自适应查询执行:在运行时提升Spark SQL执行性能
前言
Catalyst是Spark SQL核心优化器,早期主要基于规则的优化器RBO,后期又引入基于代价进行优化的CBO。但是在这些版本中,Spark SQL执行计划一旦确定就不会改变。由于缺乏或者不准确的数据统计信息(如行数、不同值的数量、NULL值、最大/最小值等)和对成本的错误估算导致生成的初始计划不理想,从而导致执行效率相对低下。
那么就引来一个思考:我们如何能够在运行时获取更多的执行信息,然后根据这些信息来动态调整并选择一个更优的执行计划呢?
Spark SQL自适应执行优化引擎(Adaptive Query Execution,简称AQE)应运而生,它可以根据执行过程中的中间数据优化后续执行,从而提高整体执行效率。核心在于:通过在运行时对查询执行计划进行优化,允许Spark Planner在运行时执行可选的执行计划,这些计划将基于运行时统计数据进行优化,从而提升性能。
AQE完全基于精确的运行时统计信息进行优化,引入了一个基本的概念Query Stages,并且以Query Stage为粒度,进行运行时的优化,其工作原理如下所示:
由shuffle和broadcast exchange把查询执行计划分为多个query stage,query stage执行完成时获取中间结果
- query stage边界是运行时优化的最佳时机(天然的执行间歇;分区、数据大小等统计信息已经产生)
整个AQE的工作原理以及流程为:
- 运行没有依赖的stage
- 在一个stage完成时再依据新的统计信息优化剩余部分
- 执行其他已经满足依赖的stage
- 重复步骤(2)(3)直至所有stage执行完成
Spark从2.3版本,就开始"试验"SparkSQL自适应查询执行功能(Adaptive Query Execution),并在Spark3.0正式发布。

自适应查询执行框架(AQE)
