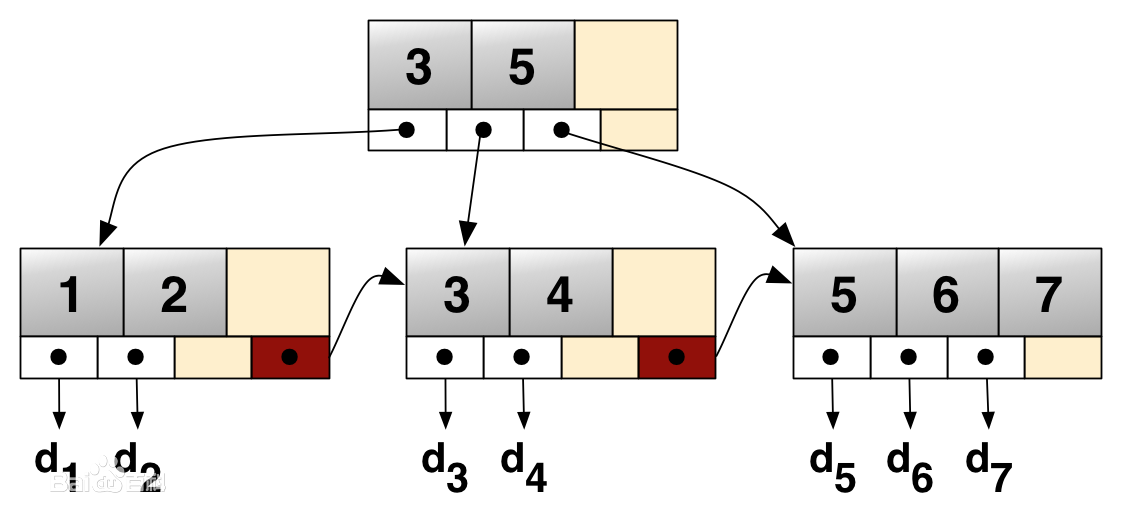
特点:
数据只出现在叶子节点
所有叶子节点增加了一个链指针
简单总结:mysql中的innodb为什么用B+树不使用B树
1.B树把数据放在了每个节点上,而B+树把数据放在了叶子节点上,所以单个查询速度B+平均要快于B树,但是B-树的每个节点都有data域(指针),这无疑增大了节点大小,说白了增加了磁盘IO次数(磁盘IO一次读出的数据量大小是固定的,单个数据变大,每次读出的就少,IO次数增多),而B+树除了叶子节点其它节点并不存储数据,节点小,磁盘IO次数就少。
2.另一方面,由于B+树有链指针,所以更方便区间查询。
https://www.jianshu.com/p/37436ed14cc6
https://mp.weixin.qq.com/s/9s6c1sPN7avqwxZC7BsVUQ
二叉搜索树、平衡二叉树、红黑树、B树、B+树的更多相关文章
- 二叉搜索树、AVL平衡二叉搜索树、红黑树、多路查找树
1.二叉搜索树 1.1定义 是一棵二叉树,每个节点一定大于等于其左子树中每一个节点,小于等于其右子树每一个节点 1.2插入节点 从根节点开始向下找到合适的位置插入成为叶子结点即可:在向下遍历时,如果要 ...
- L2-004 这是二叉搜索树吗? (25 分) (树)
链接:https://pintia.cn/problem-sets/994805046380707840/problems/994805070971912192 题目: 一棵二叉搜索树可被递归地定义为 ...
- Leetcode 538. 把二叉搜索树转换为累加树
题目链接 https://leetcode.com/problems/convert-bst-to-greater-tree/description/ 题目描述 大于它的节点值之和. 例如: 输入: ...
- Java实现二叉搜索树的添加,前序、后序、中序及层序遍历,求树的节点数,求树的最大值、最小值,查找等操作
什么也不说了,直接上代码. 首先是节点类,大家都懂得 /** * 二叉树的节点类 * * @author HeYufan * * @param <T> */ class Node<T ...
