Docker版EKL安装记录文档
Docker版EKL安装记录文档
- 拉取已下三个镜像
docker.io/logstash 7.5.2 b6518c95ed2f 6 months ago 805 MB
docker.io/kibana 7.5.2 a6e894c36481 6 months ago 950 MB
docker.io/elasticsearch 7.5.2 929d271f1798 6 months ago 779 MB
部署ES
- 修改系统配置文件
注意一
️准备 config,data,logs三个文件夹,文件夹里需要有配置的就config文件夹。
注意二
️ config 是elasticsearch容器默认的配置文件,我们需要修改elasticsearch.yml文件,不然还是启动不了,配置如下:
#cluster.name: "docker-cluster"
#network.host: 0.0.0.0
cluster.name: "docker-cluster"
node.name: node-1
network.host: 0.0.0.0
bootstrap.system_call_filter: false
cluster.initial_master_nodes: ["node-1"]
xpack.license.self_generated.type: basic
注意三
️ data,logs文件夹可手动创建,需要给他们root账号的读写执行权限,我这给的是775 权限足够了,权限可参考如下:
[root@localhost elasticsearch]# ls -al
总用量 0
drwxr-xr-x 6 root root 89 7月 21 16:45 .
drwxr-xr-x 5 root root 73 7月 21 16:25 ..
drwxr-xr-x 2 root root 178 7月 21 16:44 config
drwxrwxr-x 3 root root 27 7月 21 16:53 data
drwxrwxr-x 10 root root 283 7月 21 16:40 elasticsearch.bak
drwxrwxr-x 2 root root 133 7月 21 16:55 logs
- 最后docker run
docker run --name elasticsearch -p 9200:9200 -v /data/EKL/elasticsearch/config:/usr/share/elasticsearch/config -v /data/EKL/elasticsearch/data:/usr/share/elasticsearch/data -v /data/EKL/elasticsearch/logs:/usr/share/elasticsearch/logs -v /etc/localtime:/etc/localtime:ro -itd elasticsearch:7.5.2
注意四
️端口可以自己改,我这就默认了
确认一下是否起来了
[root@localhost elasticsearch]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1b0763e52708 elasticsearch:7.5.2 "/usr/local/bin/do..." 14 minutes ago Up 9 minutes 0.0.0.0:9200->9200/tcp, 9300/tcp elasticsearch
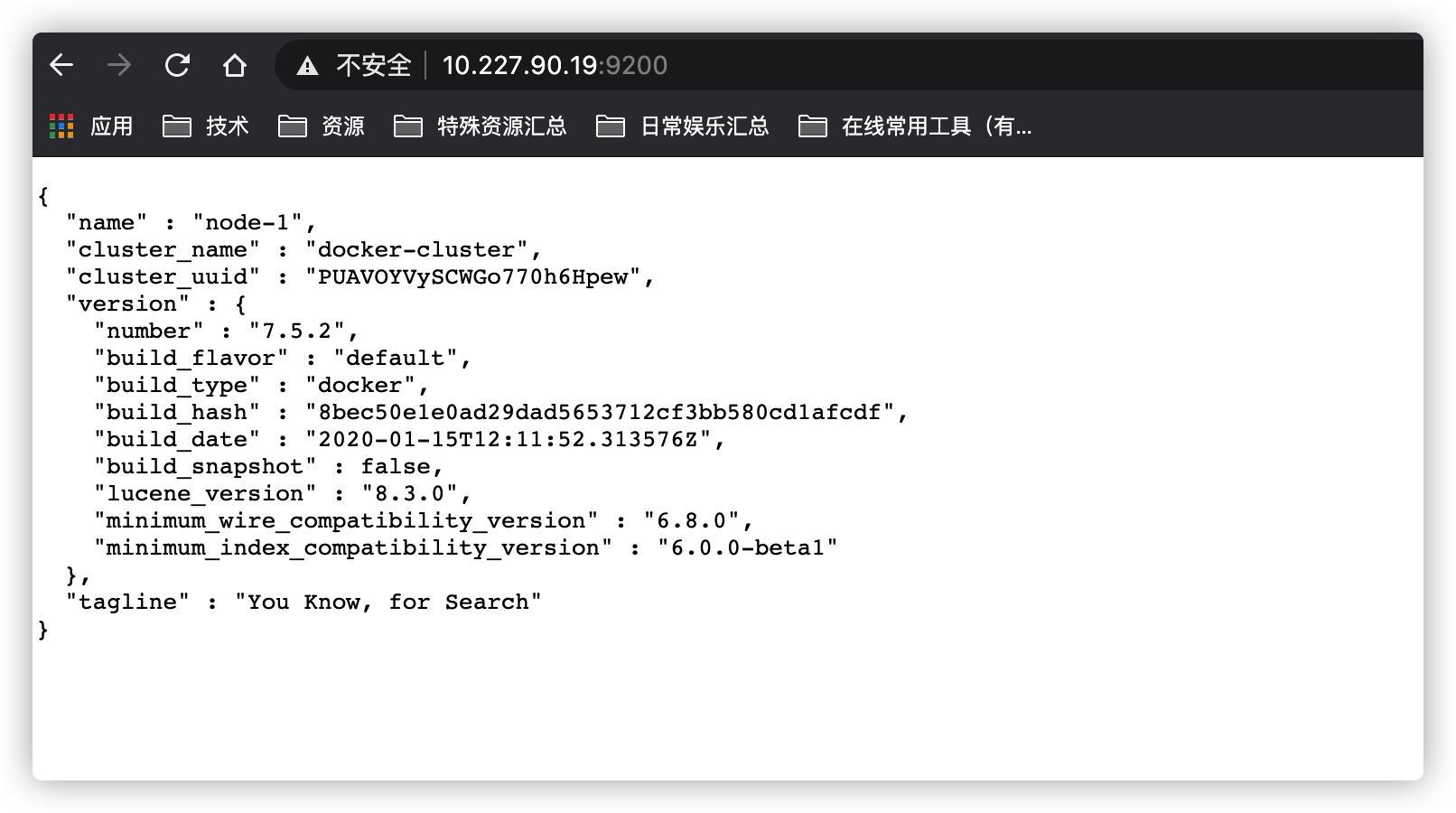
起来了后用浏览器访问一下 127.0.0.1:9200 (127.0.0.1是你自己宿主机的IP地址)
部署kibana
- 准备 kibana的 config 文件夹,配置内容如下
#
## ** THIS IS AN AUTO-GENERATED FILE **
##
#
## Default Kibana configuration for docker target
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://127.0.0.1:9200" ] # 127.0.0.1:9200改为你自己的elasticsearch地址
xpack.monitoring.ui.container.elasticsearch.enabled: true # 解释链接https://blog.csdn.net/u011311291/article/details/100041912