自适应查询执行最重要的问题之一是何时进行重新优化。Spark算子通常是pipeline化的,并以并行的方式执行。然而shuffle或broadcast exchange会打破这个pipeline。我们称它们为物化点,并使用术语"查询阶段"来表示查询中由这些物化点限定的子部分。每个查询阶段都会物化它的中间结果,只有当运行物化的所有并行进程都完成时,才能继续执行下一个阶段。这为重新优化提供了一个绝佳的机会,因为此时所有分区上的数据统计都是可用的,并且后续操作还没有开始。
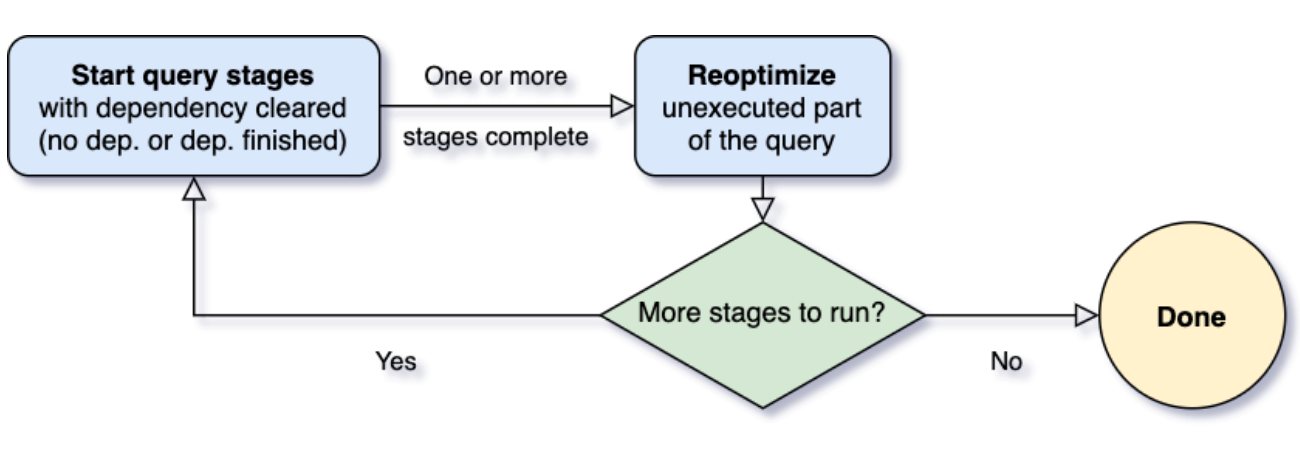
当查询开始时,自适应查询执行框架首先启动所有叶子阶段(leaf stages)—— 这些阶段不依赖于任何其他阶段。一旦其中一个或多个阶段完成物化,框架便会在物理查询计划中将它们标记为完成,并相应地更新逻辑查询计划,同时从完成的阶段检索运行时统计信息。
基于这些新的统计信息,框架将运行优化程序、物理计划程序以及物理优化规则,其中包括常规物理规则(regular physical rules)和自适应执行特定的规则,如coalescing partitions(合并分区)、skew join handling(join数据倾斜处理)等。现在我们有了一个新优化的查询计划,其中包含一些已完成的阶段,自适应执行框架将搜索并执行子阶段已全部物化的新查询阶段,并重复上面的execute-reoptimize-execute过程,直到完成整个查询。
在Spark 3.0中,AQE框架带来了以下三个特性:
- Dynamically coalescing shuffle partitions(动态合并shuffle的分区)可以简化甚至避免调整shuffle分区的数量。用户可以在开始时设置相对较多的shuffle分区数,AQE会在运行时将相邻的小分区合并为较大的分区
- Dynamically switching join strategies(动态调整join策略)在一定程度上避免由于缺少统计信息或着错误估计大小(当然也可能两种情况同时存在),而导致执行次优计划的情况。这种自适应优化可以在运行时sort merge join转换成broadcast hash join,从而进一步提升性能
