Redis 设计与实现 6:五大数据类型之列表
列表对象有 3 种编码:ziplist、linkedlist、quicklist。
ziplist和linkedlist是 3.2 版本之前的编码。quicklist是 3.2 版本新增的编码,ziplist和linkedlist在 3.2 版本及后续版本将不再是列表对象的编码。
编码定义如下(server.h):
#define OBJ_ENCODING_LINKEDLIST 4
#define OBJ_ENCODING_ZIPLIST 5
#define OBJ_ENCODING_QUICKLIST 9
虽然 ziplist 和 linkedlist 不再被列表对象作为编码,但是我们还是有必要了解的。因为 quicklist 也是基于 ziplist 和 linkedlist 改良的。
ziplist
压缩列表 ziplist 在之前的文章 Redis 设计与实现 5:压缩列表 ziplist 有介绍过,结构如下:
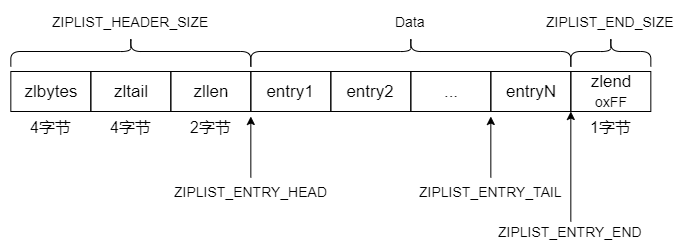
我们使用命令操作列表的元素的时候,实际上就是在操作 entry 的数据。下面我们来举个栗子:
redis> RPUSH list_key 1 "ab" "d"
如果 list_key 用 ziplist 编码,那么结构如下图:

linkedlist
链表 linkedlist 的数据结构如下(adlist.h),跟普通的链表差不多:
typedef struct list {
// 头结点
listNode *head;
// 尾节点
listNode *tail;
// 复制链表节点的值
void *(*dup)(void *ptr);
// 释放链表节点的值
void (*free)(void *ptr);
// 对比链表节点所保存的值跟输入的值是否相等
int (*match)(void *ptr, void *key);
