A100计算能力
A100计算能力
A100 GPU支持新的计算功能8.0。表1比较了NVIDIA GPU架构的不同计算功能的参数。

表1.计算能力:GP100 vs. GV100 vs. GA100。
MIG架构
尽管许多数据中心的工作量在规模和复杂性上都在继续扩展,但某些加速任务的要求却不高,例如早期开发或推断小批量的简单模型。数据中心经理的目标是保持较高的资源利用率,因此理想的数据中心加速器不仅会变大,还会有效地加速许多较小的工作负载。
新的MIG功能可以将每个A100划分为多达七个GPU实例,以实现最佳利用率,从而有效地扩展对每个用户和应用程序的访问权限。
图10显示了Volta MPS如何允许多个应用程序在单独的GPU执行资源(SM)上同时执行。但是,由于内存系统资源是在所有应用程序之间共享的,因此,如果一个应用程序对DRAM带宽有很高的要求或者其请求超额预订了L2高速缓存,则该应用程序可能会干扰其它应用程序。
图1中所示的A100 GPU新的MIG功能可以将单个GPU划分为多个GPU分区,称为GPU实例。 每个实例的SM都具有贯穿整个内存系统的单独且隔离的路径-片上交叉开关端口,L2缓存库,内存控制器和DRAM地址总线都被唯一地分配给单个实例。这样可以确保单个用户的工作负载可以以可预测的吞吐量和延迟运行,并且具有相同的二级缓存分配和DRAM带宽,即使其它任务正在颠覆自己的缓存或使DRAM接口饱和也是如此。
使用此功能, MIG可以对可用的GPU计算资源进行分区,以为不同客户端(例如VM,容器,进程等)提供故障隔离,从而提供定义的服务质量( QoS)。它使多个GPU实例可以在单个物理A100 GPU上并行运行。MIG还保持CUDA编程模型不变,以最大程度地减少编程工作量。
CSP可以使用MIG提高其GPU服务器的利用率,无需额外成本即可提供多达7倍的GPU实例。MIG支持CSP所需的必要QoS和隔离保证,以确保一个客户端(VM,容器,进程)不会影响另一客户端的工作或调度。
CSP通常根据客户使用模式对硬件进行分区。仅当硬件资源在运行时提供一致的带宽,适当的隔离和良好的性能时,有效分区才有效。
借助基于NVIDIA Ampere架构的GPU,可以在其新的虚拟GPU实例上查看和调度作业,就好像它们是物理GPU一样。MIG可与Linux操作系统及其管理程序一起使用。用户可以使用诸如Docker Engine之类的运行时运行带有MIG的容器,并很快将支持使用Kubernetes进行容器编排。

图1.今天的CSP多用户节点(A100之前的版本)。加速的GPU实例仅在完全物理GPU粒度下可供不同组织中的用户使用,即使用户应用程序不需要完整的GPU。
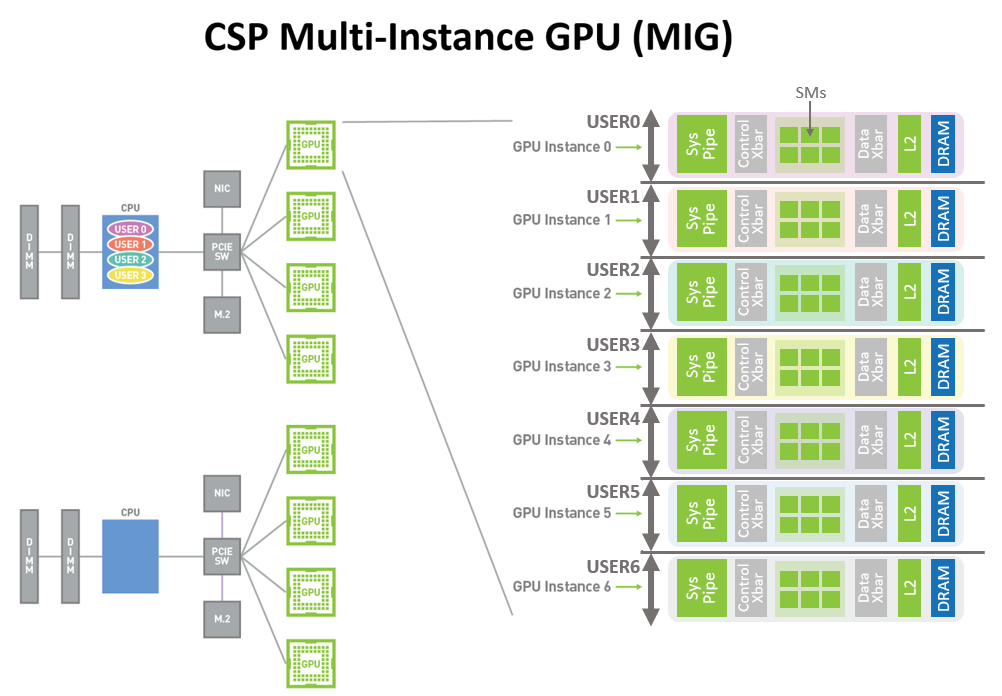
图2. CSP多用户和MIG图。来自同一组织或不同组织的多个独立用户可以在单个物理GPU中分配其自己的专用,受保护和隔离的GPU实例。
错误和故障检测,隔离和控制
通过检测,包含并经常纠正错误和故障来提高GPU的正常运行时间和可用性至关重要,而不是强制GPU重置。这对于大型的多GPU群集和单GPU多租户环境(例如MIG配置)尤其重要。
NVIDIA Ampere架构A100 GPU包括新技术,可改善错误/故障归因(归因于导致错误的应用程序),隔离(隔离有故障的应用程序,以使它们不会影响在同一GPU或GPU集群中运行的其它应用程序),和限制(确保一个应用程序中的错误不会泄漏并影响其它应用程序)。这些故障处理技术对于MIG环境尤其重要,以确保共享单个GPU的客户端之间的适当隔离和安全性。