- Dynamically optimizing skew joins(动态优化数据倾斜的join)skew joins可能导致负载的极端不平衡,并严重降低性能。在AQE从shuffle文件统计信息中检测到任何倾斜后,它可以将倾斜的分区分割成更小的分区,并将它们与另一侧的相应分区连接起来。这种优化可以并行化倾斜处理,获得更好的整体性能。
下面我们来详细介绍这三个特性。
动态合并shuffle的分区
当在Spark中运行查询来处理非常大的数据时,shuffle通常对查询性能有非常重要的影响。shuffle是一个昂贵的操作,因为它需要在网络中移动数据,以便数据按照下游操作所要求的方式重新分布。
分区的数量是shuffle的一个关键属性。分区的最佳数量取决于数据,但是数据大小可能在不同的阶段、不同的查询之间有很大的差异,这使得这个分区数很难调优:
- 如果分区数太少,那么每个分区处理的数据可能非常大,处理这些大分区的任务可能需要将数据溢写到磁盘(例如,涉及排序或聚合的操作),从而减慢查询速度
- 如果分区数太多,那么每个分区处理的数据可能非常小,并且将有大量的网络数据获取来读取shuffle块,这也会由于低效的I/O模式而减慢查询速度。大量的task也会给Spark任务调度程序带来更多的负担
为了解决这个问题,我们可以在开始时设置相对较多的shuffle分区数,然后在运行时通过查看shuffle文件统计信息将相邻的小分区合并为较大的分区。
假设我们运行如下SQL:
SELECT max(i)FROM tbl GROUP BY jtbl表的输入数据相当小,所以在分组之前只有两个分区。我们把初始的shuffle分区数设置为5,因此在shuffle的时候数据被打乱到5个分区中。如果没有AQE,Spark将启动5个task来完成最后的聚合。然而,这里有三个非常小的分区,为每个分区启动一个单独的task将是一种浪费。
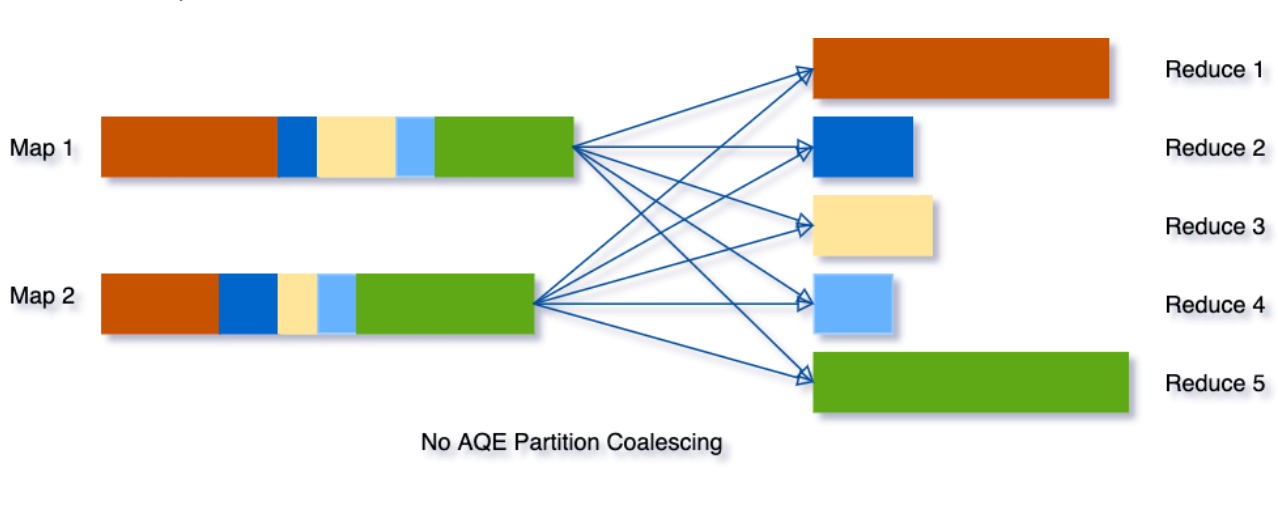
使用AQE之后,Spark将这三个小分区合并为一个,因此,最终的聚合只需要执行3个task,而不是5个task。
动态调整join策略