// 链表包含的节点数
unsigned long len;
} list;
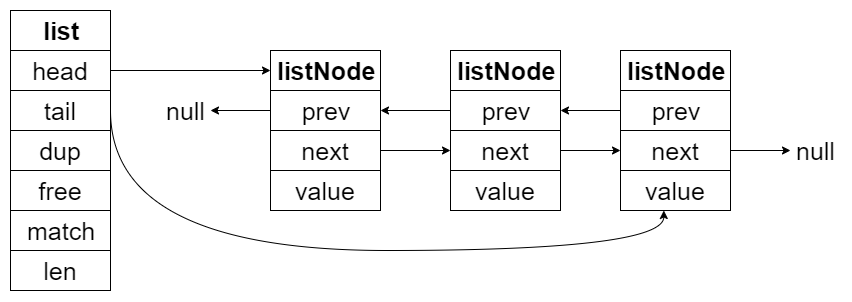
链表节点的结构也很简单:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 当前节点的值
void *value;
} listNode;
结构示意图如下:
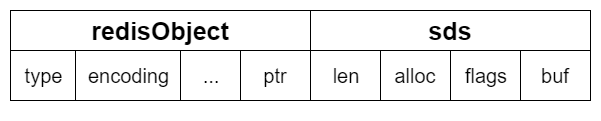
数据将存储在 listNode 的 value 中,数据是一个字符串对象,用 redisObject 包裹着 sds。
例如可能是 embstr 编码的 sds :
下面我们来举个栗子:
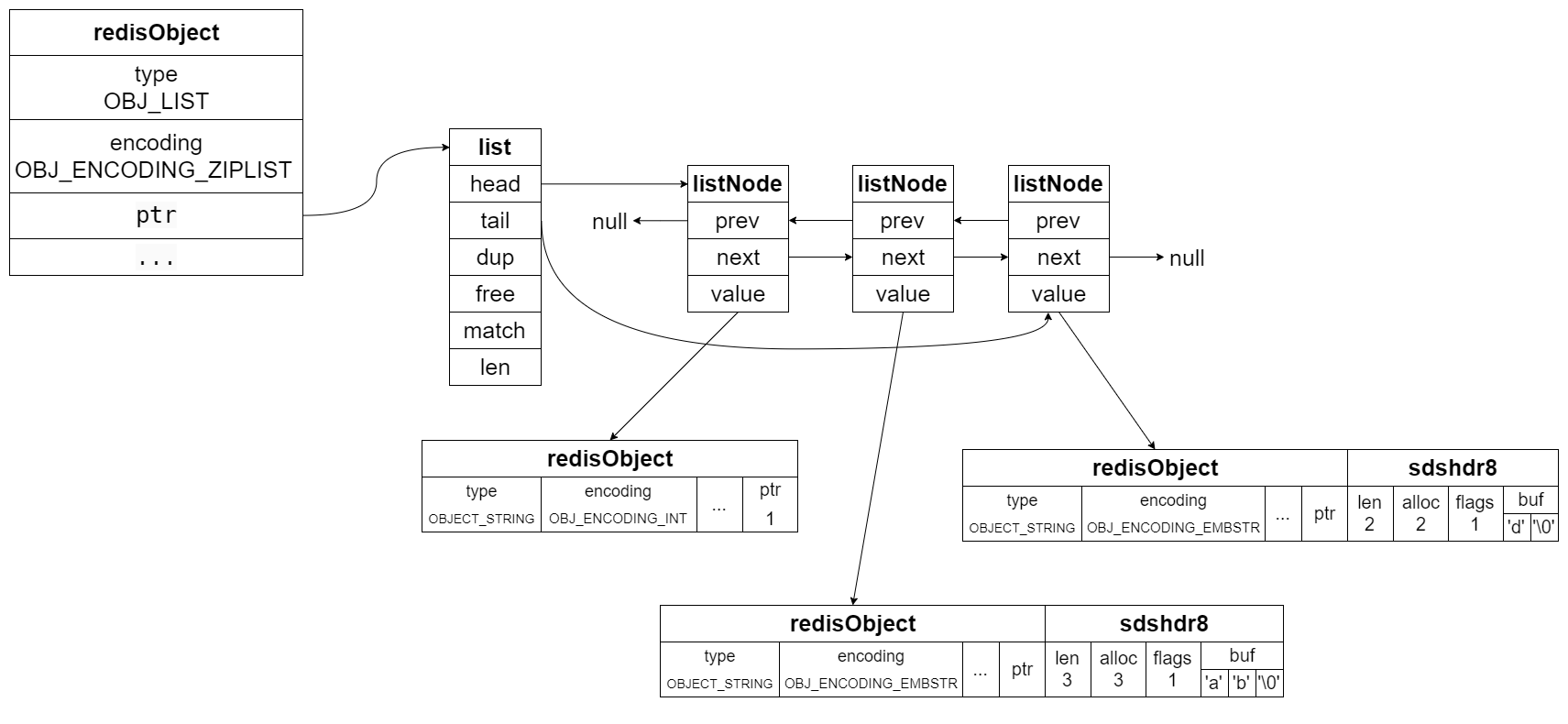
redis> RPUSH list_key 1 "ab" "d"
假如 list_key 的编码是 linkedlist,那么结构如下图:
quicklist
快速列表 quicklist 是 3.2 版本新添加的编码类型,结合了 ziplist 和 linkedlist 的一种编码。
同时在 3.2 版本中,列表也废弃了 ziplist 和 linkedlist。
通过上面的介绍,我们可以看出。双向链表的内存开销很大,每个节点的地址不连续,容易产生内存碎片,quicklist 利用 ziplist减少节点数量,但 ziplist 插入和删除数都很麻烦,复杂度高,为避免长度较长的 ziplist修改时带来的内存拷贝开销,通过配置项配置合理的 ziplist长度。
quicklist 的结构如下:

从上图可以看出,quicklist 跟 linkedlist 最大的不同就是,quicklist 的值指向的是 ziplist!ziplist 可比之前的 redisObject 节省了非常多的内存!
