Python爬虫-换行的匹配
之前在学习爬虫的时候遇到了匹配内容时发现存在换行,这时没法匹配了,后来在网上找到了一种方法,当时懒得记录,今天突然有遇到了这种情况,想想还是在这里记录一下吧。
当时爬取的时csdn首页博客,如下图
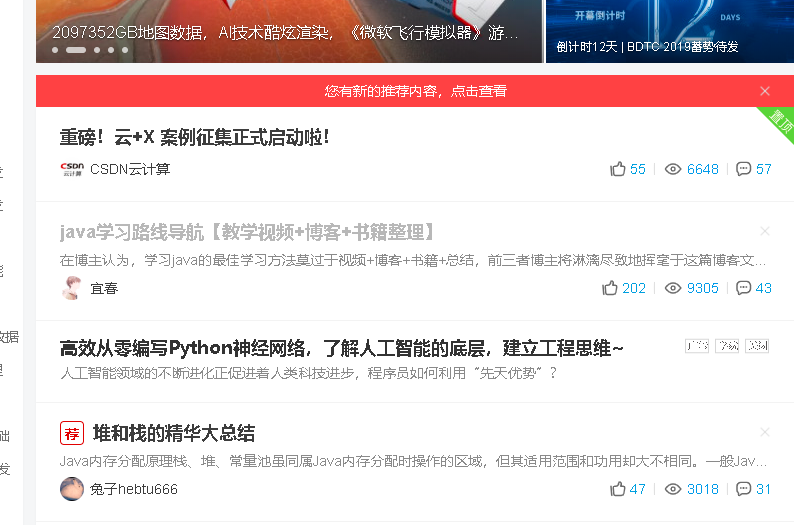
看了源代码,发现如果使用<a href="....来爬取的话,这样得到的会有许多其他的网址,并不全是我需要得博文,但是用<div class="title">去匹配后面的又出现了换行,但是换行匹配我又不会。。。。
re.compile()函数的一个标志参数叫re.DOTALL,它可以让正则表达式中的点(.)匹配包括换行符在内的任意字符。
pat = ' <div class="title">.*?<h2>.*?<a href="(.*?)" target="_blank"' # 此时的.就可以匹配包括换行在内的任意字符
rst1 = re.compile(pat, re.DOTALL).findall(data)

import urllib.request
import re
url = "http://www.csdn.net/"
data = urllib.request.urlopen(url).read().decode("utf-8")
print(len(data))
pat = ' <div class="title">.*?<h2>.*?<a href="(.*?)" target="_blank"'
rst1 = re.compile(pat, re.DOTALL).findall(data)
print(len(rst1))
for i in range(0, len(rst1)):
print(rst1[i])
data = urllib.request.urlopen(rst1[i]).read().decode("utf-8", "ignore")
urllib.request.urlretrieve(rst1[i], "D:\\python\\studyPython\\爬虫学习\\学习urllib\\blog\\"+str(i+1)+".html")
print("爬取第:", i+1, "篇博客成功")
print("首页所有博客爬取结束")
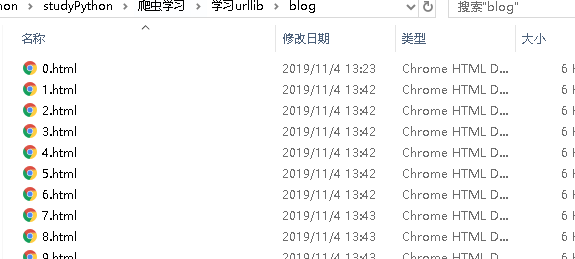
此时则爬取成功
Python爬虫-换行的匹配的更多相关文章
- Python正则表达式-换行的匹配
找到了之前参考的博文,用来记录一下https://www.cnblogs.com/baxianhua/p/8572805.html 平常 点 (.)去匹配任意字符的时候,是不能匹配换行符的 匹配换行: ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- 【Python爬虫】入门知识
爬虫基本知识 这阵子需要用爬虫做点事情,于是系统的学习了一下python爬虫,觉得还挺有意思的,比我想象中的能干更多的事情,这里记录下学习的经历. 网上有关爬虫的资料特别多,写的都挺复杂的,我这里不打 ...
