Flash----一种VirtualActor模式的分布式有状态系统原型
首先, 这个Flash不是我们在浏览器用的Flash这种技术, 而是:

动作缓慢, 车速极快------闪电(Flash).
18年的某一个周末, 即兴用Python写了一个Virtual Actor模式的demo, 起了一个名字叫Flash, 是因为速度快如闪电------做framework快, 通过framework写逻辑快.
所以大言不惭, 叫Flash, https://github.com/egmkang/flash. 第一个版本是asyncio写的, 但是编写的过程中发现一旦少写一点东西(async/await), bug会很难找. 这一点和C#是不太一样的, 所以第一个版本可以跑之后, 花了一点时间把asyncio的代码换成了gevent.
这边主要来说说当时的想法, 以后未来如果要做类似的东西, 该如何选择. (README里面的东西可能和实现没多少关系......懒, 所以也不打算更改README, 错了就错了)
当时为了实现一个去中心化, 可以横向扩容, 可以故障迁移的有状态framework. (很显然我对无状态的东西一点兴趣都没有:-D)
所有有几个关键点, 这边简单介绍一下(因为代码不一定能跑起来, 但是思想可以):
1) RPC
这边没有使用第三方RPC库, 而是选择自己实现看了一个. 在Python这种语言里面, 实现一个RPC还是比较简单的, 所需要的例如future/promise, 序列化库, 协程, 还是就是Python是动态语言, 所以造一个Proxy对象比较简单(C#里面是DispatchProxy).
future/promise选择了gevent.event.AsyncResult.
序列化库选择了pickle, 序列化这边做法实际上是有一点问题的, 第一个就是pickle效率较低, 数据比较大; 第二个就是RpcRequest/RpcResponse协议的设计不对, 因为Python的args是没有经过序列化直接塞到RpcRequest里面的, 所以没看出来有啥问题, 但是如果是其他语言这样就行不通了. 所以比较科学的做法还是brpc那种, 包分成三部分: 包头, meta, data. 其中meta用来形容data数据和请求的元数据, 这样的话, args数据就不会被encode两次. python里面可以这么搞不代表其他语言也可以这么搞.
Proxy对象的话, 是自己造的. 在rpc_proxy.py里面, 通过重写__call__元方法, 实现比较复杂的功能. C#的DispatchProxy也能实现这种功能, 而且功能更强大, 类型还是安全的, Python里面做不到类型安全. 不支持动态代码生成的语言做这个都不太好做, 例如golang/c++等.
哦, 还有就是网络库里面一定要注意send和sendall这两种东西的区别, 对于用户来讲sendall代码容易编写, 但是用send实现就需要注意一下返回值, 否则可能发了一半数据, 然后对面收到的流是断的.
2) 服务发现
元数据存在etcd里面.
每个进程拉起来的时候, 通过uuid生成一个唯一的id, 当做ServerID, 然后组成一个MachineInfo, 然后就开启了一个update_machine_member_info的死循环, 去etcd里面不停的去更新自己的信息(有一个5s的CD).
然后再开启一个get_members_info死循环去不停的刀etcd里面pull最新的membership信息, 然后再保存到内存中.
这样在MemberShipManager里面就可以不停的add_machine, remove_machine.
这样做的话, 只需要经过几个TTL, 集群的所有节点就能感知到成员的变更; 成员和etcd失联, 那么就应该自己退出(Flash里面没做).
3) 对象的定位
上面说了, 集群内的节点对其他节点的感知实际上是靠定时pull etcd信息来获得的, 那么新加入的节点, 就不能立马提供服务, 否则集群元数据是不一致的. 例如5s间隔去pull, 那么3个interval之后, 其他节点大概率是能感知到节点的变更. 所以等一段时间再路由新的请求到新增服务器, 可以做到更好的一致性.
然后, MachineInfo内有服务器的负载信息, 那么:
0> 先到进程内缓存区寻找对象的位置, 看看最近是否有人请求过, 如果目标服务器健康(保持心跳), 那么直接返回
1> 先去到etcd里面查询对象的位置是否存在, 如果存在, 并且machine健康, 那么直接返回(并缓存)
2> 对对象上分布式锁(通过etcd), 然后再做步骤1>, 还未找到对象的位置, 那么获取到可以提供相应服务的machine列表, 通过负载权重, 随机出来一个新的服务器, 然后保存etcd, 保存进程缓存, 返回
很明显, 对象的定位是通过客户端侧+带权重的Random来做的. 这只是一种选择, 完成一个功能有很多选择.