从另一个角度看,他就是把一个长的 ziplist 切割成多个小的 ziplist。
代码实现在 quicklist.h:
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
// 所有 ziplist 中所有的节点数
unsigned long count;
// quicklistNode 的数量
unsigned long len;
// 限定 ziplist 的最大大小,可通过配置文件配置
int fill : QL_FILL_BITS;
// 压缩程度,0 表示不压缩,可通过配置文件配置
unsigned int compress : QL_COMP_BITS;
// ...
} quicklist;
配置一:fill (控制 ziplist 大小)
太长的 ziplist 增删的复杂度高,所以 quicklist 用 fill 参数来控制 ziplist 的大小,它是通过配置文件的list-max-ziplist-size配置。
- 当数字为正数,表示:每个节点的
ziplist最多包含的entry个数。 - 当数字为负数:
- -1:每个节点的
ziplist字节大小不能超过4kb - -2:每个节点的
ziplist字节大小不能超过8kb (redis默认值) - -3:每个节点的
ziplist字节大小不能超过16kb - -4:每个节点的
ziplist字节大小不能超过32kb - -5:每个节点的
ziplist字节大小不能超过64kb
- -1:每个节点的
配置二:compress (控制压缩程度)
因为链表的特性,一般首尾两端操作较频繁,中部操作相对较少,所以 redis 提供压缩深度配置:list-compress-depth,也就是属性 compress 。
- 0:表示都不压缩。这是Redis的默认值。
- 1:表示
quicklist两端各有1个节点不压缩,中间的节点压缩。 - 2:表示
quicklist两端各有2个节点不压缩,中间的节点压缩。 - 3:表示
quicklist两端各有3个节点不压缩,中间的节点压缩。
quicklist 节点
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
// 不设置压缩数据参数 recompress 时指向一个 ziplist 结构
// 设置压缩数据参数recompress 时指向 quicklistLZF 结构
unsigned char *zl;
// ziplist 的字节数
unsigned int sz;
// ziplist 中包含的节点数量
unsigned int count : 16;
// 编码。1 表示压缩过,2 表示没压缩
unsigned int encoding : 2;
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
// 标记 quicklist 节点的 ziplist 之前是否被解压缩过
// 如果recompress 为 1,则等待被再次压缩
unsigned int recompress : 1;
// ...
} quicklistNode;
压缩过的 ziplist 结构
typedef struct quicklistLZF {
// 表示被 LZF 算法压缩后的 ziplist 的大小
unsigned int sz;
// 压缩后的 ziplist 的数组,柔性数组
char compressed[];
} quicklistLZF;
quick 的常用操作
1. 插入
(1) quicklist 可以在头部或者尾部插入数据:quicklist.c/quicklistPushHead、quicklist.c/quicklistPushTail,我们就挑一个从头部插入的代码来看看吧(插入尾部的代码也是差不多的)(代码格式略微调整了一下):
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
// 判断头结点上的 ziplist 大小是否没超过限制
if (likely(_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
// 没超过限制,就插入到 ziplist 中。ziplistPush 是 ziplist.c 的方法
quicklist->head->zl = ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
// ziplist 超过大小限制,则创新创建一个新的 quicklistNode
quicklistNode *node = quicklistCreateNode();
// 再创建新的 ziplist,然后把 ziplist 放到节点中
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
// 新的 quicklistNode 插入原来的头结点上,成为新的头结点
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
(2) quicklist 也可以从任意指定的位置插入:quicklist.c/_quicklistInsert,实现相对来说比较复杂,我们就用文字说明(代码太长,感兴趣的读者自己去读吧):
