Hive基本原理及配置Mysql作为Hive的默认数据库
Hive是什么?
- Hive是基于Hadoop之上的数据仓库;
- Hive是一种可以存储、查询、分析存储在hadoop中的大规模数据
- Hive定义了简单的类SQL查询语言,成为HQL,它允许熟悉SQL的用户查询数据
- 允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作
- Hive没有专门的数据格式
- Hive:数据仓库。
- Hive:解释器,编译器,优化器等。
- Hive运行时,元数据存储在关系型数据库里面。
1. 为什么选择Hive
- 基于Hadoop的大数据的计算/扩展能力
- 支持SQL like查询语言
- 统一的元数据管理
- 简单编程
2.Hive内部是什么
Hive是建立在Hadoop上的数据仓库基础架构。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,称为QL,它允许熟悉SQL的用户查询数据。同时,这个语言也允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作。
本质上讲,Hive是一个SQL解析引擎,Hive可以把SQL查询转换为MapReduce中的job来运行。Hive有一套映射工具,可以把SQL转换为MapReduce中的job,可以把SQL中的表、字段转换为HDFS中的文件(夹)以及文件中的列。这套映射工具称之为metastore,一般存放在derby、mysql中。
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
Hive在hdfs中的默认位置是/user/hive/warehouse
3. Hive的系统架构

- 用户接口
主要有3个:包括CLI,JDBC/ODBC,WebUI。
CLI,即Shell命令行;
JDBC/ODBC是Hive的Java,与使用传统数据库JDBC的方式类似
WebGUI是通过浏览器访问Hive
- 元数据存储
通常是存储在关系数据库如mysql,derby中。Hive将元数据存储在数据库中(metastore),目前只支持mysql,derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器、执行器
完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。Hive的数据存储在HDFS中,大部分的查询由MapReduce完成(包含*的查询,比如select * from table不会生成MapReduce任务)
- Hadoop
用HDFS进行存储,利用MapReduce进行计算。
- HIVE的架构
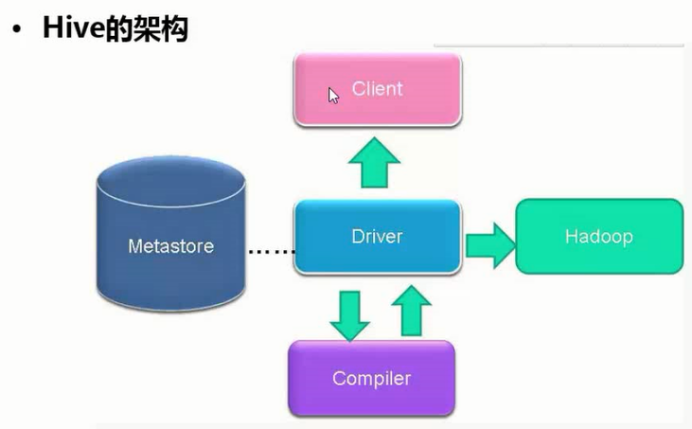
Hive的架构:
——编译器(compiler)将一个Hive QL转换操作符
——操作符是Hive的最小的处理单元
——每个操作符代表HDFS的一个操作或者一道MapReduce作业
Hive的三种模式:
——local模式,此模式连接到一个In-memory的数据块Derby,一般用于Unit Test.
——单用户模式,通过网络连接到一个数据库中,是最经常使用到的模式
——多用户模式,或者远程服务器模式。 用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。
local模式:
单用户模式:

多用户模式:(远程服务器模式)