Spark支持多种join策略(如broadcast hash join、shuffle hash join、sort merge join),通常broadcast hash join是性能最好的,前提是参与join的一张表的数据能够装入内存。由于这个原因,当Spark估计参与join的表数据量小于广播大小的阈值时,它会将join策略调整为broadcast hash join。但是,很多情况都可能导致这种大小估计出错——例如存在一个非常有选择性的过滤器。
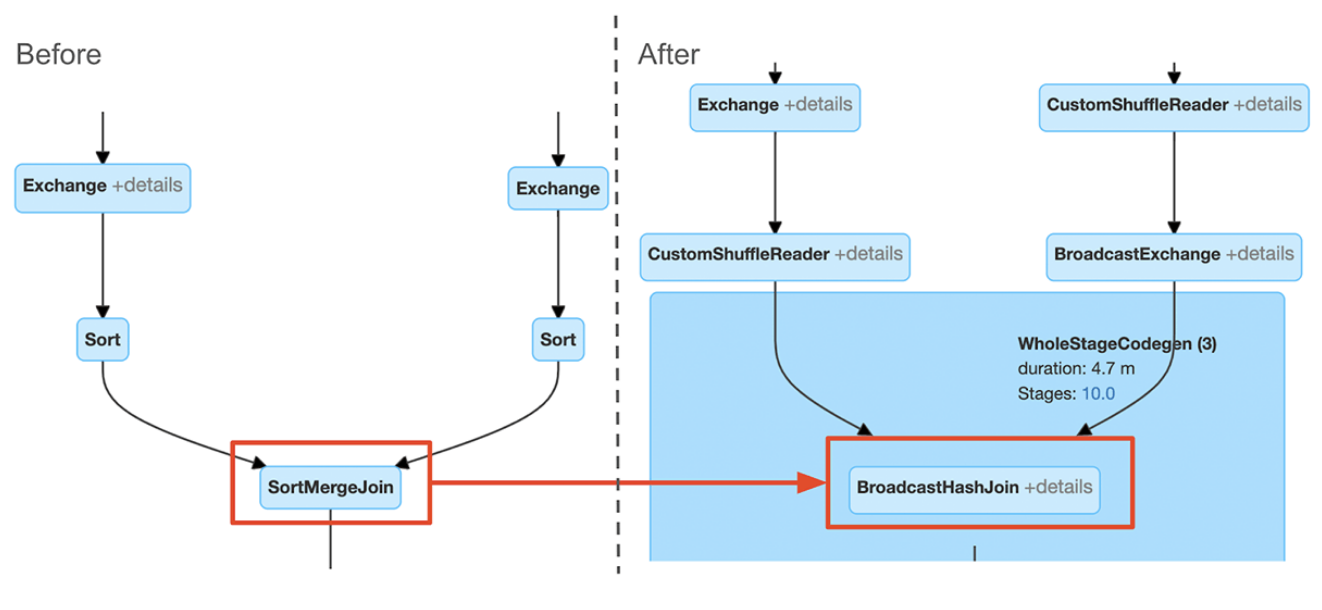
为了解决这个问题,AQE现在根据最精确的连接关系大小在运行时重新规划join策略。在下面的示例中可以看到join的右侧比估计值小得多,并且小到足以进行广播,因此在AQE重新优化之后,静态计划的sort merge join会被转换为broadcast hash join。
对于在运行时转换的broadcast hash join,我们可以进一步将常规的shuffle优化为本地化shuffle来减少网络流量。
动态优化数据倾斜的join
当数据在集群中的分区之间分布不均时,就会发生数据倾斜。严重的倾斜会显著降低查询性能,特别是在进行join操作时。AQE倾斜join优化从shuffle文件统计信息中自动检测到这种倾斜。然后,它将倾斜的分区分割成更小的子分区,这些子分区将分别从另一端连接到相应的分区。
假设表A join 表B,其中表A的分区A0里面的数据明显大于其他分区。
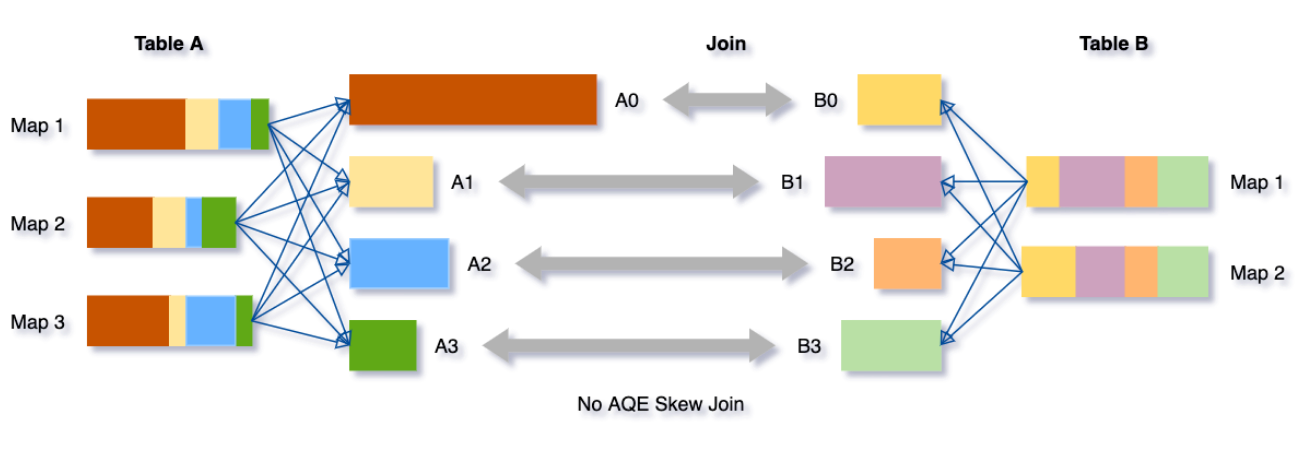


如果没有这个优化,将有四个任务运行sort merge join,其中一个任务将花费非常长的时间。在此优化之后,将有5个任务运行join,但每个任务将花费大致相同的时间,从而获得总体更好的性能。
AQE查询计划
AQE查询计划的一个主要区别是,它通常随着执行的进展而演变。引入了几个AQE特定的计划节点,以提供有关执行的更多详细信息。
此外,AQE使用了一种新的查询计划字符串格式,可以显示初始和最终的查询执行计划。
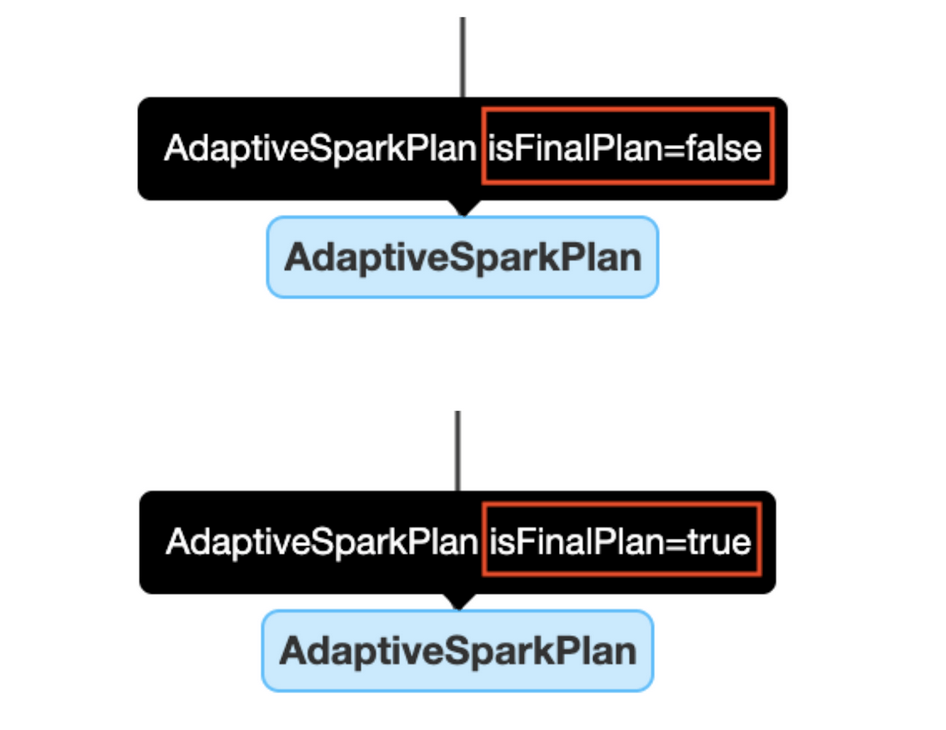
|| AdaptiveSparkPlan节点
