SpringBoot中JPA的学习
SpringBoot中JPA的学习
准备环境和项目配置
写一下学习JPA的过程,主要是结合之前SpringBoot + Vue的项目和网上的博客学习一下。
首先,需要配置一下maven文件,有这么两个依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>6.0.6</version>
</dependency>
然后是application中的配置问题,JPA有这么一些常见的参数:
spring.jpa.show-sql 配置在日志中打印出执行的 SQL 语句信息。
spring.jpa.hibernate.ddl-auto配置了实体类维护数据库表结构的具体行为,update表示当实体类的属性发生变化时,表结构跟着更新,也可以取值create,create表示启动的时候删除上一次生成的表,并根据实体类重新生成表,这个时候之前表中的数据就会被清空;还可以取值create-drop,这个表示启动时根据实体类生成表,但是当sessionFactory关闭的时候表会被删除;validate表示启动时验证实体类和数据表是否一致;none则什么都不做。
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect 。在 SrpingBoot 2.0 版本中,Hibernate 创建数据表的时候,默认的数据库存储引擎选择的是 MyISAM (之前好像是 InnoDB,这点比较诡异)。这个参数是在建表的时候,将默认的存储引擎切换为 InnoDB 用的。
spring.jackson.serialization.indent_output=true表示格式化输出的json字符串,方便查看。
定义数据实体类
在这个项目里,数据实体类的定义方式大同小异:
import com.fasterxml.jackson.annotation.JsonIgnoreProperties; import javax.persistence.*; @Entity
@Table(name = "book")
@JsonIgnoreProperties({"handler","hibernateLazyInitializer"})
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
int id; //把 category 对象的 id 属性作为 cid 进行了查询
@ManyToOne
@JoinColumn(name="cid")
private Category category; String cover;
String title;
String author;
String date;
String press;
String abs; public Category getCategory() {
return category;
} public void setCategory(Category category) {
this.category = category;
} public String getDate() {
return date;
} public void setDate(String date) {
this.date = date;
} ...
}
下面分别写一下这些注释的作用以及和其他部分关联:
@Entity 是一个必选的注解,声明这个类对应了一个数据库表。
@Table(name = "book") 是一个可选的注解。声明了数据库实体对应的表信息。包括表名称、索引信息等。这里声明这个实体类对应的表名是 book。如果没有指定,则表名和实体的名称保持一致。
可以看一下对应的在MySQL中的数据表:
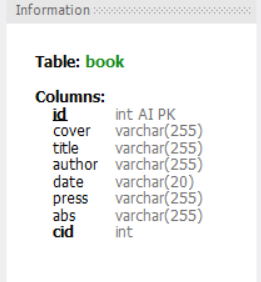
其中8个属性分别表示序号、封面(存放图床的url或者本地的url地址)、标题、作者、出版日期、出版社、简介、表示类别的外键。
@JsonIgnoreProperties因为是做前后端分离,而前后端数据交互用的是 json 格式。那么对象就会被转换为 json 数据。而本项目使用 jpa 来做实体类的持久化,jpa 默认会使用 hibernate,在 jpa 工作过程中,就会创造代理类来继承该类 ,并添加 handler 和 hibernateLazyInitializer 这两个无须 json 化的属性,所以这里需要用 JsonIgnoreProperties 把这两个属性忽略掉。这里我看好多博主都没有写,在后面会对这个注解多做一些测试相关的内容。
@Id表示该字段是一个id
@GeneratedValue注解存在的意义主要就是为一个实体生成一个唯一标识的主键、@GeneratedValue提供了主键的生成策略。@GeneratedValue注解有两个属性,分别是strategy和generator。generator属性的值是一个字符串,默认为"",其声明了主键生成器的名称。strategy属性提供四种值:1.AUTO主键由程序控制, 是默认选项 ,不设置就是这个;2.IDENTITY 主键由数据库生成, 采用数据库自增长, Oracle不支持这种方;3.SEQUENCE 通过数据库的序列产生主键, MYSQL不支持;4.Table提供特定的数据库产生主键, 该方式更有利于数据库的移植。需要注意的是很多博主将MySQL建表时设置自增属性,这里采用默认值表示自增。但是想运用到neo4j上可能要注意。