连接NVLink的GPU现在具有更强大的错误检测和恢复功能。远程GPU的页面错误会通过NVLink发送回源GPU。远程访问故障通信是大型GPU计算群集的一项关键弹性功能,有助于确保一个进程或VM中的故障不会导致其它进程或VM停机。
A100 GPU包括其它几个新的和改进的硬件功能,可以增强应用程序性能。有关更多信息,请参阅即将发布的NVIDIA A100 Tensor Core GPU架构白皮书。
CUDA 11在NVIDIA Ampere架构GPU方面的进步
在NVIDIA CUDA并行计算平台上构建了成千上万个GPU加速的应用程序。CUDA的灵活性和可编程性使其成为研究和部署新的DL和并行计算算法的首选平台。
NVIDIA Ampere架构GPU旨在提高GPU的可编程性和性能,同时还降低软件复杂性。NVIDIA Ampere架构的GPU和CUDA编程模型的改进可加速程序执行,并降低许多操作的延迟和开销。
CUDA 11的新功能为第三代Tensor核心,稀疏性,CUDA图形,多实例GPU,L2缓存驻留控件以及NVIDIA Ampere架构的其它一些新功能提供了编程和API支持。
有关新CUDA功能的更多信息,请参阅即将发布的NVIDIA A100 Tensor Core GPU体系结构白皮书。有关新DGX A100系统的更多信息,请参阅使用NVIDIA DGX A100定义AI创新。有关开发人员专区的更多信息,请参阅NVIDIA Developer,有关CUDA的更多信息,请参见新的CUDA编程指南。
结论
NVIDIA的使命是加速时代的达芬奇和爱因斯坦的工作。科学家,研究人员和工程师致力于使用高性能计算(HPC)和AI解决世界上最重要的科学,工业和大数据挑战。
NVIDIA A100 Tensor Core GPU在的加速数据中心平台中实现了下一个巨大飞跃,可在任何规模上提供无与伦比的加速性能,并使这些创新者能够终其一生。A100支持众多应用领域,包括HPC,基因组学,5G,渲染,深度学习,数据分析,数据科学和机器人技术。
推进当今最重要的HPC和AI应用程序(个性化医学,会话式AI和深度推荐系统),需要研究人员不断发展。A100为NVIDIA数据中心平台提供支持,该平台包括Mellanox HDR InfiniBand,NVSwitch,NVIDIA HGX A100和Magnum IO SDK,以进行扩展。这个集成的技术团队可以有效地扩展到成千上万个GPU,以前所未有的速度训练最复杂的AI网络。
A100 GPU的新MIG功能可将每个A100划分为多达七个GPU加速器,以实现最佳利用率,从而有效地提高GPU资源利用率以及GPU对更多用户和GPU加速应用程序的访问。借助A100的多功能性,基础架构管理人员可以最大化其数据中心中每个GPU的利用率,以满足从最小的工作到最大的多节点工作负载的不同规模的性能需求。
A100计算能力的更多相关文章
- A100 GPU硬件架构
A100 GPU硬件架构 NVIDIA GA100 GPU由多个GPU处理群集(GPC),纹理处理群集(TPC),流式多处理器(SM)和HBM2内存控制器组成. GA100 GPU的完整实现包括以下单 ...
