k8s控制器资源
k8s控制器资源
Pod
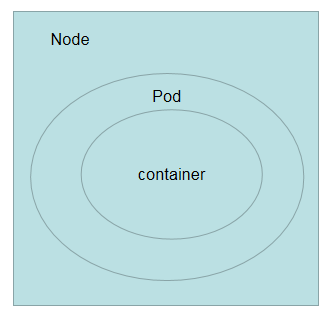
pod在之前说过,pod是kubernetes集群中是最小的调度单元,pod中可以运行多个容器,而node又可以包含多个pod,关系如下图:
在对pod的用法进行说明之前,有必要先对docker容器进行说明
在使用docker时,可以使用docker run命令创建一个容器,而在kubernetes集群中对长时间运行容器的要求是:
- 主程序需要一直在前台执行
如果我们创建的docker镜像的启动命令是后台执行程序,例如Linux脚本:
nohup ./start.sh &
那么kubelet在创建这个Pod执行完这个命令后,会认为这个Pod执行完毕,从而进行销毁pod,如果pod定义了ReplicationController,那么销毁了还会在创建,继续执行上述的命令然后又销毁,然后又重建,这样就会陷入恶性循环,这也是为什么执行的命令要运行在前台的原因,这一点一定要注意
Pod生命周期和重启策略

Pod的重启策略(RestartPolicy):
- Always:当容器失败时,由kubelet自动重启该容器
- OnFailure:当容器终止运行且退出代码不为0的时候,由kubelet自动重启
- Never:不论容器运行状态如何,kubelet永远都不会重启该容器
Pod的重启策略和控制器息息相关,每种控制器对Pod的重启策略如下:
- RC和DaemonSet:必须设置为Always,需要保证该容器持续运行
- Job:OnFailure和Never,确保容器执行完毕后不在重启
- kubelet:在Pod失效时自动重启它,不论将RestartPolicy设置成什么值,也不会对Pod进行健康检查
我们简单介绍完kubernetes的逻辑结构之后我们来看一下k8s控制器资源,k8s控制器资源分很多种,有replication controller,deployment,Horizontal pod autoscaler,statefulSet,daemonSet,job等...,接下来我们来详细分析一下下面资源的使用场景和区别
replication Controller控制器
replication controller简称RC,是kubernetes系统中的核心概念之一,简单来说,它其实定义了一个期望的场景,即声明某种pod的副本数量在任意时刻都复合某个预期值,所以RC的定义包含以下部分:
- pod期待的副本数量
- 用于筛选目标pod的Label Selector
- 当pod的副本数量小于期望值时,用于创建新的pod的pod模板(template)
下面是一个完整的RC定义的例子,即确保拥有app=mynginx标签的这个pod在整个kubernetes集群中始终只有一个副本,红色字体一定要一直,因为我们的控制器就是根据标签筛选出来的(因为pod的ip和pod名字都会变化):

[root@master ~]# vim nginx.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: myweb
namespace: default
spec:
replicas: 1
selector:
app: mynginx
template:
metadata:
labels:
app: mynginx
spec:
containers:
- name: mycontainer
image: lizhaoqwe/nginx:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
在我们定义了一个RC并将其提交到kubernetes集群中后,master上的controller Manager组件就得到了通知,定期巡检系统中当前存货的目标pod,并确保目标pod实力数量刚好等于此RC的期望值,如果多余期望值,则停掉一些,如果少于期望值会再创建一些。
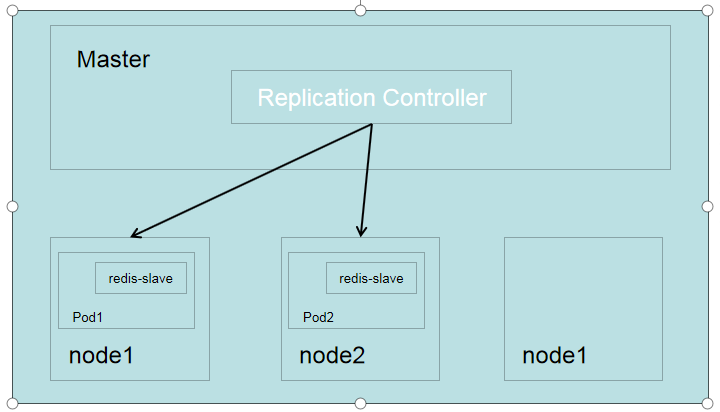
以下面3个Node节点的集群为例,说明kubernetes是如何通过RC来实现pod副本数量自动控制的机制,我们创建2个pod运行redis-slave,系统可能会再两个节点上创建pod,如下图
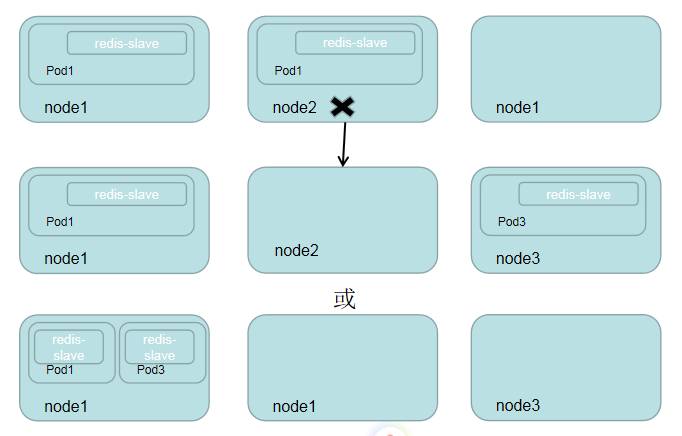
