用Python从头开始构建神经网络
 神经网络已经被开发用来模拟人脑。虽然我们还没有做到这一点,但神经网络在机器学习方面是非常有效的。它在上世纪80年代和90年代很流行,最近越来越流行。计算机的速度足以在合理的时间内运行一个大型神经网络。在本文中,我将讨论如何实现一个神经网络。
神经网络已经被开发用来模拟人脑。虽然我们还没有做到这一点,但神经网络在机器学习方面是非常有效的。它在上世纪80年代和90年代很流行,最近越来越流行。计算机的速度足以在合理的时间内运行一个大型神经网络。在本文中,我将讨论如何实现一个神经网络。
我建议你仔细阅读“神经网络的思想”部分。但如果你不太清楚,不要担心。可以转到实现部分。我把它分解成更小的碎片帮助理解。
神经网络的工作原理
在一个简单的神经网络中,神经元是基本的计算单元。它们获取输入特征并将其作为输出。以下是基本神经网络的外观:
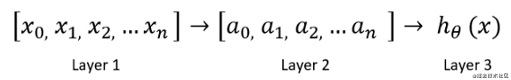
![]()
这里,“layer1”是输入特征。“Layer1”进入另一个节点layer2,最后输出预测的类或假设。layer2是隐藏层。可以使用多个隐藏层。
你必须根据你的数据集和精度要求来设计你的神经网络。
前向传播
从第1层移动到第3层的过程称为前向传播。前向传播的步骤:
为每个输入特征初始化系数θ。比方说,我们有100个训练例子。这意味着100行数据。在这种情况下,如果假设有10个输入特征,我们的输入矩阵的大小是100x10。现在确定θ1θ_1θ1的大小。行数需要与输入特征的数量相同。在这个例子中,是10。列数应该是你选择的隐藏层的大小。
将输入特征X乘以相应的θ,然后添加一个偏置项。通过激活函数传递结果。
有几个激活函数可用,如sigmoid,tanh,relu,softmax,swish
我将使用一个sigmoid激活函数来演示神经网络。
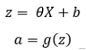
![]()
g(z)是sigmoid激活函数:
为隐藏层初始化θ2\theta_2θ2。大小将是隐藏层的长度乘以输出类的数量。在这个例子中,下一层是输出层,因为我们没有更多的隐藏层。
然后我们需要按照以前一样的流程。将θ和隐藏层相乘,通过sigmoid激活层得到预测输出。
反向传播
反向传播是从输出层移动到第二层的过程。在这个过程中,我们计算了误差。
- 首先,从原始输出y减去预测输出,这就是我们的δ3\delta_3δ3。
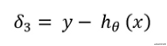
![]()
- 现在,计算θ2\theta_2θ2的梯度。将δ3\delta_3δ3乘以θ2\theta_2θ2。乘以“a2a^2a2”乘以“1−a21-a^21−a2”。在下面的公式中,“a”上的上标2表示第2层。请不要把它误解为平方。
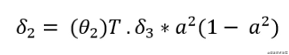
![]()
- 用训练样本数m计算没有正则化版本的梯度δ\deltaδ。
训练网络
修正δ\deltaδ。将输入特征乘以δ2\delta_2δ2乘以学习速率得到θ1\theta_1θ1。请注意θ1\theta_1θ1的维度。
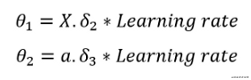
![]()
重复前向传播和反向传播的过程,并不断更新参数,直到达到最佳成本。这是成本函数的公式。只是提醒一下,成本函数表明,预测离原始输出变量有多远。
如果你注意到的话,这个成本函数公式几乎和逻辑回归成本函数一样。
神经网络的实现
我将使用Andrew Ng在Coursera的机器学习课程的数据集。请从以下链接下载数据集:
下面是一个逐步实现的神经网络。我鼓励你自己运行每一行代码并打印输出以更好地理解它。
- 首先导入必要的包和数据集。
import pandas as pd
import numpy as np
xls = pd.ExcelFile('ex3d1.xlsx')
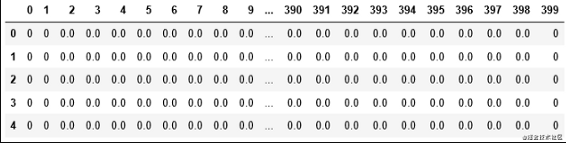
df = pd.read_excel(xls, 'X', header = None)
复制代码![]()
![]()
在这个数据集中,输入和输出变量被组织在单独的excel表格中。让我们导入输出变量:
y = pd.read_excel(xls, 'y', header=None)
复制代码![]()

![]()
这也是数据集的前五行。输出变量是从1到10的数字。这个项目的目标是使用存储在'df'中的输入变量来预测数字。
- 求输入输出变量的维数
df.shape
y.shape
复制代码![]()
输入变量或df的形状为5000 x 400,输出变量或y的形状为5000 x 1。
- 定义神经网络
