Python爬虫-换行的匹配
之前在学习爬虫的时候遇到了匹配内容时发现存在换行,这时没法匹配了,后来在网上找到了一种方法,当时懒得记录,今天突然有遇到了这种情况,想想还是在这里记录一下吧。
当时爬取的时csdn首页博客,如下图
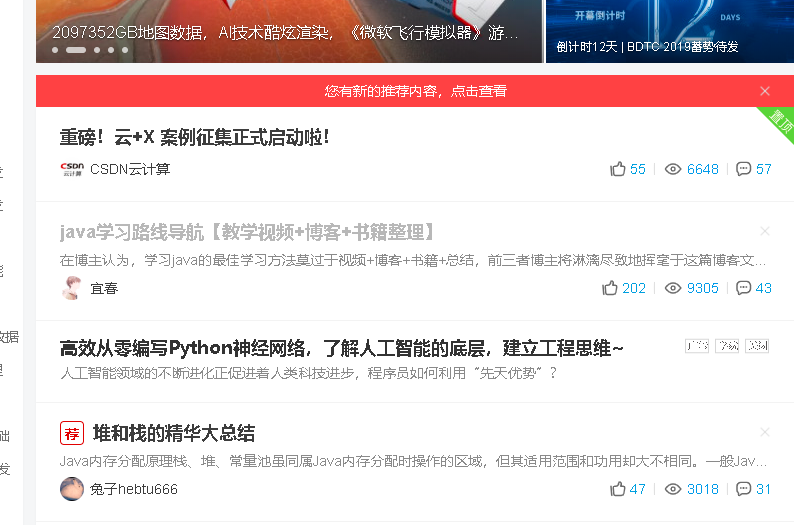
看了源代码,发现如果使用<a href="....来爬取的话,这样得到的会有许多其他的网址,并不全是我需要得博文,但是用<div class="title">去匹配后面的又出现了换行,但是换行匹配我又不会。。。。
re.compile()函数的一个标志参数叫re.DOTALL,它可以让正则表达式中的点(.)匹配包括换行符在内的任意字符。
pat = ' <div class="title">.*?<h2>.*?<a href="(.*?)" target="_blank"' # 此时的.就可以匹配包括换行在内的任意字符
rst1 = re.compile(pat, re.DOTALL).findall(data)

import urllib.request
import re
url = "http://www.csdn.net/"
data = urllib.request.urlopen(url).read().decode("utf-8")
print(len(data))
pat = ' <div class="title">.*?<h2>.*?<a href="(.*?)" target="_blank"'
rst1 = re.compile(pat, re.DOTALL).findall(data)
print(len(rst1))
for i in range(0, len(rst1)):
print(rst1[i])
data = urllib.request.urlopen(rst1[i]).read().decode("utf-8", "ignore")
urllib.request.urlretrieve(rst1[i], "D:\\python\\studyPython\\爬虫学习\\学习urllib\\blog\\"+str(i+1)+".html")
print("爬取第:", i+1, "篇博客成功")
print("首页所有博客爬取结束")
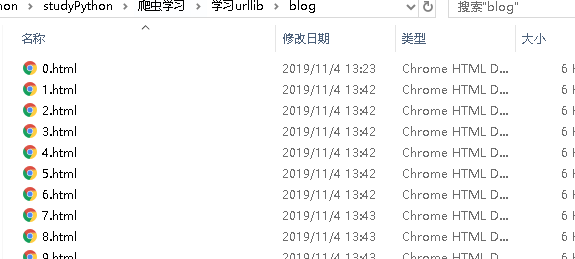
此时则爬取成功
Python爬虫-换行的匹配的更多相关文章
- Python正则表达式-换行的匹配
找到了之前参考的博文,用来记录一下https://www.cnblogs.com/baxianhua/p/8572805.html 平常 点 (.)去匹配任意字符的时候,是不能匹配换行符的 匹配换行: ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- 【Python爬虫】入门知识
爬虫基本知识 这阵子需要用爬虫做点事情,于是系统的学习了一下python爬虫,觉得还挺有意思的,比我想象中的能干更多的事情,这里记录下学习的经历. 网上有关爬虫的资料特别多,写的都挺复杂的,我这里不打 ...