4) 故障迁移
对象的定位有一个检测目标服务器是否健康的过程, 实际上就是目标服务器是否最近向etcd更新过自己的心跳, 如果更新过那么认为健康, 否则就是不健康.
那么, 当目标服务器不健康的时候, 就会触发对象的再定位, 从而实现故障的迁移.
5) 可重入性
互联网的服务不存在这个问题, 是因为互联网的无状态服务, 不存在排队等候处理请求的过程.
但是在有状态服务里面, 往往会对同一个用户(或者其他单位)的请求进行排队. 那么试想一下, 排队处理A的请求, A又调用了B, B又调用了A. A的请求没有返回之前是不能处理其他的请求的, 所以这时候就死锁了. 所以有状态的Actor服务必须要处理这种情况.
这时候需要引入一点点代码, 来看看RpcRequest的数据结构, 里面吗包含了一个request_id, 但是在request_id之前有一个host. 实际上就是这俩数据, 决定了rpc请求的可重入性.
class RpcRequest:
def __init__(self):
self.clear() def clear(self):
self.host = ""
if _global_id_generator is not None:
self.request_id = _global_id_generator.NextId()
else:
self.request_id = 0
self.entity_type = 0
self.entity_id = 0
self.method = ""
self.args = ()
self.kwargs = dict()
思考一下, Actor请求的一个请求是谁发出的? 肯定是外界系统产生的第一个请求, 那么这个请求没有完成之前, 是不能处理其他请求的. 而中间的请求实际上都不是源头. 所以我们只需要在源头上面标记唯一ID, 中间传染的路径上面都用源头的唯一ID, 所以系统里面有一个ActorContext的概念, 就是在保存这个信息. Dispatch的过程也就变得比较简单:
if entity.context().running is False:
gevent.spawn(lambda: _dispatch_entity_method_loop(entity)) if entity.context().host == request.host and entity.context().request_id <= request.request_id:
gevent.spawn(lambda: _dispatch_entity_method_anyway(entity, conn, request, response, method))
return
entity.context().send_message((conn, request, response, method))
如果对象的loop不在运行就拉起来, 如果现在正在处理的请求和当前需要被Dispatch的请求源自一个请求, 那么直接开启一个协程去处理, 否则就塞进MailBox等候处理.
从而实现了可重入性.
Flash, 麻雀虽小五脏俱全, 实现不是很精良, 但是作为一个原型, 其目的已经达到. 可以对其实现进行反思, 组合出来更合理的分布式有状态服务系统.
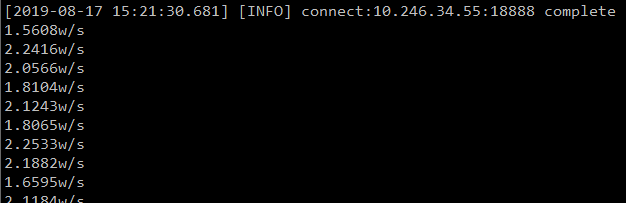
世人都说Python的性能差, 但是这个原型系统一秒可以跨进程进行1.5~2.2Wqps, 已经非常优秀了. 有没有算过自己的系统到底要承载多少请求, Python真的就是系统的瓶颈?
参考:
0) Flash (https://github.com/egmkang/flash)
1)Orleans (https://dotnet.github.io/orleans/)
2) gevent (http://www.gevent.org/)
Flash----一种VirtualActor模式的分布式有状态系统原型的更多相关文章
- Hadoop三种安装模式:单机模式,伪分布式,真正分布式
Hadoop三种安装模式:单机模式,伪分布式,真正分布式 一 单机模式standalone单 机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守 ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- js架构设计模式——你对MVC、MVP、MVVM 三种组合模式分别有什么样的理解?
你对MVC.MVP.MVVM 三种组合模式分别有什么样的理解? MVC(Model-View-Controller)MVP(Model-View-Presenter)MVVM(Model-View-V ...