应用了AQE的查询通常有一个或多个AdaptiveSparkPlan节点作为每个查询或子查询的root节点。在执行之前或期间,isFinalPlan标志将显示为false。查询完成后,此标志将变为true,并且AdaptiveSparkPlan节点下的计划将不再变化。
|| CustomShuffleReader节点
CustomShuffleReader节点是AQE优化的关键。它可以根据在shuffle map stage收集的统计信息动态调整shuffle后的分区数。在Spark UI中,用户可以将鼠标悬停在该节点上,以查看它应用于无序分区的优化。
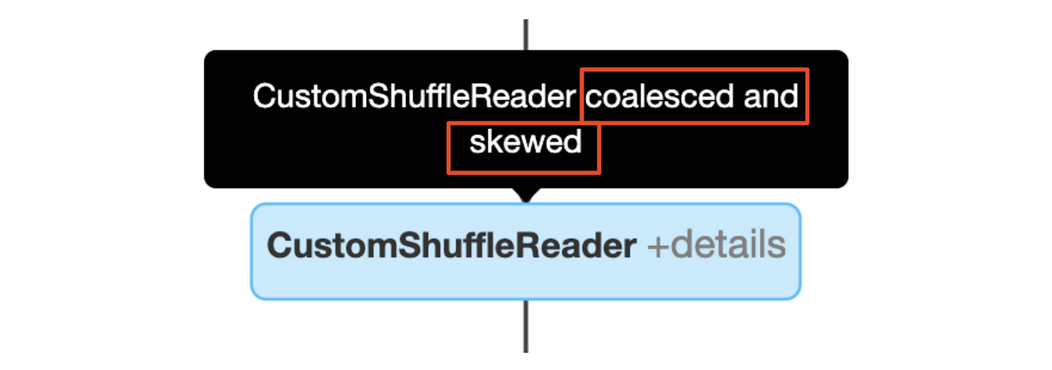
当CustomShuffleReader的标志为coalesced时,表示AQE已根据目标分区大小在shuffle后检测并合并了小分区。此节点的详细信息显示合并后的无序分区数和分区大小。

当CustomShuffleReader的标志为"skewed"时,这意味着AQE在排序合并连接操作之前检测到一个或多个分区中的数据倾斜。此节点的详细信息显示了倾斜分区的数量以及从倾斜分区拆分的新分区的总数。

coalesced和skewed也可以同时发生:
|| 检测join策略改变
通过比较AQE优化前后查询计划join节点的变化,可以识别join策略的变化。在dbr7.3中,AQE查询计划字符串将包括初始计划(应用任何AQE优化之前的计划)和当前或最终计划。这样可以更好地了解应用于查询的优化AQE。

Spark UI将只显示当前计划。为了查看使用Spark UI的效果,用户可以比较查询执行之前和执行完成后的计划图:
|| 检测倾斜join
倾斜连接优化的效果可以通过连接节点名来识别。
在Spark UI中:

在查询计划字符串中:

AQE的TPC-DS表现
在我们使用TPC-DS数据和查询的实验中,自适应查询执行的查询性能提高了8倍,32个查询的性能提高了1.1倍以上。下面是通过AQE获得的10个TPC-DS查询性能提高最多的图表。

这些改进大部分来自动态分区合并和动态join策略调整,因为随机生成的TPC-DS数据没有倾斜。在实际生产中,AQE 带来了更大的性能提升。