- Python实战:Python爬虫学习教程,获取电影排行榜
Python应用现在如火如荼,应用范围很广.因其效率高开发迅速的优势,快速进入编程语言排行榜前几名.本系列文章致力于可以全面系统的介绍Python语言开发知识和相关知识总结.希望大家能够快速入门并学习 ...
- python爬虫之re正则表达式库
python爬虫之re正则表达式库 正则表达式是用来简洁表达一组字符串的表达式. 编译:将符合正则表达式语法的字符串转换成正则表达式特征 操作符 说明 实例 . 表示任何单个字符 [ ] 字符集,对单 ...
- Python爬虫初学(二)—— 爬百度贴吧
Python爬虫初学(二)-- 爬百度贴吧 昨天初步接触了爬虫,实现了爬取网络段子并逐条阅读等功能,详见Python爬虫初学(一). 今天准备对百度贴吧下手了,嘿嘿.依然是跟着这个博客学习的,这次仿照 ...
- 【转】Python爬虫:抓取新浪新闻数据
案例一 抓取对象: 新浪国内新闻(http://news.sina.com.cn/china/),该列表中的标题名称.时间.链接. 完整代码: from bs4 import BeautifulSou ...
- Python爬虫与数据分析之模块:内置模块、开源模块、自定义模块
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- python爬虫之Beautiful Soup的基本使用
1.简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索 ...
随机推荐
- K8S-ETCD数据库备份与恢复
kubernetes使用etcd数据库实时存储集群中的数据,安全起见,一定要备份 需要指定使用etcdctl的版本 etcd数据库备份是使用数控快照的方式进行备份的,备份后的新数据不会保留,后面创建的 ...
- MySQL基础 :基本知识点大纲
- Springboot集成logback,控制台日志打印两次,并且是不同的线程打印的
背景 在搭建一个新项目的时候,从公司别的项目搞了个logback-spring.xml的配置过来,修改一下启动项目的时候发现 所有的日志都输出了两次 并且来自于不同的线程,猜测是配置重复了,但是仔细检 ...
- 11 . Nginx核心原理讲解
应用场景优缺点 应用场景 // 1.静态请求 // 2.反向代理 // 3.负载均衡 // 4.资源缓存 // 5.安全防护 // 6.访问限制IP // 7.访问认证 /* 核心主要是以下三个应用: ...
- ansible-playbook通过github拉取部署Lnmp环境
1. 配置服务器初始化 1.1) 关闭防火墙和selinux 1 [root@test-1 ~]# /bin/systemctl stop firewalld 2 [root@test-1 ~]# ...
- 2016-12-04---tiny412平台下的iconv库的移植问题
一.解决问题 在arm开发板上使用framebuff,在汉字显示时,因为只有gb2312的16*16的汉字字库,而ubuntu16.04默认 的编码方式时utf-8,因此需要进行转码(ut ...
- Java 移位运算、符号位扩展
类型取值范围 short 是1字节,即8位.而且 Java 中只有有符号数,所以最大值 0111,1111=2^7-1. 同时计算机中以补码形式存负数,所以可以多表示一个数,则最小值 1000,000 ...
- 在实际开发中Java中enum的用法
在日常项目的开发中,往往会存在一些固定的值,而且"数据集"中的元素是有限的. 例如:st_code// 一些状态机制:01-激活 02-未激活 03 -注册..等等 还有一特性 ...
- Cypress系列(67)- 环境变量设置指南
如果想从头学起Cypress,可以看下面的系列文章哦 https://www.cnblogs.com/poloyy/category/1768839.html 常见的环境变量设置方式 可参考这篇文章: ...
- leaflet实现台风动态轨迹
leaflet平台是我最新使用的webGIS平台,该平台比较轻巧以下是我展示台风动态路径展示 1.首先为大家展示一下动态台风所使用数据 上面中采用标准json格式数据,data数据中,points是对 ...