为了简单起见,我们将只使用一个由25个神经元组成的隐藏层。
hidden_layer = 25
复制代码![]()
得到输出类。
y_arr = y[0].unique()#输出:
array([10, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=int64)
复制代码![]()
正如你在上面看到的,有10个输出类。
- 初始化θ和偏置
我们将随机初始化层1和层2的θ。因为我们有三层,所以会有θ1\theta_1θ1和θ2\theta_2θ2。
θ1\theta_1θ1的维度:第1层的大小x第2层的大小
θ2\theta_2θ2的维度:第2层的大小x第3层的大小
从步骤2开始,“df”的形状为5000 x 400。这意味着有400个输入特征。所以,第1层的大小是400。当我们指定隐藏层大小为25时,层2的大小为25。我们有10个输出类。所以,第3层的大小是10。
θ1\theta_1θ1的维度:400 x 25
θ2\theta_2θ2的维度:25×10
同样,会有两个随机初始化的偏置b1和b2。
b1b_1b1的维度:第2层的大小(本例中为25)
b1b_1b1的维度:第3层的大小(本例中为10)
定义一个随机初始化theta的函数:
def randInitializeWeights(Lin, Lout):
epi = (6**1/2) / (Lin + Lout)**0.5
w = np.random.rand(Lout, Lin)*(2*epi) -epi
return w
复制代码![]()
使用此函数初始化theta
hidden_layer = 25
output =10
theta1 = randInitializeWeights(len(df.T), hidden_layer)
theta2 = randInitializeWeights(hidden_layer, output)
theta = [theta1, theta2]
复制代码![]()
现在,初始化我们上面讨论过的偏置项:
b1 = np.random.randn(25,)
b2 = np.random.randn(10,)
复制代码![]()
- 实现前向传播
使用前向传播部分中的公式。
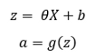
![]()
为了方便起见,定义一个函数来乘以θ和X
def z_calc(X, theta):
return np.dot(X, theta.T)
复制代码![]()
我们也将多次使用激活函数。同样定义一个函数
def sigmoid(z):
return 1/(1+ np.exp(-z))
复制代码![]()
现在我将逐步演示正向传播。首先,计算z项:
z1 =z_calc(df, theta1) + b1
复制代码![]()
现在通过激活函数传递这个z1,得到隐藏层
a1 = sigmoid(z1)
复制代码![]()
a1是隐藏层。a1的形状是5000 x 25。重复相同的过程来计算第3层或输出层
z2 = z_calc(a1, theta2) + b2
a2 = sigmoid(z2)
复制代码![]()
a2的形状是5000 x 10。10列代表10个类。a2是我们的第3层或最终输出。如果在这个例子中有更多的隐藏层,在从一个层到另一个层的过程中会有更多的重复步骤。这种利用输入特征计算输出层的过程称为前向传播。
l = 3 #层数
b = [b1, b2]
def hypothesis(df, theta):
a = []
z = []
for i in range (0, l-1):
z1 = z_calc(df, theta[i]) + b[i]
out = sigmoid(z1)
a.append(out)
z.append(z1)
df = out
return out, a, z
复制代码![]()
- 实现反向传播
这是反向计算梯度和更新θ的过程。在此之前,我们需要修改'y'。我们在“y”有10个类。但我们需要将每个类在其列中分开。例如,针对第10类的列。我们将为10替换1,为其余类替换0。这样我们将为每个类创建一个单独的列。
y1 = np.zeros([len(df), len(y_arr)])
y1 = pd.DataFrame(y1)
for i in range(0, len(y_arr)):
for j in range(0, len(y1)):
if y[0][j] == y_arr[i]:
y1.iloc[j, i] = 1
else:
y1.iloc[j, i] = 0
y1.head()
复制代码![]()
之前我一步一步地演示了向前传播,然后把所有的都放在一个函数中,我将对反向传播做同样的事情。使用上述反向传播部分的梯度公式,首先计算δ3\delta_3δ3。我们将使用前向传播实现中的z1、z2、a1和a2。