启用AQE
可以通过设置参数spark.sql.adaptive为true来启用AQE(在Spark3.0中默认为false)。
如果查询满足以下条件建议启用:
- 不是一个流查询
- 至少包含一个exchange(通常在有join、聚合或窗口操作时)或是一个子查询
通过减少查询优化对静态统计的依赖,AQE解决了Spark基于成本优化的最大难题之一:统计信息收集开销和估计精度之间的平衡。
为了获得最佳的估计精度和规划结果,通常需要维护详细的、最新的统计信息,其中一些统计信息的收集成本很高,比如列直方图,它可用于提高选择性和基数估计或检测数据倾斜。AQE在很大程度上消除了对此类统计数据的需要,以及手动调优工作的需要。
除此之外,AQE还使SQL查询优化对于任意udf和不可预测的数据集更改(例如数据大小的突然增加或减少、频繁的和随机的数据倾斜等)更有弹性。不再需要提前"知道"您的数据。随着查询的运行,AQE将计算出数据并改进查询计划,提高查询性能以获得更快的分析和系统性能。
本文主要参译自:
1.https://databricks.com/blog/2020/05/29/adaptive-query-execution-speeding-up-spark-sql-at-runtime.html
2.https://databricks.com/blog/2020/10/21/faster-sql-adaptive-query-execution-in-databricks.html
关于Spark3.0更多特性,感兴趣的同学建议去Spark官网和Databricks官方博客学习。
关于AQE也可以参考:
https://my.oschina.net/hblt147/blog/3006406
https://www.cnblogs.com/zz-ksw/p/11254294.html
https://issues.apache.org/jira/browse/SPARK-23128
推荐文章:
Apache Spark 3.0.0重磅发布 —— 重要特性全面解析
Spark在处理数据的时候,会将数据都加载到内存再做处理吗?
