List.Sum…统计信息(Power Query 之 M 语言)
数据源:
任意数据源,一列数值,一列非数值(文本)
目标:
对数值列进行求和等计算,对非数值列进行计数等计算
操作过程:
选取待计算的列》【转换】》【统计信息】》选取
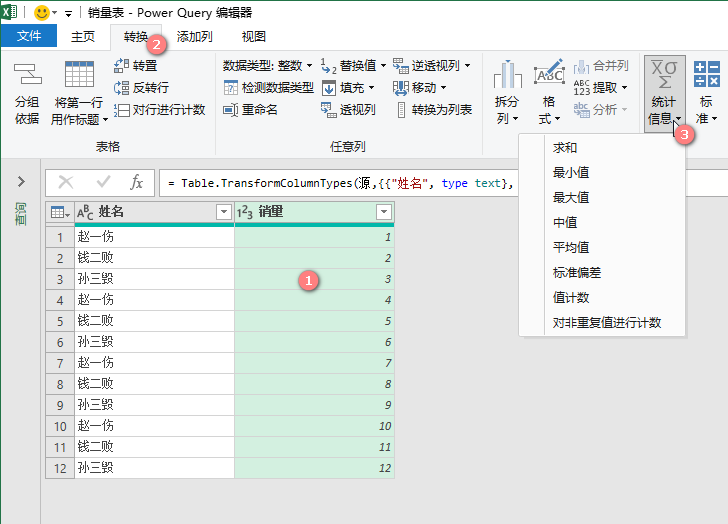
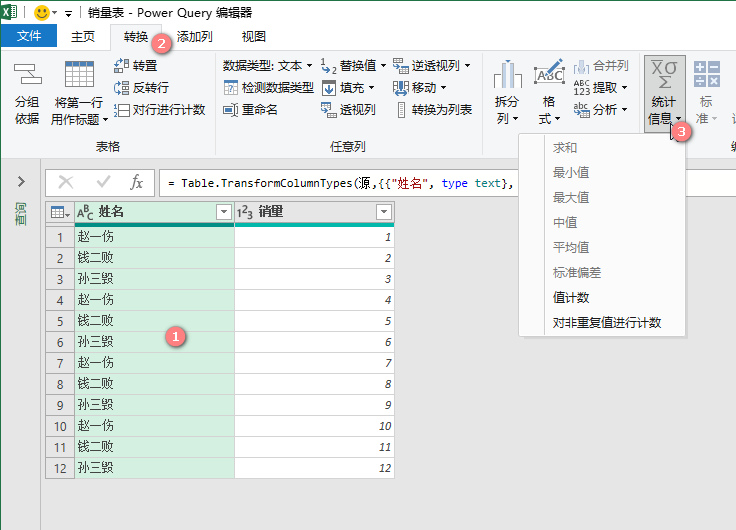
M公式:
求和:= List.Sum( 数值列表, 精度)
精度:
Precision.Double / 0 / 缺省:双精度
Precision.Decimal / 1:小数精度(可用于修正浮点误差)
计算忽略null值,除非整个列表为空
最小值:= List.Min( 列表, 空列时返回值, 条件, 逻辑值)
示例:
= List.Min({1..9}) 返回1
= List.Min({}) 返回 null
= List.Min({}, 3) 返回3
= List.Min({3,9,1,8}, null, each _ >5) 返回3
= List.Min({3,9,1,8}, null, each _ <5) 返回9
= List.Min({3,null}, null, null, true/缺省) 返回null
= List.Min({3,null}, null, null, false) 返回3
最大值:= List.Max( 列表, 空列时返回值, 条件, 逻辑值)
示例:
= List.Max({3,9,1,8}, null, each _ >5) 返回9
= List.Max({3,9,1,8}, null, each _ <5) 返回3
中值:= List.Median( 列表, 条件)
平均值:= List.Average( 数值列表, 精度)
标准偏差:= List.StandardDeviation(列表)
值计数:= List.NonNullCount(列表)
对非重复值进行计数:=List.NonNullCount(List.Distinct(列表))
扩展:
对行/列等进行计数:行列计数…Count
最小N个:= List.MinN( 列表, 列出的项数或条件, 排序方式, 逻辑值)
排序方式:
false / 0 / 缺省:升序
true / 1:升序:降序
逻辑值:
false / 缺省:null不参与其中
true:null参与其中
示例:
= List.MinN({7,8,9,3,2,1},3) 返回{1,2,3}
= List.MinN({7,8,9,3,2,1},each _ <3) 返回{1,2}
= List.MinN({7,8,9,3,2,1},3,1) 返回{9,8,7}
= List.MinN({7,null,9,3,2,1},3,0,true) 返回{null,1,2}
最大N个:= List.MaxN( 列表, 列出的项数或条件, 排序方式, 逻辑值)
排序方式:
false / 0 / 缺省:降序
true / 1:升序:升序
表中指定列的最小记录:= Table.Min( 表, {"列名1",...,"列名n"}或条件, 空表时返回值)
表中指定列的最大记录:= Table.Max( 表, {"列名1",...,"列名n"}或条件, 空表时返回值)
表中指定列的最小N行:= Table.MinN( 表, {{"列名1",排序方式1},...,{"列名n",排序方式n}}, 行数, 条件)
表中指定列的最大N行:= Table.MaxN( 表, {{"列名1",排序方式1},...,{"列名n",排序方式n}}, 行数, 条件)
List.Sum…统计信息(Power Query 之 M 语言)的更多相关文章
- M函数目录(Power Query 之 M 语言)
2021-12-11更新 主页(选项卡) 管理列(组) 选择列 选择列Table.SelectColumns 删除列 删除列Table.RemoveColumns 删除其他列Table.SelectC ...