- 当前节点是
NULL:创建一个新的节点,插入就好。 - 当前节点的
ziplist大小没有超过限制时:直接插入到ziplist就好。 - 当前节点的
ziplist大小超过限制时:- 如果插入的位置是
ziplist的两端:- 如果相邻的节点的
ziplist大小没有超过限制,那么就插入到相邻节点的ziplist中。 - 如果相邻的节点的
ziplist大小也超过限制,这时需要创建一个新的节点插入。
- 如果相邻的节点的
- 如果插入的位置是
ziplist的中间:
则需要把当前ziplist从插入位置 分裂 (_quicklistSplitNode) 为两个节点,然后把数据插入第二个节点上。
- 如果插入的位置是
2. 查找
quicklist 支持通过 index 查找元素:quicklist.c/quicklistIndex。
查找的本质就是遍历,先查看quicklistNode 的长度判断 index 是否在这个节点中,如果不是则跳到下个节点。
当定位到节点之后,对节点里面的 ziplist 进行遍历查找 (ziplistIndex)。
3 删除
(1) 指定值的删除,quicklist.c/quicklistDelEntry
这个指定的值的信息 quicklistEntry 的结构如下:
typedef struct quicklistEntry {
// 指向当前 quicklist 的指针
const quicklist *quicklist;
// 指向当前 quicklistNode 节点的指针
quicklistNode *node;
// 指向当前 ziplist 的指针
unsigned char *zi;
// 指向当前 ziplist 的字符串 vlaue 成员
unsigned char *value;
// 当前 ziplist 的整数 value 成员
long long longval;
// 当前 ziplist 的字节数大小
unsigned int sz;
// 在 ziplist 的偏移量
int offset;
} quicklistEntry;
具体的删除代码如下(做了一些删减):
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry) {
quicklistNode *prev = entry->node->prev;
quicklistNode *next = entry->node->next;
// 通过 quicklistEntry 可以定位到 ziplist 中的元素位置,然后进行删除
// quicklist -> quicklistNode -> ziplist -> ziplistEntry
int deleted_node = quicklistDelIndex((quicklist *)entry->quicklist, entry->node, &entry->zi);
// 下面是迭代器的参数调整,此处忽略...
}
(2) 区间元素 index 删除: quicklist.c/quicklistDelRange(代码太长了,就不晾出来了)
先通过遍历找元素,会判断是否可以删除整个节点 entry.offset == 0 && extent >= node->count,可以的话不用遍历里面的ziplist直接删除整个节点。
否则计算出当前节点ziplist 要删除的范围,通过 ziplistDeleteRange 函数删除。
重点回顾
- 列表对象有 3 种编码:
ziplist、linkedlist、quicklist。 quicklist是3.2后新增的用于替代ziplist和linkedlist的编码。ziplist节省内存,但是太长的话性能低下。linkedlist占用内存太多。quicklist可以看成由多个ziplist组成的linkedlist,性能高,节省内存。
Redis 设计与实现 6:五大数据类型之列表的更多相关文章
- redis学习(七)——五大数据类型总结:字符串、散列、列表、集合和有序集合
目录 字符串类型(String) 散列类型(Hash) 列表类型(List) 集合类型(Set) 有序集合类型(SortedSet) 其它命令 一.字符串类型(String) 1.介绍: 字符串类型是 ...
- Redis 设计与实现 6:五大数据类型之字符串
前文 Redis 设计与实现 2:Redis 对象 说到,五大数据类型都会封装成 RedisObject. typedef struct redisObject { unsigned type:4; ...
- Redis详解(五)------ redis的五大数据类型实现原理
前面两篇博客,第一篇介绍了五大数据类型的基本用法,第二篇介绍了Redis底层的六种数据结构.在Redis中,并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这些对 ...
- Redis 详解 (五) redis的五大数据类型实现原理
目录 1.对象的类型与编码 ①.type属性 ②.encoding 属性和 *prt 指针 2.字符串对象 3.列表对象 4.哈希对象 5.集合对象 6.有序集合对象 7.五大数据类型的应用场景 8. ...