i18n.locale: zh-CN #汉化
kibana.index: ".kibana" #配置本地索引
- docker run 启动
docker run -itd --name kibana -p 5601:5601 -v /data/EKL/kibana/config:/usr/share/kibana/config -v /etc/localtime:/etc/localtime:ro kibana:7.5.2
注意五
️开放所用到的端口,我这里是9200,5601,浏览器访问127.0.0.1:5601 (127.0.0.1是你自己宿主机的IP)
部署logstash
- 准备好logstash的 config跟pipeline文件
注意六
️修改config下的 logstash.yml ; logstash-sample.conf 两个配置文件中的 elasticsearch 地址配置地址如下
[root@test config]# cat logstash.yml
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://127.0.0.1:9200" ]
[root@test config]# cat pipelines.yml
# This file is where you define your pipelines. You can define multiple.
# For more information on multiple pipelines, see the documentation:
# https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
- pipeline.id: main
path.config: "/usr/share/logstash/pipeline" #这是服务配置路径,可改。我这暂且不改。
[root@test config]# cat logstash-sample.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://127.0.0.1:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
注意七
️:以上 127.0.0.1:9200 需改为自己宿主机的地址
其实到这一步就差不多了,接下来就是对监控的logs做相关的配置了,我是对java的logs做个监控,需在 pipeline 下创建一个 java.conf (命名可改随你喜欢),配置如下
logstash日志配置
[root@test pipeline]# vim java.conf
input {
file{
path => "/DATA/logs/chenfan-base.log" #log路径
type => "base" # 打个标签
start_position => "beginning"
}
}
output {
if [type] == "base" { # 条件
elasticsearch {
hosts => ["127.0.0.1:9200"] #elasticsearch 服务地址
index => "base-%{+YYYY.MM.dd}" # 索引名字命名
codec => "json" #需将java日志装成json格式
}
}
}
docker run -itd --name logstash -p 5044:5044 -p 9600:9600 -v /DATA/logstash/docker/logstash/config:/usr/share/logstash/config -v /DATA/logstash/docker/logstash/pipeline:/usr/share/logstash/pipeline -v /DATA/logstash/log:/DATA/logs -v /etc/localtime:/etc/localtime:ro logstash:7.5.2
Docker版EKL安装记录文档的更多相关文章
- keepalived双机热备,安装部署文档
keepalived双击热备,安装部署文档: 下载目录:/apps/keepalived-1.2.7.tar.gz 1:---> yum install -y make wget 2:---&g ...