del3 = y1-a2
复制代码![]()
现在使用以下公式计算delta2:
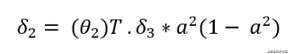
![]()
这里是delta2:
del2 = np.dot(del3, theta2) * a1*(1 - a1)
复制代码![]()
在这里我们需要学习一个新的概念。这是一个sigmoid梯度。sigmoid梯度的公式为:
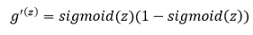
![]()
如果你注意到了,这和delta公式中的**a(1-a)**完全相同。因为a是sigmoid(z)。我们来写一个关于sigmoid梯度的函数:
def sigmoid_grad(z):
return sigmoid(z)*(1 - sigmoid(z))
复制代码![]()
最后,使用以下公式更新θ:
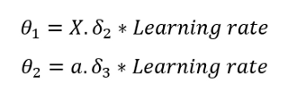
![]()
我们需要选择一个学习率。我选了0.003。我鼓励你尝试使用其他学习率,看看它的表现:
theta1 = np.dot(del2.T, pd.DataFrame(a1)) * 0.003
theta2 = np.dot(del3.T, pd.DataFrame(a2)) * 0.003
复制代码![]()
这就是θ需要更新的方式。这个过程称为反向传播,因为它向后移动。在编写反向传播函数之前,我们需要定义成本函数。因为我会把成本的计算也包括在反向传播方法中。但它是可以添加到前向传播中,或者可以在训练网络时将其分开的。
def cost_function(y, y_calc, l):
return (np.sum(np.sum(-np.log(y_calc)*y - np.log(1-y_calc)*(1-y))))/m
复制代码![]()
这里m是训练实例的数量。综合起来的代码:
m = len(df)
def backpropagation(df, theta, y1, alpha):
out, a, z = hypothesis(df, theta)
delta = []
delta.append(y1-a[-1])
i = l - 2
while i > 0:
delta.append(np.dot(delta[-i], theta[-i])*sigmoid_grad(z[-(i+1)]))
i -= 1
theta[0] = np.dot(delta[-1].T, df) * alpha
for i in range(1, len(theta)):
theta[i] = np.dot(delta[-(i+1)].T, pd.DataFrame(a[0])) * alpha
out, a, z = hypothesis(df, theta)
cost = cost_function(y1, a[-1], 1)
return theta, cost
复制代码![]()
- 训练网络
我将用20个epoch训练网络。我在这个代码片段中再次初始化theta。
theta1 = randInitializeWeights(len(df.T), hidden_layer)
theta2 = randInitializeWeights(hidden_layer, output)
theta = [theta1, theta2]
cost_list = []
for i in range(20):
theta, cost= backpropagation(df, theta, y1, 0.003)
cost_list.append(cost)
cost_list
复制代码![]()
我使用了0.003的学习率并运行了20个epoch。但是请看文章末提供的GitHub链接。我有试着用不同的学习率和不同的epoch数训练模型。
我们得到了每个epoch计算的成本,以及最终更新的θ。用最后的θ来预测输出。
- 预测输出并计算精度
只需使用假设函数并传递更新后的θ来预测输出:
out, a, z = hypothesis(df, theta)
复制代码![]()
现在计算一下准确率,
accuracy= 0
for i in range(0, len(out)):
for j in range(0, len(out[i])):
if out[i][j] >= 0.5 and y1.iloc[i, j] == 1:
accuracy += 1
accuracy/len(df)
复制代码![]()
准确率为100%。完美,对吧?但我们并不是一直都能得到100%的准确率。有时获得70%的准确率是很好的,这取决于数据集。
恭喜!你刚刚开发了一个完整的神经网络!