- Python实战:Python爬虫学习教程,获取电影排行榜
Python应用现在如火如荼,应用范围很广.因其效率高开发迅速的优势,快速进入编程语言排行榜前几名.本系列文章致力于可以全面系统的介绍Python语言开发知识和相关知识总结.希望大家能够快速入门并学习 ...
- python爬虫之re正则表达式库
python爬虫之re正则表达式库 正则表达式是用来简洁表达一组字符串的表达式. 编译:将符合正则表达式语法的字符串转换成正则表达式特征 操作符 说明 实例 . 表示任何单个字符 [ ] 字符集,对单 ...
- Python爬虫初学(二)—— 爬百度贴吧
Python爬虫初学(二)-- 爬百度贴吧 昨天初步接触了爬虫,实现了爬取网络段子并逐条阅读等功能,详见Python爬虫初学(一). 今天准备对百度贴吧下手了,嘿嘿.依然是跟着这个博客学习的,这次仿照 ...
- 【转】Python爬虫:抓取新浪新闻数据
案例一 抓取对象: 新浪国内新闻(http://news.sina.com.cn/china/),该列表中的标题名称.时间.链接. 完整代码: from bs4 import BeautifulSou ...
- Python爬虫与数据分析之模块:内置模块、开源模块、自定义模块
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- python爬虫之Beautiful Soup的基本使用
1.简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索 ...
随机推荐
- 搭建Leanote私有云服务器
安装流程 安装Golang 安装Leanote 安装Mongodb 配置Leanote 初始化Mongodb数据 运行Leanote 安装Golang # 下载go1.14.4.linux-amd64 ...
- 【Go语言入门系列】Go语言工作目录介绍及命令工具的使用
[Go语言入门系列]前面的文章: [保姆级教程]手把手教你进行Go语言环境安装及相关VSCode配置 [Go语言入门系列](八)Go语言是不是面向对象语言? [Go语言入门系列](九)写这些就是为了搞 ...
- Springboot集成JUnit5优雅进行单元测试
为什么使用JUnit5 JUnit4被广泛使用,但是许多场景下使用起来语法较为繁琐,JUnit5中支持lambda表达式,语法简单且代码不冗余. JUnit5易扩展,包容性强,可以接入其他的测试引擎. ...
- Brew error: Could not symlink, path is not writable
As explained here by Rick: Start with brew doctor which will show you errors with your brew setup. Y ...
- mysql5.5和5.6的一些区别
timestamp 5.5中 直接写timestamp不加长度 5.6 中 写的timestamp(3) datatime 5.5中 直接写datetime 不加长度 5.6中 可以添加长度(3 ...
- python中的对文件的读写
简单的实例 open函数获取文件,w是写权限,可以对文件进行io操作 file=open('C:/Users/Administrator/Desktop/yes.txt','w') file.writ ...
- 多测师讲解接口测试 _postman(下)_高级讲师肖sir
关联接口 定义:上个接口返回的参数作为下一个接口的入参 1)接口1:查询出所有的州,自治区,直辖市,省(且发送请求不需要入参) 接口url地址: http://www.webxml.com.cn/We ...
- 【树形DP】BZOJ 1131 Sta
题目内容 给出一个\(N\)个点的树,找出一个点来,以这个点为根的树时,所有点的深度之和最大 输入格式 给出一个数字\(N\),代表有\(N\)个点.\(N \le 1000000\).下面\(N-1 ...
- HTML <del> 标签
HTML <del> 标签 什么是<del> 标签? 定义文档中已被删除的文本. 实例 a month is <del>25</del> 30 day ...
- Linux中创建自己的欢迎登陆界面
/etc 在Linux中相当于Windows的注册表 修改其中文件可以影响整个Linux系统 MOTD motd:message of the day /etc/motd /etc/motd文件作用是 ...