SparkSQL中产生笛卡尔积的几种典型场景以及处理策略
Spark SQL如何选择join策略
Spark实现推荐系统中的相似度算法
Spark闭包 | driver & executor程序代码执行
Spark SQL | 目前Spark社区最活跃的组件之一
关注大数据学习与分享,获取更多技术干货
自适应查询执行:在运行时提升Spark SQL执行性能的更多相关文章
- Spark修炼之道(进阶篇)——Spark入门到精通:第九节 Spark SQL执行流程解析
1.总体执行流程 使用下列代码对SparkSQL流程进行分析.让大家明确LogicalPlan的几种状态,理解SparkSQL总体执行流程 // sc is an existing SparkCont ...
- 运行时修改TimerTask的执行周期
java.util.TimerTask类的执行周期period变量的声明如下: /** * Period in milliseconds for repeating tasks. A positive ...
- spark sql 执行计划生成案例
前言 一个SQL从词法解析.语法解析.逻辑执行计划.物理执行计划最终转换为可以执行的RDD,中间经历了很多的步骤和流程.其中词法分析和语法分析均有ANTLR4完成,可以进一步学习ANTLR4的相关知识 ...
- delphi 运行时提升软件到管理员权限
//以管理员身份运行procedure RunAsAdmin(hWnd: HWND; aFile: string; aParameters: string);varsei: TShellExecute ...
- spark sql 的性能调优
Caching Data in Memory 其他调优参数
- Spark学习之Spark SQL
一.简介 Spark SQL 提供了以下三大功能. (1) Spark SQL 可以从各种结构化数据源(例如 JSON.Hive.Parquet 等)中读取数据. (2) Spark SQL 不仅支持 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- java 运行时常量、编译时常量、静态块执行顺序
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt223 常量是程序运行时恒定不变的量,许多程序设计语言都有某种方法,向编译器告 ...
- spark sql运行原理
Spark sql 对SQL语句的处理,先将SQL语句进行解析(parse)形成一个tree,然后使用Rule对Tree进行绑定,优化等处理过程,通过模式匹配对不同类型的节点采用不同操作.查询优化器是 ...
随机推荐
- yii2.0验证码的两种实现方式
第一种方式:采用model 1. 模型:Code.php <?phpnamespace app\models; use yii\base\Model;class Code extends Mod ...
- SpringBoot---WebMvcConfigurer详解
1. 简介 2. WebMvcConfigurer接口 2.1 addInterceptors:拦截器 2.2 addViewControllers:页面跳转 2.3 addResourceHandl ...
- ⭐NES.css推荐⭐
今天发现一个有意思的CSS框架,叫NES.css 官网地址:https://nostalgic-css.github.io/NES.css/ gitHub地址:https://github.com/n ...
- Codeforces Round #660 (Div. 2) A、B、C题解
A. Captain Flint and Crew Recruitment #构造 题目链接 题意 定义一类正整数,能够被\(p*q\)表示,其中\(p.q(1<p<q)\)均为素数,称之 ...
- CSUST 第15届 校赛总结
一直想记录一下自己的比赛,却感觉空间说说有点不适,思考了一番还是打算放到自己的博客园 这次比赛总体来说还是不错,签到还是稳的一批,基本前四小时都在rk1 开局切了几道签到题,然后开了一道思维gcd,正 ...
- partial conv
Image Inpainting for Irregular Holes Using Partial Convolutions pytorch代码 论文贡献: 提出了部分卷积(partial conv ...
- 你的Idea还可用吗?不妨试试这个神器!
@ 目录 一.STS安装 1.STS下载 2.STS安装 二.STS使用 1.STS配置JDK 2.STS配置Maven 3.使用STS创建SpringBoot项目 三.优化STS 1.主题美化 2. ...
- virtualProtect函数
原文链接:https://blog.csdn.net/zacklin/article/details/7478118 结合逆向课件11
- 20191226_rpm命令
安装rpm包: [root@localhost ~]# rpm -ivh test.rpm rpm查询命令: [root@localhost ~]# rpm -qa | grep mysql mysq ...
- day8(使用celery异步发送短信)
1.1在celery_task/mian.py中添加发送短信函数 # celery项目中的所有导包地址, 都是以CELERY_BASE_DIR为基准设定. # 执行celery命令时, 也需要进入CE ...