- 算法二叉搜索树之AVL树
最近学习了二叉搜索树中的AVL树,特在此写一篇博客小结. 1.引言 对于二叉搜索树而言,其插入查找删除等性能直接和树的高度有关,因此我们发明了平衡二叉搜索树.在计算机科学中,AVL树是最先发明的自平衡 ...
- [Swift]LeetCode538. 把二叉搜索树转换为累加树 | Convert BST to Greater Tree
Given a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original B ...
- 538 Convert BST to Greater Tree 把二叉搜索树转换为累加树
给定一个二叉搜索树(Binary Search Tree),把它转换成为累加树(Greater Tree),使得每个节点的值是原来的节点值加上所有大于它的节点值之和.例如:输入: 二叉搜索树: ...
- LeetCode 把二叉搜索树转换为累加树
第538题 给定一个二叉搜索树(Binary Search Tree),把它转换成为累加树(Greater Tree),使得每个节点的值是原来的节点值加上所有大于它的节点值之和. 例如: 输入: 二叉 ...
- [LeetCode] 538. 把二叉搜索树转换为累加树 ☆(中序遍历变形)
把二叉搜索树转换为累加树 描述 给定一个二叉搜索树(Binary Search Tree),把它转换成为累加树(Greater Tree),使得每个节点的值是原来的节点值加上所有大于它的节点值之和. ...
- Java实现 LeetCode 538 把二叉搜索树转换为累加树(遍历树)
538. 把二叉搜索树转换为累加树 给定一个二叉搜索树(Binary Search Tree),把它转换成为累加树(Greater Tree),使得每个节点的值是原来的节点值加上所有大于它的节点值之和 ...
随机推荐
- Celery Received unregistered task of type
celery -A proj worker --loglevel=info 这个错误原因在于proj这里没有包含对应的task, 可以在这里导入需要的task即可
- java 模版式的 word
... package com.kingzheng.projects.word; import java.io.BufferedWriter; import java.io.File; import ...
- 字符编码和python文件操作
字符编码和文件操作 目录 字符编码和文件操作 1. 字符编码 1.1 什么是字符编码 1.2 字符编码的发展史 1.2.1 ASCII码 1.2.2 各国编码 1.2.3 Unicode 1.3 字符 ...
- Asp.net core自定义依赖注入容器,替换自带容器
依赖注入 在asp.net core程序中,众所周知,依赖注入基本上贯穿了整个项目,以通用的结构来讲解,控制器层(Controller层)依赖业务层(Service层),业务层依赖于仓储层(Repos ...
- NodeJS连接MongoDB和mongoose
1.MongoDB是一个基于分布式文件存储的数据库.由C++语言编写.旨在为WEB应用提供可扩展的高性能数据存储解决方案.是世界上目前用的最广泛的nosql数据库 2.noSql 翻译过来 not o ...
- [loj4]Quine
很有趣的一道题目,如何让一个程序输出自身如果用字符串s表示程序,那么意味着可以通过s来输出sprintf是一个可以利用的函数,相当于要求printf(s,s)输出的就是s那么只需要在s中加入%c和%d ...
- Jetpack架构组件学习(2)——ViewModel和Livedata使用
要看本系列其他文章,可访问此链接Jetpack架构学习 | Stars-One的杂货小窝 原文地址:Jetpack架构组件学习(2)--ViewModel和Livedata使用 | Stars-One ...
- 未能加载文件或程序集“Microsoft.CodeDom.Providers.DotNetCompilerPlatform
"/"应用程序中的服务器错误. 未能加载文件或程序集"Microsoft.CodeDom.Providers.DotNetCompilerPlatform, Versio ...
- Codeforces 590E - Birthday(AC 自动机+Dilworth 定理+二分图匹配)
题面传送门 AC 自动机有时只是辅助建图的工具,真的 首先看到多串问题,果断建出 AC 自动机.设 \(m=\sum|s_i|\). 不难发现子串的包含关系构成了一个偏序集,于是我们考虑转化为图论,若 ...
- 在R语言中使用Stringr进行字符串操作
今天来学习下R中字符串处理操作,主要是stringr包中的字符串处理函数的用法. 先导入stringr包,library(stringr),require(stringr),或者stringr::函数 ...