- 查找 GPU 计算能力
你能在这里找到你的 GPU 的计算能力: https://en.wikipedia.org/wiki/CUDA#Supported_GPUs
- 理解 Azure 平台中虚拟机的计算能力
虚拟化平台至今已经发展了十多年的时间.其中 Hyper-V 技术现在也已经是第三代版本.用户对于虚拟化计算也越来越接受,这也有了公有云发展的基础.然而在很多时候,用户在使用基于 Hyper-V 的 A ...
- ZZULIoj 1913: 小火山的计算能力
Description 别人说小火山的计算能力不行,小火山很生气,于是他想证明自己,现在有一个表达式,他想计算出来. Input 首先是一个t(1<=20)表示测试组数.然后一个表达式,表达式长 ...
- 深度 | AI芯片之智能边缘计算的崛起——实时语言翻译、图像识别、AI视频监控、无人车这些都需要终端具有较强的计算能力,从而AI芯片发展起来是必然,同时5G网络也是必然
from:https://36kr.com/p/5103044.html 到2020年,大多数先进的ML袖珍电脑(你仍称之为手机)将有能力执行一整套任务.个人助理将变的更加智能,它是打造这种功能的切入 ...
- 33、给华美A100刷固件
给HAME A100刷固件 目的: 1. 给HAME A100刷固件 2. 配置上UVC驱动 3. 修改内核自带的UVC驱动,使其支持我们自制的二合一摄像头 4. 移植mjpg-streamer 5. ...
- 【matlab】GPU 显卡版本与计算能力(compute capability)兼容性问题
MathWorks - Bug Reports 1. 问题说明 当运行 alexnet 等卷积神经网络需要使用 GPU 加速时,matlab 如果提示如下的警告信息: GPUs of compute ...
- Maple拥有优秀的符号计算和数值计算能力
https://www.maplesoft.com/products/maple/ Maple高级应用和经典实例: https://wenku.baidu.com/view/f246962107221 ...
- 单颗GPU计算能力太多、太贵?阿里云发布云上首个轻量级GPU实例
摘要: 阿里云发布了国内首个公共云上的轻量级GPU异构计算产品——VGN5i实例,该实例打破了传统直通模式的局限,可以提供比单颗物理GPU更细粒度的服务,从而让客户以更低成本.更高弹性开展业务. 在硅 ...
随机推荐
- hdu4848 DFS 暴搜+ 强剪枝
题意: 给你一个图,然后问你从1出发遍历所有的点的距离和是多少,这里的距离和是每一个点到1的距离的总和,不是选择一条遍历所有点的路径的总长度,时间限制是 8000ms. 思路: ...
- 2.逆向分析Hello World!程序-上
先写一个HelloWorld程序(vs2015 / C++) 编译链接生成可执行文件XX.exe,然后用OD[OllyDbg]打开调试: 代码窗口:默认用于显示反汇编代码,还用于各种注释.标签,分析代 ...
- Hack The Box - Archetype
攻略的话在靶场内都有,也有官方的攻略,我作为一个技术小白,只是想把自己的通关过程记录下来,没有网站内大佬们写得好 我们获得了一个IP: 尝试访问了一下,应该不存在web页面: 对常规端口进行一个扫描: ...
- 密码学系列之:NIST和SHA算法
目录 简介 SHA1 SHA2 SHA3 简介 SHA算法大家应该都很熟悉了,它是一个用来计算hash的算法,目前的SHA算法有SHA1,SHA2和SHA3种.这三种算法都是由美国NIST制定的. N ...
- MindSpore保存与加载模型
技术背景 近几年在机器学习和传统搜索算法的结合中,逐渐发展出了一种Search To Optimization的思维,旨在通过构造一个特定的机器学习模型,来替代传统算法中的搜索过程,进而加速经典图论等 ...
- MySQL redo与undo日志解析
前言: 前面文章讲述了 MySQL 系统中常见的几种日志,其实还有事务相关日志 redo log 和 undo log 没有介绍.相对于其他几种日志而言, redo log 和 undo log 是更 ...
- Blazor实现未登录重定向到登录页的方法
今天研究了一下blazor,发现他默认启动就是类似于后台管理系统的界面,看到这个页面我就想给他写个登录,有登录就涉及到未登录重定向的问题,但是我没有找到blazor全局路由的设置,知道的老哥可以告诉我 ...
- BUA软件工程个人博客作业
写在前面 项目 内容 所属课程 2020春季计算机学院软件工程(罗杰 任健) (北航) 作业要求 个人博客作业 课程目标 培养软件开发能力 本作业对实现目标的具体作用 阅读教材,了解软件工程,并比较各 ...
- font
font属性简写 front: font-style font-variant font-weight font-size/line-height font-family 说明: 值之间空格隔开 注意 ...
- [刷题] PTA 7-62 切分表达式 写个tokenizer吧
我的程序: 1 #include<stdio.h> 2 #include<string.h> 3 #define N 50 4 char token[]= {'+','-',' ...