- redis的五大数据类型实现原理
1.对象的类型与编码 Redis使用前面说的五大数据类型来表示键和值,每次在Redis数据库中创建一个键值对时,至少会创建两个对象,一个是键对象,一个是值对象,而Redis中的每个对象都是由 redi ...
- Redis 设计与实现 8:五大数据类型之哈希
哈希对象的编码有两种:ziplist.hashtable. 编码一:ziplist ziplist 已经是我们的老朋友了,它一出现,那肯定就是为了节省内存啦.那么哈希对象是怎么用 ziplist 存储 ...
- Redis 设计与实现 9:五大数据类型之集合
集合对象的编码有两种:intset 和 hashtable 编码一:intset intset 的结构 整数集合 intset 是集合底层的实现之一,从名字就可以看出,这是专门为整数提供的集合类型. ...
- Redis 设计与实现 10:五大数据类型之有序集合
有序集合 sorted set (下面我们叫zset 吧) 有两种编码方式:压缩列表 ziplist 和跳表 skiplist. 编码一:ziplist zset 在 ziplist 中,成员(mem ...
- Redis数据库 01概述| 五大数据类型
1.NoSQL数据库简介 解决应用服务器的CPU和内存压力:解决数据库服务的IO压力: ----->>> ① session存在缓存数据库(完全在内存里),速度快且数据结构简单: 打 ...
随机推荐
- 【NOIP2017提高A组模拟9.7】JZOJ 计数题
[NOIP2017提高A组模拟9.7]JZOJ 计数题 题目 Description Input Output Sample Input 5 2 2 3 4 5 Sample Output 8 6 D ...
- Python中sorted(iterable, /, *, key=None, reverse=False)的参数中的斜杆是什么意思?
通过help(sorted)查看sorted的帮助文档,显示如下: Help on built-in function sorted in module builtins: sorted(iterab ...
- PyQt(Python+Qt)学习随笔:QTableWidget设置项的setItem方法
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QTableWidget表格部件中setItem用于在表格部件QTableWidget创建后,设定指 ...
- PyQt(Python+Qt)学习随笔:QTableView中数据行高和列宽的调整方法
老猿Python博文目录 老猿Python博客地址 一.概述 在QTableView中,除了采取缺省的间隔显示行和列的数据外,还可以通过带调整数据的行高和列宽. 二.列宽调整方法 调整数据行列宽的方法 ...
- secret_key伪造session来进行越权
从swpuctf里面的一道ctf题目来讲解secret_key伪造session来进行越权. 以前没有遇到过这种题目,这次遇到了之后查了一些资料把它做了出来,记录一下知识点. 参考资料 http:// ...
- Java基础学习之基础概念与环境搭建(1)
1.Java基础概念 1.1.Java语言的特点 Java语言是简单易学的 Java语言是面向对象(封装.继承和多态) Java语言是平台无关的(一次编译,到处运行) Java语言是可靠的.安全的(异 ...
- this作为构造函数时注意点
在 JS 中,为了实现类,我们需要定义一些构造函数,在调用一个构造函数的时候加上 new 这个关键字: function Person(name) { this.name = name; consol ...
- POI2009 KON-Ticket Inspector
题目链接 Description 一辆火车依次经过 \(n\) 个车站,顺序是 \(1, 2, 3, ..., n - 1, n\).给定 \(A_{i, j}\) 表示从 \(i\) 站上车,\(j ...
- git使用-merge request开发操作步骤
0. 如果当前不在develop分支,则切换到develop分支 git checkout develop 1. 获取develop分支最新代码 git pull 注意:这一步正常来说应该是一个Fas ...
- Angular学习知识点记录
问:版本直接跳转到Angular4? 答:为了遵循严格的版本策略.在angular2.x的时候,angular route的版本已经是版本3了.因此为了版本统一,angular直接从2跳到了4,.参考 ...