- Table.RowCount行列计数…Count(Power Query 之 M 语言)
数据源: 任意五行两列 目标: 计算行数(包括空行) 操作过程: [转换]>[对行进行计数] M公式: = Table.RowCount( 表 ) 扩展: 对表中列进行计数:= Table.C ...
- Excel.CurrentWorkbook数据源(Power Query 之 M 语言)
数据源: 任意超级表 目标: 将超级表中的数据加载到Power Query编辑器中 操作过程: 选取超级表中任意单元格(选取普通表时会自动增加插入超级表的步骤)>数据>来自表格/区域 M公 ...
- 自定义函数(Power Query 之 M 语言)
数据源: 任意工作簿 目标: 使用自定义函数实现将数据源导入Power Query编辑器 操作过程: PowerQuery编辑器>主页>新建源>其他源>空查询 编辑栏内写入公式 ...
- M语言的写、改、删(Power Query 之 M 语言)
M语言基本上和其他语言一样,用敲键盘的方式写入.修改.删除,这个是废话. M语言可以在[编辑栏]或[高级编辑器]里直接写入.修改.删除,这个也是废话. M语言还有个地方可以写入.修改.删除,就是[自定 ...
- M语言的藏身之地(Power Query 之 M 语言)
M函数和M公式是Power Query专用的函数与公式,M代码是Power Query专用的用于实现查询功能的代码.M函数公式和M代码统称M语言. 查看M公式:[编辑栏] 查看方法:在Power Qu ...
- 转换…Transform…(Power Query 之 M 语言)
转换列: = Table.TransformColumns( 表, {{"列名1", 转换函数1, 数据类型1},-,{"列名n", 转换函数n, 数据类型n} ...
- Table.ReorderColumns移动…Reorder…(Power Query 之 M 语言)
数据源: 至少两列 目标: 列顺序重新排列 操作过程: 选取待移动的列>鼠标拖放列标题 选取待移动的列>[转换]>[移动]>选取 M公式: = Table.ReorderCo ...
- Table.FillDown填充Table.Fill…(Power Query 之 M 语言)
数据源: 任意列中包含空单元格 目标: 将空单元格填充为其上或其下单元格中的内容 操作过程: 选取指定列>[转换]>[填充]>[向下] 选取指定列>[转换]>[填充]&g ...
随机推荐
- [atARC126F]Affine Sort
记$g(k)$为$c$恰为$k$的合法三元组数,显然$f(k)=\sum_{i=1}^{k}g(i)$ 结论:若$\lim_{k\rightarrow \infty}\frac{g(k)}{k^{2} ...
- Go语言核心36讲(Go语言实战与应用十一)--学习笔记
33 | 临时对象池sync.Pool 到目前为止,我们已经一起学习了 Go 语言标准库中最重要的那几个同步工具,这包括非常经典的互斥锁.读写锁.条件变量和原子操作,以及 Go 语言特有的几个同步工具 ...
- springboot静态工具类bean的注入
工具类中调用数据.但是由于工具类方法一般都写成static,所以直接注入就存在问题. 所以写成了这样: package com.rm.framework.core; import org.spring ...
- 你有没有觉得邮件发送人固定配置在yml文件中是不妥当的呢?SpringBoot 动态设置邮件发送人
明月当天,不知道你有没有思念的人 前言 之前其实已经写过SpringBoot异步发送邮件,但是今天在一个小项目中要用到发送邮件时,我突然觉得邮件发送人只有一个,并且固定写在yml文件中,就是非常的不妥 ...
- 使用 CSS 轻松实现一些高频出现的奇形怪状按钮
背景 在群里会有同学问相关的问题,怎么样使用 CSS 实现一个内切角按钮呢.怎么样实现一个带箭头的按钮呢? 本文基于一些高频出现在设计稿中的,使用 CSS 实现稍微有点难度和技巧性的按钮,讲解使用 C ...
- C++ 编译错误记录
C++ _ZSt28__throw_bad_array_new_lengthv1 编译错误 出现场景:类似代码 vector<vector<int>> grid = {{1, ...
- Codeforces 1290F - Making Shapes(数位 dp)
Codeforces 题面传送门 & 洛谷题面传送门 数位 dp 好题. 首先,由于是凸包,一但向量集合确定,凸包的形态肯定就已经确定了.考虑什么样的向量集合能够组成符合条件的凸包,我们假设第 ...
- P4569 [BJWC2011]禁忌
题目传送门. 题意简述:给出大小为 \(n\) 的字典 \(s\).设函数 \(g(t)\) 表示 \(t\) 最多能被分割成的单词个数.等概率随机生成长度为 \(len\) 的字符串 \(T\),求 ...
- Java项目发现==顺手改成equals之后,会发生什么?
最近发生一件很尴尬的事情,在维护一个 Java 项目的时候,发现有使用 == 来比较两个对象的属性, 于是顺手就把 == 改成了 equals.悲剧发生...... == 和 equals 的区别 = ...
- Flume(二)【入门】
目录 一.安装部署 1.安装地址 2.安装步骤 二.入门案例 1.官方案例(nestat->logger) 2.实时监控单个追加文件(exec->hdfs) 3.实时监控目录下多个新文件( ...