@Column(length = 32) 用来声明实体属性的表字段的定义。默认的实体每个属性都对应了表的一个字段。字段的名称默认和属性名称保持一致(并不一定相等)。字段的类型根据实体属性类型自动推断。这里主要是声明了字符字段的长度。如果不这么声明,则系统会采用 255 作为该字段的长度。这里的话个人感觉原来博主的定义不够严谨,应该是:
@Column(length = 20)
String date;
@JoinColumn 注解的作用:用来指定与所操作实体或实体集合相关联的数据库表中的列字段。由于 @OneToOne(一对一)、@OneToMany(一对多)、@ManyToOne(多对一)、@ManyToMany(多对多) 等注解只能确定实体之间几对几的关联关系,它们并不能指定与实体相对应的数据库表中的关联字段,因此,需要与 @JoinColumn 注解来配合使用。我们也可以不写@JoinColumn,Hibernate会自动生成一张中间表来进行绑定,通常并不推荐让Hibernate自动去自动生成中间表,而是使用@JoinTable注解来指定中间表:
然后就是各个属性的get和set方法,注意下属性前面一般要加上private限制,但是这个博主没有加,不太规范这里。
实现持久层服务
public interface BookDAO extends JpaRepository<Book,Integer> {
List<Book> findAllByCategory(Category category);
/*
这个 findAllByTitleLikeOrAuthorLike,翻译过来就是“根据标题或作者进行模糊查询”,
参数是两个 String,分别对应标题或作者。
记住这个写法,我想当然的以为是 findAllByTitleOrAuthorLike,只设置一个参数就行,结果瞎折腾了好久。
因为 DAO 里是两个参数,所以在 Service 里把同一个参数写了两遍。
用户在搜索时无论输入的是作者还是书名,都会对两个字段进行匹配。
*/
List<Book> findAllByTitleLikeOrAuthorLike(String keyword1, String keyword2);
}
JpaRepository,默认支持简单的 CRUD 操作,非常方便。 <S extends T> S save(S entity); <S extends T> Iterable<S> saveAll(Iterable<S> entities);( Optional<T> findById(ID id); boolean existsById(ID id); Iterable<T> findAll(); Iterable<T> findAllById(Iterable<ID> ids); long count(); void deleteById(ID id); void delete(T entity); void deleteAll(Iterable<? extends T> entities); void deleteAll();
关于这里JpaRepository的原理,可以参考这篇博客的内容:
https://segmentfault.com/a/1190000015047290
这里写一下自定义JPA对应的函数名:
| Keyword | Sample | JPQL snippet |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection<age> ages)</age> | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection<age> age)</age> | … where x.age not in ?1 |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
SpringBoot中JPA的学习的更多相关文章
- SpringBoot 中 JPA 的使用
详细连接 简书https://www.jianshu.com/p/c14640b63653 新建项目,增加依赖 在 Intellij IDEA 里面新建一个空的 SpringBoot 项目.具体步骤参 ...
- springboot中JPA的应用
1.JPA JPA(Java Persistence API)是Sun官方提出的Java持久化规范.它为Java开发人员提供了一种对象/关联映射工具来管理Java应用中的关系数据.他的出现主要是为了简 ...
- SpringBoot中JPA使用动态SQL查询
https://www.jianshu.com/p/f72d82e90948 可以重点关注方法二,把原生sql传入数据库去查询 好处是:更加灵活坏处是:拼接sql比较痛苦,也容易出问题,比如拼接的sq ...
- SpringBoot中JPA,返回List排序
这里简单示例,利用query,根据“createtime”字段,进行 desc 排序,最近日期的数据在最前面. public List<StatusEvent> findAll(Speci ...