假设Node2上的pod意外终止,则根据RC定义的replicas数量1,kubernetes将会自动创建并启动两个新的pod,以保证在整个集群中始终有两个redis-slave Pod运行,如下图所示,系统可能选择Node3或者Node1来创建新的pod
此外,我们还可以通过修改RC的副本数量,来实现Pod的动态扩容和缩容
[root@master ~]# kubectl scale --replicas=3 rc myweb
replicationcontroller/myweb scaled
结果如下

这里需要注意的是,删除RC并不会影响通过该RC已创建好的pod,为了删除所有pod,可以设置replicas的值为0,然后更新该RC,另外,kubectl提供了stop和delete命令来一次性删除RC和RC控制的全部Pod
ReplicaSet
上一阶段讲过了ReplicationController控制器之后,相信大家对其已经了解了,ReplicaSet控制器其实就是ReplicationController的升级版,官网解释为下一代的“RC”,ReplicationController和ReplicaSet的唯一区别是ReplicaSet支持基于集合的Label selector,而RC只支持基于等式的Label Selector,这使得ReplicaSet的功能更强,下面等价于之前的RC例子的ReokucaSet的定义
[root@master ~]# vim replicaSet.yaml
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: myweb
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: mynginx
matchExpressions:
- {key: app, operator: In, values: [mynginx]}
template:
metadata:
labels:
app: mynginx
spec:
containers:
- name: mycontainer
image: lizhaoqwe/nginx:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
kubectl命令行工具适用于RC的绝大部分命令同样适用于ReplicaSet,此外,我们当前很少单独适用ReplicaSet,它主要被Deployment这个更高层的资源对象所使用,从而形成一整套Pod创建,删除,更新的编排机制,我们在使用Deployment时无需关心它是如何维护和创建ReplicaSet的,这一切都是自动发生的
最后,总结一下RC(ReplicaSet)的一些特性和作用:
- 在绝大多数情况下,我们通过定义一个RC实现Pod的创建及副本数量的自动控制
- 在RC里包括完整的Pod定义模板
- RC通过Label Selector机制实现对Pod副本的自动控制
- 通过改变RC里的Pod副本数量,可以实现Pod的扩容和缩容
- 通过改变RC里Pod模板中的镜像版本,可以实现滚动升级
Deployment
Deployment是kubernetes在1.2版本中引入的新概念,用于更好的解决Pod的编排问题,为此,Deployment在内部使用了ReplicaSet来实现目的,我们可以把Deployment理解为ReplicaSet的一次升级,两者的相似度超过90%
Deployment的使用场景有以下几个:
- 创建一个Deployment对象来生成对应的ReplicaSet并完成Pod副本的创建
- 检查Deployment的状态来看部署动作是否完成(Pod副本数量是否达到了预期的值)
- 更新Deployment以创建新的Pod(比如镜像升级)
- 如果当前Deployment不稳定,可以回滚到一个早先的Deployment版本
- 暂停Deployment以便于一次性修改多个PodTemplateSpec的配置项,之后在恢复Deployment,进行新的发布
- 扩展Deployment以应对高负载
- 查看Deployment的状态,以此作为发布是否成功的纸币哦
- 清理不在需要的旧版本ReplicaSet
除了API生命与Kind类型有区别,Deployment的定义与Replica Set的定义很类似,我们这里还是以上面为例子
apiVersion: extensions/v1beta1 apiVersion: apps/v1