- Jmeter+Badboy安装使用文档
Jmeter+Badboy安装使用文档 目录 1.jmeter安装 1 2.Jmeter基础使用 3 3. 使用Jmeter进行分布式测试 ...
- Matlab R2018a版离线使用帮助文档方法
转载自:Matlab R2018a版离线使用帮助文档方法 问题 Matlab R2018a版本安装后,帮助文档默认为在线方式,需要使用账号登录,如果没有激活密钥或许可证编号,就无法使用帮助文档了. 方 ...
- Oracle client客户端简易安装网上文档一
Oracle client客户端简易安装网上文档一-------------------------------------------------------------------------一. ...
- k8s实验操作记录文档
k8s实验操作记录文档,仅供学习参考! 文档以实验操作的过程及内容为主进行记录,涉及少量的介绍性文字(来自网络开源). 仅汇总主题所有链接,详细内容查看需要切换到相关链接.https://github ...
- 电脑软件安装过程文档.BA
MD 01-打印并阅读-电脑软件安装过程文档.BAT-即此批处理脚本文档MD 02-阅读-电脑软件安装经验教训文档.DOCX-MD 03-制作-杏雨梨云USB维护系统2019中秋版之国庆更新-可启动U ...
- S01-晓亮的电脑软件安装过程文档 腾讯QQ 595076941 2019年10月
S01-晓亮的电脑软件安装过程文档 腾讯QQ 595076941 2019年10月 本文档的创建作者的腾讯QQ聊天号码是 595076941 S02-电脑软件安装过程中不要随意关闭窗口除非必需关闭窗口 ...
- Xcode离线安装帮助文档
Xcode离线安装帮助文档 1.在线查看帮助文件:Xcode下查看帮助文件,菜单Help-Developer Documentation在右上角搜索框中即可检索,但速度很慢,在线查看. 2.下载帮 ...
- CM5(Cloudera Manager 5) + CDH5(Cloudera's Distribution Including Apache Hadoop 5)的安装详细文档
参考 :http://www.aboutyun.com/thread-9219-1-1.html Cloudera Manager5及CDH5在线(cloudera-manager-installer ...
随机推荐
- 【不知道怎么分类】HDU - 5963 朋友
题目内容 B君在围观一群男生和一群女生玩游戏,具体来说游戏是这样的: 给出一棵n个节点的树,这棵树的每条边有一个权值,这个权值只可能是0或1. 在一局游戏开始时,会确定一个节点作为根.接下来从女生开始 ...
- go 下载图片
package main import ( "net/http" "fmt" "io/ioutil" "strings" ...
- centos8平台使用ulimit做系统资源限制
一,ulimit的用途 1, ulimit 用于shell启动进程所占用的资源,可用于修改系统资源限制 2, 使用ulimit -a 可以查看当前系统的所有限制值 使用ulimit -n <可以 ...
- Python初识和变量基础
Python是面向对象,动态解释型和强类型的语言 编译型: 将代码一次性全部编译成二进制,然后再执行 优点:执行效率高. 缺点:开发效率低. 代表语言:C 解释型: 逐行解释成二进制,逐行运行 优点: ...
- 【API管理 APIM】APIM中如何配置使用URL路径的方式传递参数(如由test.htm?name=xxx 变为test\xxx)
问题描述 在默认的URL传递参数中,我们使用的是https://test01.azure-api.cn/echo/resource?param1=sample¶m2=testname这 ...
- 了解Js中的client,offset
Client clientWidth,clientHeight 元素内部的宽度和高度,clientTop,clientLeft 元素内边距到其边框的距离,clientX,clientY相当于浏览器窗口 ...
- 腾讯云服务器简单配置web项目
如图:目前域名备案工作完成,需要将主页展示出来, 域名解析就不讲了,超级简单, 如果不理解可以加群交流,这里主要讲一下通过Apache 开启服务(80端口)对项目进行展示 1. 首先安装Apache ...
- JUC---05线程间通信(一)
一.普通的线程间通信 1.synchronized实现 package com.jenne.mydemo; class ShareDataOne { private int number = 0; p ...
- Redis常用命令(1)——Key
DEL 格式:DEL key [key ...] 作用:删除一个或多个 key.不存在的 key 会被忽略. 返回值:被删除 key 的数量. 示例: 192.168.1.100:6379> s ...
- 团灭 LeetCode 打家劫舍问题
有读者私下问我 LeetCode 「打家劫舍」系列问题(英文版叫 House Robber)怎么做,我发现这一系列题目的点赞非常之高,是比较有代表性和技巧性的动态规划题目,今天就来聊聊这道题目. 打家 ...