- Dubbo源码学习--优雅停机原理及在SpringBoot中遇到的问题
Dubbo源码学习--优雅停机原理及在SpringBoot中遇到的问题 相关文章: Dubbo源码学习文章目录 前言 主要是前一阵子换了工作,第一个任务就是解决目前团队在 Dubbo 停机时产生的问题 ...
- SpringBoot中使用Spring Data Jpa 实现简单的动态查询的两种方法
软件152 尹以操 首先谢谢大佬的简书文章:http://www.jianshu.com/p/45ad65690e33# 这篇文章中讲的是spring中使用spring data jpa,使用了xml ...
- SpringBoot学习笔记(9)----SpringBoot中使用关系型数据库以及事务处理
在实际的运用开发中,跟数据库之间的交互是必不可少的,SpringBoot也提供了两种跟数据库交互的方式. 1. 使用JdbcTemplate 在SpringBoot中提供了JdbcTemplate模板 ...
- Spring Data JPA系列2:SpringBoot集成JPA详细教程,快速在项目中熟练使用JPA
大家好,又见面了. 这是Spring Data JPA系列的第2篇,在上一篇<Spring Data JPA系列1:JDBC.ORM.JPA.Spring Data JPA,傻傻分不清楚?给你个 ...
- 由浅入深学习springboot中使用redis
很多时候,我们会在springboot中配置redis,但是就那么几个配置就配好了,没办法知道为什么,这里就详细的讲解一下 这里假设已经成功创建了一个springboot项目. redis连接工厂类 ...
随机推荐
- Java学习的第三十八天
例3.4. package bgio; public class cjava { public static void main(String[]args) { int i=1; int sum=0; ...
- git同步源码到gitee和github
如何把我们的源码同步到gitee或github远程仓库中 同步方式分以下几种: 1.命令同步 先查看下我们是否有远程仓库:git remote -v 如有就要删除远程仓库或是同命令覆盖,如全新安 ...
- Maven的介绍及使用
一.Maven简介 Maven 是一个项目管理工具,可以对 Java 项目进行构建.依赖管理,是一个自动化构建工具. 自动化构建工具:将原材料(java.js.css.html....)->产品 ...
- MySQL中load data infile将文件中的数据批量导入数据库
有时候我们需要将文件中的数据直接导入到数据库中,那么我们就可以使用load data infile,下面具体介绍使用方法. dao中的方法 @Autowired private JdbcTemplat ...
- 使用 c++ 模板显示实例化解决模板函数声明与实现分离的问题
问题背景 开始正文之前,做一些背景铺垫,方便读者了解我的工程需求.我的项目是一个客户端消息分发中心,在连接上消息后台后,后台会不定时的给我推送一些消息,我再将它们转发给本机的其它桌面产品去做显示.后台 ...
- JavaScript的原型对象prototype、原型属性__proto__、原型链和constructor
先画上一个关系图: 1. 什么是prototype.__proto__.constructor? var arr = new Array; 1. __proto__是原型属性,对象特有的属性,是对象指 ...
- 经典c程序100例==21--30
[程序21] 题目:猴子吃桃问题:猴子第一天摘下若干个桃子,当即吃了一半,还不瘾,又多吃了一个 第二天早上又将剩下的桃子吃掉一半,又多吃了一个.以后每天早上都吃了前一天剩下 的一半零一个.到第10天早 ...
- MyBatis 中 @Param 注解的四种使用场景
https://juejin.im/post/6844903894997270536 第一种:方法有多个参数,需要 @Param 注解 第二种:方法参数要取别名,需要 @Param 注解 第三种:XM ...
- JS变量、作用域和内存问题
一.基本类型和引用类型 1. 基本类型值指的是简单的数据段,引用类型值指那些可能由多个值组成的对象. 2. 基本类型值按值访问,引用类型值按引用访问: 按值访问对于基本类型而言,不同变量指向的地址空间 ...
- Spring源码之注解的原理
https://blog.csdn.net/qq_28802119/article/details/83573950 https://www.zhihu.com/question/318439660/ ...