HIVE的Metastore:
Metastore:hive元数据的集中存放地,metastore默认使用内嵌的derby数据库作为存储引擎。
Derby引擎的缺点,一次只能打开一个会话。
使用Mysql作为外置存储引擎,多用户同时访问。
4. 配置MySql的metastore
PS:metastore默认使用derby数据库作为存储引擎,但是一次只能打开一个会话,修改成Mysql作为外置存储引擎,进行多用户同时访问。
前提:已经安装MYSQL
未安装mysql,可参考文章:https://www.cnblogs.com/wendyw/p/11389741.html
- 1.上传mysql-connector-java-5.1.10.jar到$HIVE_HOME/lib
- 2.登录MYSQL,创建数据库hive
#mysql -uroot -pitcast mysql>create database hive; mysql>GRANT all ON hive.* TO root@'%' IDENTIFIED BY 'itcast'; mysql>flush privileges; mysql>set global binlog_format='MIXED';
- 3.把mysql的数据库字符类型改为latin1
修改$HIVE_HOME/conf/hive-site.xml,其中hadoop表示自己当前虚拟机的主机名,用户名和密码都是mysql登录的用户名、密码,hive-site.xml配置文件如下:
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>itcast</value> </property>
Hive基本原理及配置Mysql作为Hive的默认数据库的更多相关文章
- Hive安装与配置——深入浅出学Hive
第一部分:软件准备与环境规划 Hadoop环境介绍 •Hadoop安装路径 •/home/test/Desktop/hadoop-1.0.0/ •Hadoop 元数据存放目录 •/home/test/ ...
- HIVE配置mysql metastore
HIVE配置mysql metastore hive中除了保存真正的数据以外还要额外保存用来描述库.表.数据的数据,称为hive的元数据.这些元数据又存放在何处呢? 如果不修改配置hive ...
- 1.9 Hive常见属性配置
一.Hive数据仓库位置配置 1. # Hive数据仓库位置配置: 默认位置(hive根目录): /user/hive/warehouse 注意事项: *在仓库目录下,没有对默认的数据库default ...
- spark sql metastore 配置 mysql
本文主要介绍如何为 spark sql 的 metastore 配置成 mysql . spark 的版本 2.4.0 版本 hive script 版本为 hive 1.2.2 mysql 为 5. ...
- CentOS 7安装配置MySQL 5.7
概述 前文记录了在Windows系统中安装配置MySQL 5.7(前文连接:https://www.cnblogs.com/Dcl-Snow/p/10513925.html),由于安装部署大数据环境需 ...
- Hive 2、Hive 的安装配置(本地MySql模式)
一.前提条件 安装了Zookeeper.Hadoop HDFS HA 安装方法: http://www.cnblogs.com/raphael5200/p/5154325.html 二.安装Mysq ...
- Hive初步使用、安装MySQL 、Hive配置MetaStore、配置Hive日志《二》
一.Hive的简单使用 基本的命令和MySQL的命令差不多 首先在 /opt/datas 下创建数据 students.txt 1001 zhangsan 1002 lisi 1003 wangwu ...
- Hive安装与配置--- 基于MySQL元数据
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行. 其优点是学习成本低,可以通过 ...
- hive的安装与配置 mysql安装 启动
三种模式 内嵌模式:元数据保持在内嵌的derby模式,只允许一个会话连接 本地独立模式:在本地安装Mysql,吧元数据放到mySql内 远程模式:元数据放置在远程的Mysql数据库 1.下载Hive安 ...
随机推荐
- 指针常量&常量指针&指向常量的指针常量
搞不懂不吃晚饭 (1)指针常量 指针常量是一个常量,但是是指针修饰的. 格式:int * const p; 例如 int a, b; int * const p = &a;//指针常量 //分 ...
- tp6.0.x 反序列化漏洞
tp6 反序列化漏洞复现 环境 tp6.0 apache php7.3 漏洞分析 反序列化漏洞需要存在 unserialize() 作为触发条件,修改入口文件 app/controller/Index ...
- linux用户的增删改查(useradd/id/usermod/userdel)
与用户(user)相关的配置文件: /etc/passwd 注:用户(user)的配置文件: /etc/shadow 注:用户(user)影子口令文件: 与用户组(group)相关的配置文件: / ...
- NOIP前一些题目的理解
ZYB和售货机(图论,环) 题目链接 个人感觉这道题与基环树没有任何关系,你会发现,每个点最多只有一个入度和出度,所以只能是链或环. 还有就是本题的突破点就在于正确建图,题目的限制保证每个点的入度不大 ...
- 博客新域名www.tecchen.tech
新年祝福 祝新的一年,大朋友实现所有梦想,小朋友健康成长- 新域名 https://www.tecchen.tech 有效期:10年 旧链接 之前的链接请自行替换为新链接地址,包括但不限于以下二级域名 ...
- 使用iOS 设备管理器 iMazing导出苹果设备中的录音文件
iMazing是一款功能强大的苹果设备管理软件,能为用户提供便捷的录音文件导出功能.用户可以直接将录音文件从苹果设备中导出,接下来,就让小编为大家演示一下如何操作吧. 图1:iMazing界面 1.打 ...
- FL Studio里一起安装的ASIO4ALL有什么用?
在我们安装FL Studio时,正常情况下我们安装FL Studio时最多也就改改安装目录,其他的安装设置一般不会动,但看到FL安装的那些东西我们难道不会感到好奇吗?FL Studio安装包括FL S ...
- Vim注释行的方法
目录 一.Visual block 加注释 去注释 二.正则表达式 加注释 去注释 一.Visual block 加注释 1.首先按键盘上的ESC进入命令行模式 2.再按Ctrl+V进入VISUAL ...
- LIKE 运算符
运算符用于执行程序代码运算,会针对一个以上操作数项目来进行运算.例如:2+3,其操作数是2和3,而运算符则是"+".在vb2005中运算符大致可以分为5种类型:算术运算符.连接运算 ...
- SpringBoot2整合Redis
pom.xml <dependency> <groupId>org.springframework.boot</groupId> <artifactId> ...