- 一步一步学FRDM-KE02Z(一):IAR调试平台搭建以及OpenSDA两种工作模式设置
摘要:FRDM-KE02Z是飞思卡尔公司较为新的微控制器,学习和开发资料较少.从本篇开始会陆续介绍其相关的开发流程,并完成一个小型的工程项目.这是本系列博客的第一篇,主要介绍开发环境IAR for A ...
- Spark on YARN两种运行模式介绍
本文出自:Spark on YARN两种运行模式介绍http://www.aboutyun.com/thread-12294-1-1.html(出处: about云开发) 问题导读 1.Spark ...
- SPI总线的4种工作模式
spi总线的4种工作模式 0 to 4 modes SPI接口的全称是"Serial Peripheral Interface",意为串行外围接口,是Motorola首先在其MC6 ...
- 设计模式--状态模式(分布式中间件熔断器Java实现)
最近在做分布式服务熔断,因为要实现一个熔断器状态机,所以想到状态模式.状态模式是当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类.状态模式主要解决的是当控制一个对象状态的条件表达 ...
- 高通方案的Android设备几种开机模式的进入与退出
高通方案的Android设备主要有以下几种开机模式,Android.EDL.Fastboot.Recovery和FFBM,其进入及退出的方式如下表. 开机模式 屏幕显示 冷启动 热启动 按键退出 命令 ...
- 再谈STM32的CAN过滤器-bxCAN的过滤器的4种工作模式以及使用方法总结
1. 前言 bxCAN是STM32系列最稳定的IP核之一,无论有哪个新型号出来,这个IP核基本未变,可见这个IP核的设计是相当成熟的.本文所讲述的内容属于这个IP核的一部分,掌握了本文所讲内容,就可以 ...
随机推荐
- CodeForces 916D Jamie and To-do List
题意 你需要维护一个任务列表,有 \(q\) 次操作,每次操作形如以下四种: set a x:设置任务 \(a\) 的优先级为 \(x\),如果任务列表中没有 \(a\) 则加进来. remove a ...
- 简单谈谈Hilt——依赖注入框架
今天继续Jetpack专题,相信不少的朋友都使用过Dagger,也放弃过Dagger,因为实在太难用了.所以官方也是为了让我们更好使用依赖注入框架,为我们封装了一个新的框架--Hilt,今天一起来看看 ...
- 自动化测试之Selenium篇(一):环境搭建
当前无论找工作或者是实际项目应用,自动化测试扮演着非常重要的角色,今天我们来学习下Selenium的环境搭建 Selenium简述 Selenium是一个强大的开源Web功能测试工具系列 可进行读入测 ...
- 3.5 MyLinkedList 实现
3.5 MyLinkedList 类的实现 MyLinkedList 将用双链表实现,并且还需要保留该表两端的引用.这将需要三个类 MyLinkedList 类,包含到两端的链.表的大小以及一些方法. ...
- pip升级失败
python -m pip install --upgrade pip失败 解决办法: easy_install pip
- leetcode132:4sum
题目描述 给出一个有n个元素的数组S,S中是否有元素a,b,c和d满足a+b+c+d=目标值?找出数组S中所有满足条件的四元组. 注意: 四元组(a.b.c.d)中的元素必须按非降序排列.(即a≤b≤ ...
- 自己常用的Content-Type几种值用法
Content-Type 的值类型: application/json:消息主体是序列化后的 JSON 字符串 这里要注意的是 我在使用webapi,前台使用$.ajax的时候 假如我要传递的数据为 ...
- 内网渗透 day10-msfvenom免杀
免杀2-msf免杀 目录 1. 生成shellcode 2. 生成python脚本 3. 自编码免杀 4. 自捆绑免杀(模版注入) 5. 自编码+自捆绑免杀 6. msf多重免杀 7. evasion ...
- tcp输入数据 慢速路径处理 tcp_data_queue_ofo
tcp_data_queue_ofo 在新内核的实现中ofo队列实际上是一颗红黑树.在tcp_data_queue_ofo中根据序号,查找到合适位置,合并或者添加到rbtree中.同时设置dsack和 ...
- setPriority()优先级
1 . 优先级表示重要程度或者紧急程度.但是能不能抢到资源也是不一定.2 . 分配优先级:反映线程的重要或紧急程度线程的优先级用1-10 表示,1的优先级最低,10的优先级最高,默认值是5 packa ...