kind: ReplicaSet kind: Deployment
执行文件
[root@master ~]# kubectl apply -f deploy.yaml
deployment.apps/myweb created
查看结果
[root@master ~]# kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
myweb 1/1 1 1 5m5s
解释一下上面的显示
NAME:你的deployment控制器的名字
READY:已经准备好的Pod个数/所期望的Pod个数
UP-TO-DATE:最新版本的Pod数量,用于在执行滚动升级时,有多少个Pod副本已经成功升级
AVAILABLE:当前集群中可用的Pod数量,也就是集群中存活的Pod数量
StatefulSet
在kubernetes系统中,Pod的管理对象RC,Deployment,DaemonSet和Job都面向无状态的服务,但现实中有很多服务时有状态的,比如一些集群服务,例如mysql集群,集群一般都会有这四个特点:
- 每个节点都是有固定的身份ID,集群中的成员可以相互发现并通信
- 集群的规模是比较固定的,集群规模不能随意变动
- 集群中的每个节点都是有状态的,通常会持久化数据到永久存储中
- 如果磁盘损坏,则集群里的某个节点无法正常运行,集群功能受损
如果你通过RC或Deployment控制Pod副本数量来实现上述有状态的集群,就会发现第一点是无法满足的,因为Pod名称和ip是随机产生的,并且各Pod中的共享存储中的数据不能都动,因此StatefulSet在这种情况下就派上用场了,那么StatefulSet具有以下特性:
- StatefulSet里的每个Pod都有稳定,唯一的网络标识,可以用来发现集群内的其它成员,假设,StatefulSet的名称为fengzi,那么第1个Pod叫fengzi-0,第2个叫fengzi-1,以此类推
- StatefulSet控制的Pod副本的启停顺序是受控的,操作第N个Pod时,前N-1个Pod已经是运行且准备状态
- StatefulSet里的Pod采用稳定的持久化存储卷,通过PV或PVC来实现,删除Pod时默认不会删除与StatefulSet相关的存储卷(为了保证数据的安全)
StatefulSet除了要与PV卷捆绑使用以存储Pod的状态数据,还要与Headless,Service配合使用,每个StatefulSet定义中都要生命它属于哪个Handless Service,Handless Service与普通Service的关键区别在于,它没有Cluster IP
DemonSet
在每一个node节点上只调度一个Pod,因此无需指定replicas的个数,比如:
- 在每个node上都运行一个日志采集程序,负责收集node节点本身和node节点之上的各个Pod所产生的日志
- 在每个node上都运行一个性能监控程序,采集该node的运行性能数据
[root@localhost ~]# cat daemon.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-cloud-logging
namespace: kube-system
labels:
k8s-app: fluentd-cloud-logging
spec:
selector:
matchLabels:
k8s-app: fluentd-cloud-logging
template:
metadata:
namespace: kube-system
labels:
k8s-app: fluentd-cloud-logging
spec:
containers:
- name: fluentd-cloud-logging
image: kayrus/fluentd-elasticsearch:1.20
resources:
limits:
cpu: 100m
memory: 200Mi
env:
- name: FLUENTD_ARGS
value: -q
volumeMounts:
- name: varlog
mountPath: /var/log
readOnly: false
- name: containers
mountPath: /var/lib/docker/containers
readOnly: false
volumes:
- name: containers
hostPath:
path: /usr
- name: varlog
hostPath:
path: /usr/sbin
查看pod所在的节点
[root@localhost ~]# kubectl get pods -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-bccdc95cf-8sqzn 1/1 Running 2 2d7h 10.244.0.6 master <none> <none>
coredns-bccdc95cf-vt8nz 1/1 Running 2 2d7h 10.244.0.7 master <none> <none>
etcd-master 1/1 Running 1 2d7h 192.168.254.13 master <none> <none>
fluentd-cloud-logging-6xx4l 1/1 Running 0 4h24m 10.244.2.7 node2 <none> <none>
fluentd-cloud-logging-qrgg6 1/1 Rruning 0 4h24m 10.244.1.7 node1 <none> <none>
kube-apiserver-master 1/1 Running 1 2d7h 192.168.254.13 master <none> <none>
kube-controller-manager-master 1/1 Running 1 2d7h 192.168.254.13 master <none> <none>
kube-flannel-ds-amd64-c97wh 1/1 Running 0 2d7h 192.168.254.12 node1 <none> <none>
kube-flannel-ds-amd64-gl6wg 1/1 Running 1 2d7h 192.168.254.13 master <none> <none>
kube-flannel-ds-amd64-npsqf 1/1 Running 0 2d7h 192.168.254.10 node2 <none> <none>
kube-proxy-gwmx8 1/1 Running 1 2d7h 192.168.254.13 master <none> <none>
kube-proxy-phqk2 1/1 Running 0 2d7h 192.168.254.12 node1 <none> <none>
kube-proxy-qtt4b 1/1 Running 0 2d7h 192.168.254.10 node2 <none> <none>
kube-scheduler-master 1/1 Running 2 2d7h 192.168.254.13 master <none> <none>
k8s控制器资源的更多相关文章
- k8s控制器资源(五)
Pod pod在之前说过,pod是kubernetes集群中是最小的调度单元,pod中可以运行多个容器,而node又可以包含多个pod,关系如下图: 在对pod的用法进行说明之前,有必要先对docke ...
- Kubernetes K8S之资源控制器StatefulSets详解
Kubernetes的资源控制器StatefulSet详解与示例 主机配置规划 服务器名称(hostname) 系统版本 配置 内网IP 外网IP(模拟) k8s-master CentOS7.7 2 ...
- Kubernetes K8S之资源控制器Daemonset详解
Kubernetes的资源控制器Daemonset详解与示例 主机配置规划 服务器名称(hostname) 系统版本 配置 内网IP 外网IP(模拟) k8s-master CentOS7.7 2C/ ...
- Kubernetes K8S之资源控制器Job和CronJob详解
Kubernetes的资源控制器Job和CronJob详解与示例 主机配置规划 服务器名称(hostname) 系统版本 配置 内网IP 外网IP(模拟) k8s-master CentOS7.7 2 ...
- K8s容器资源限制
在K8s中定义Pod中运行容器有两个维度的限制: 1. 资源需求:即运行Pod的节点必须满足运行Pod的最基本需求才能运行Pod. 如: Pod运行至少需要2G内存,1核CPU 2. 资源限额: ...
