Python-用xlrd模块读取excel,数字都是浮点型,日期格式是数字的解决办法
excel文件内容:
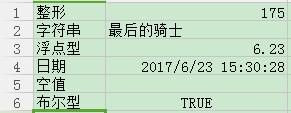
读取excel:

# coding=utf-8
import xlrd
import sys reload(sys)
sys.setdefaultencoding('utf-8')
import traceback class excelHandle:
def decode(self, filename, sheetname):
try:
filename = filename.decode('utf-8')
sheetname = sheetname.decode('utf-8')
except Exception:
print traceback.print_exc()
return filename, sheetname def read_excel(self, filename, sheetname):
filename, sheetname = self.decode(filename, sheetname)
rbook = xlrd.open_workbook(filename)
sheet = rbook.sheet_by_name(sheetname)
rows = sheet.nrows
cols = sheet.ncols
all_content = []
for i in range(rows):
row_content = []
for j in range(cols):
cell = sheet.cell_value(i, j)
row_content.append(cell)
all_content.append(row_content)
print '[' + ','.join("'" + str(element) + "'" for element in row_content) + ']'
return all_content if __name__ == '__main__':
eh = excelHandle()
filename = r'G:\test\ctype.xls'
sheetname = 'Sheet1'
eh.read_excel(filename, sheetname)
输出:
['整形','175.0']
['字符串','最后的骑士']
['浮点型','6.23']
['日期','42909.6461574']
['空值','']
['布尔型','1']
可以看到,数字一律按浮点型输出,日期却输出成一串小数?!布尔型输出0或1
代码稍做改动:来看一看表格的数据类型
for i in range(rows):
row_content = []
for j in range(cols):
ctype = sheet.cell(i, j).ctype #表格的数据类型
print ctype,
cell = sheet.cell_value(i, j)
row_content.append(cell)
all_content.append(row_content)
print '[' + ','.join("'" + str(element) + "'" for element in row_content) + ']'
输出:
1 2
['整形','175.0']
1 1
['字符串','最后的骑士']
1 2
['浮点型','6.23']
1 3
['日期','42909.6461574']
1 0
['空值','']
1 4
['布尔型','1']
python读取excel中单元格的内容返回的有5种类型,即上面例子中的ctype:
ctype: 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
所以,判断一下ctype,然后再做相应处理就可以了。
最终代码:
# coding=utf-8
import xlrd
import sys reload(sys)
sys.setdefaultencoding('utf-8')
import traceback
from datetime import datetime
from xlrd import xldate_as_tuple class excelHandle:
def decode(self, filename, sheetname):
try:
filename = filename.decode('utf-8')
sheetname = sheetname.decode('utf-8')
except Exception:
print traceback.print_exc()
return filename, sheetname def read_excel(self, filename, sheetname):
filename, sheetname = self.decode(filename, sheetname)
rbook = xlrd.open_workbook(filename)
sheet = rbook.sheet_by_name(sheetname)
rows = sheet.nrows
cols = sheet.ncols
all_content = []
for i in range(rows):
row_content = []
for j in range(cols):
ctype = sheet.cell(i, j).ctype # 表格的数据类型
cell = sheet.cell_value(i, j)
if ctype == 2 and cell % 1 == 0: # 如果是整形
cell = int(cell)
elif ctype == 3:
# 转成datetime对象
date = datetime(*xldate_as_tuple(cell, 0))
cell = date.strftime('%Y/%d/%m %H:%M:%S')
elif ctype == 4:
cell = True if cell == 1 else False
row_content.append(cell)
all_content.append(row_content)
print '[' + ','.join("'" + str(element) + "'" for element in row_content) + ']'
return all_content if __name__ == '__main__':
eh = excelHandle()
filename = r'G:\test\ctype.xls'
sheetname = 'Sheet1'
eh.read_excel(filename, sheetname)
输出:
['整形','175']
['字符串','最后的骑士']
['浮点型','6.23']
['日期','2017/23/06 15:30:28']
['空值','']
['布尔型','True']
Python-用xlrd模块读取excel,数字都是浮点型,日期格式是数字的解决办法的更多相关文章
- python使用xlrd模块读写Excel文件的方法
本文实例讲述了python使用xlrd模块读写Excel文件的方法.分享给大家供大家参考.具体如下: 一.安装xlrd模块 到python官网下载http://pypi.python.org/pypi ...
- Python xlrd模块读取Excel表中的数据
1.xlrd库的安装 直接使用pip工具进行安装(当然也可以使用pycharmIDE进行安装,这里就不详述了) pip install xlrd 2.xlrd模块的一些常用命令 ①打开excel文件并 ...