- k8s核心资源之Pod概念&入门使用讲解(三)
目录 1. k8s核心资源之Pod 1.1 什么是Pod? 1.2 Pod如何管理多个容器? 1.3 Pod网络 1.4 Pod存储 1.5 Pod工作方式 1.5.1 自主式Pod 1.5.2 控制 ...
- k8s之资源限制以及探针检查
k8s之资源限制以及探针检查 一.资源限制 1. 资源限制的使用 当定义Pod时可以选择性地为每个容器设定所需要的资源数量.最常见的可设定资源是CPU和内存大小,以及其他类型的资源. 2. reuqe ...
- K8s控制器
K8s控制器 POD分类 #自主式pod:退出后,不会被创建 #控制器管理的pod:在控制器的生命周期内,始终位置pod的副本数 控制器类型 ReplicationController和Replica ...
- 8.深入k8s:资源控制Qos和eviction及其源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com,源码版本是1.19 又是一个周末,可以愉快的坐下来静静的品味一段源码,这一篇涉及到资源的 ...
随机推荐
- Python基础入门知识点——深浅拷贝
深浅拷贝 对象引用.浅拷贝.深拷贝(拓展.难点.重点) Python中,对象的赋值,拷贝(深/浅拷贝)之间是有差异的,如果使用的时候不注意,就可能产生意外的结果 其实这个是由于共享内存导致的结果 拷贝 ...
- Jmeter系列(49)- 详解 HTTP Cookie 管理器
如果你想从头学习Jmeter,可以看看这个系列的文章哦 https://www.cnblogs.com/poloyy/category/1746599.html 简单介绍 功能一 首先,它像网络浏览器 ...
- 微信公众号请求code时报redirect_uri 参数错误
(1) 检查微信公众号中"接口权限"--"网页授权获取用户基本信息"中的网页授权域名.域名不带http(s) (2)如果在拼接跳转到微信授权接口的URL时,使用 ...
- sqlalchemy怎么order_by降序/升序并取第一条数据
原文链接:https://blog.csdn.net/mark4541437/article/details/103755721 sqlalchemy怎么order_by降序/升序并取第一条数据 fr ...
- String,StringBuffer,StringBuillder的底层结构
一:StringBuffer的底层 (1)线程安全的字符串操作类 (2)通过synchronized关键字声明同步方法,保证多线程环境下数据安全 public synchronized StringB ...
- 第5篇 Scrum 冲刺博客
1.站立会议 照骗 进度 成员 昨日完成任务 今日计划任务 遇到的困难 钟智锋 完成技能 完全重构游戏逻辑代码,并编写调试模块 队友的代码已经和想法相去甚远 庄诗楷 制作了开始游戏的界面 进行了相关的 ...
- 第三篇 Scrum冲刺博客
一.会议图片 二.项目进展 成员 完成情况 今日任务 冯荣新 商品列表,商品详情轮播图 商品底部工具栏,购物车列表 陈泽佳 历史足迹,静态页面 渲染搜索结果,防抖的实现 徐伟浩 未完成 商品信息录入 ...
- Understanding dopamine and reinforcement learning: The dopamine reward prediction error hypothesis
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Abstract 在中脑多巴胺能神经元的研究中取得了许多最新进展.要了解这些进步以及它们之间的相互关系,需要对作为解释框架并指导正在进行的 ...
- foreach循環體控制
通常情況下,在程式中的cursor定義之前,整合了l_sql變量后,轉化sql語句時,通過檢查STATUS的值來判斷sql語句是否有錯誤. 語句如: if STATUS th ...
- 图数据库对比:Neo4j vs Nebula Graph vs HugeGraph
本文系腾讯云安全团队李航宇.邓昶博撰写 图数据库在挖掘黑灰团伙以及建立安全知识图谱等安全领域有着天然的优势.为了能更好的服务业务,选择一款高效并且贴合业务发展的图数据库就变得尤为关键.本文挑选了几款业 ...