- Xlrd模块读取Excel文件数据
Xlrd模块使用 excel文件样例:
- 常用方法 读取 Excel的单位格 为 日期格式 的数据
原文:地址忘了 百度应该有 Excel的单元格为日期格式,数值型日期,可用下面这个方法得到正常的数据 /// <summary> /// 数字格式的时间 转换为 字符串格式的时间 /// ...
- python 利用三方的xlrd模块读取excel文件,处理合并单元格
目的: python能使用xlrd模块实现对Excel数据的读取,且按照想要的输出形式. 总体思路: (1)要想实现对Excel数据的读取,需要用到第三方应用,直接应用. (2)实际操作时候和我 ...
- python使用xlrd模块读写excel
1.行列索引均从0开始2.int数据被读成float数据,解决办法,if type(value) == float and value%1 == 0,value= int(value)模块读 #!/u ...
- 基础补充:使用xlrd模块读取excel文件
因为接口测试用例使用excel文件来维护的,所以有必要学习下操作excel的基本方法 参考博客:python 3 操作 excel 把自己练习的代码贴出来,是一些基本的操作,每行代码后面都加了注释. ...
- 利用xlrd模块读取excel利用json模块生成相应的json文件的脚本
excel的格式如下 python代码如下,这里最难的就是合并单元格的处理 import xlrd import json excel_obj = xlrd.open_workbook("t ...
- Python之xlrd模块读取xls文件与报错解决
安装 pip3 install xlrd 用法 Sheet编号从0开始 rows,colnum编号均从0开始 合并的单元格仅返回第一格内容 Sheets只能被调用一次,可获取所有sheet取idx 无 ...
- python-利用xlrd模块读取excel数据,将excel数据转换成字典格式
前言 excel测试案例数据 转换成这种格式 实现代码 import os import xlrd excel_path = '..\data\\test_case.xlsx' data_path = ...
随机推荐
- 温故知新-快速理解Linux网络I/O
文章目录 摘要 阻塞.非阻塞.同步.异步 Linux下的I/O模型 阻塞I/O模型 非阻塞I/O模型 I/O复用模型 select poll epoll 信号驱动I/O模型 异步I/O 参考 你的鼓励 ...
- 使用wrk进行http压力测试
Posted by 微博@Yangsc_o 原创文章,版权声明:自由转载-非商用-非衍生-保持署名 | Creative Commons BY-NC-ND 3.0 最近做了一些服务器的工作,在做htt ...
- vue2.0+Element UI 表格前端分页和后端分页
之前写过一篇博客,当时对element ui框架还不太了解,分页组件用 html + css 自己写的,比较麻烦,而且只提到了后端分页 (见 https://www.cnblogs.com/zdd20 ...
- CSS里盒子模型中【margin垂直方向边界叠加】问题及解决方案
边界重叠是指两个或多个盒子(可能相邻也可能嵌套)的相邻边界(其间没有任何非空内容.补白.边框)重合在一起而形成一个单一边界. 两个或多个块级盒子的垂直相邻边界会重合. 如果都是正边界,结果的边界宽度是 ...
- Calculating a “Row X of Y”
显示 “Row X of Y,” ,X是当前行,Y是总行数, 那就是 ROW_NUMBER(ORDER BY stor_id) of Count(*) OVER()此处还是以样例数据库 pub 为例 ...
- mysql常用基础指令大全
mysql指令 启动 net start mysql 退出mysql quit 登录 mysql -uroot -p 逻辑非 not ! 逻辑与 and && 或者 or || 逻辑异 ...
- Android学习笔记使用AlertDialog实现对话框
使用AlertDialog可以实现如下对话框 案例 布局问文件就加了几个Button,我直接上Java代码了 实现显示带取消,确定按钮的对话框按钮 Button showDialogOne = fin ...
- Cookie 和 Session 关系详解
什么是 Cookie 和 Session ? 什么是 Cookie HTTP Cookie(也叫 Web Cookie或浏览器 Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据,它会在 ...
- WeChair项目Beta冲刺(9/10)
团队项目进行情况 1.昨日进展 Beta冲刺第九天 昨日进展: 项目开始扫尾 2.今日安排 前端:前端工作已经完成 后端:扫码占座后端测试,实现对超时预约座位下座的功能 数据库:和后端组织协商扫 ...
- 初识Java Java基础知识
今天给大家带来的是初级Java基础部分的知识:包括初识Java.变量.常量.数据类型.运算符.各种选择结构.循环结构.数组等Java的基础语法部分!!!内容.步骤超详细,附有各种案例的源代码(可以直接 ...