想学习更多关于python的知识可以加我QQ:2955637827
用Python从头开始构建神经网络的更多相关文章
- 一个 11 行 Python 代码实现的神经网络
一个 11 行 Python 代码实现的神经网络 2015/12/02 · 实践项目 · 15 评论· 神经网络 分享到:18 本文由 伯乐在线 - 耶鲁怕冷 翻译,Namco 校稿.未经许可,禁止转 ...
- 使用 Visual Studio 2015 + Python3.6 + tensorflow 构建神经网络时报错:'utf-8' codec can't decode byte 0xcc in position 78: invalid continuation byte
使用 Visual Studio 2015 + Python3.6 + tensorflow 构建神经网络时报错:'utf-8' codec can't decode byte 0xcc in pos ...
- TFLearn构建神经网络
TFLearn构建神经网络 Building the network TFLearn lets you build the network by defining the layers. Input ...
- 使用pytorch构建神经网络的流程以及一些问题
使用PyTorch构建神经网络十分的简单,下面是我总结的PyTorch构建神经网络的一般过程以及我在学习当中遇到的一些问题,期望对你有所帮助. PyTorch构建神经网络的一般过程 下面的程序是PyT ...
- Tensorflow BatchNormalization详解:2_使用tf.layers高级函数来构建神经网络
Batch Normalization: 使用tf.layers高级函数来构建神经网络 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 吴恩达deeplearningai课程 课程笔 ...
- Python 和 Elasticsearch 构建简易搜索
Python 和 Elasticsearch 构建简易搜索 作者:白宁超 2019年5月24日17:22:41 导读:件开发最大的麻烦事之一就是环境配置,操作系统设置,各种库和组件的安装.只有它们都正 ...
- 笔记13:Python 和 Elasticsearch 构建简易搜索
Python 和 Elasticsearch 构建简易搜索 1 ES基本介绍 概念介绍 Elasticsearch是一个基于Lucene库的搜索引擎.它提供了一个分布式.支持多租户的全文搜索引擎,它可 ...
- Python语言编写BP神经网络
Python语言编写BP神经网络 2016年10月31日 16:42:44 ldy944758217 阅读数 3135 人工神经网络是一种经典的机器学习模型,随着深度学习的发展神经网络模型日益完善 ...
- 分析Python中解析构建数据知识
分析Python中解析构建数据知识 Python 可以通过各种库去解析我们常见的数据.其中 csv 文件以纯文本形式存储表格数据,以某字符作为分隔值,通常为逗号:xml 可拓展标记语言,很像超文本标记 ...
随机推荐
- bash反弹shell检测
1.进程 file descriptor 异常检测 检测 file descriptor 是否指向一个socket 以重定向+/dev/tcp Bash反弹Shell攻击方式为例,这类反弹shell的 ...
- yii\web\Request::cookieValidationKey must be configured with a secret key.
yii\web\Request::cookieValidationKey must be configured with a secret key. 出现的错误表示没有设置 cookieValida ...
- Java蓝桥杯——排序练习:选美大赛
选美大赛 在选美大奖赛的半决胜赛现场,有一批选手参加比赛,比赛的规则是最后得分越高,名次越低.当半决决赛结束时,要在现场按照选手的出场顺序宣布最后得分和最后名次,获得相同分数的选手具有相同的名次,名次 ...
- Java基础教程——字符流
字符流 字节流服务文本文件时,可能出现中文乱码.因为一个中文字符可能占用多个字节. 针对于非英语系的国家和地区,提供了一套方便读写方式--字符流. java.io.Reader java.io.Wri ...
- 【MySQL/C#/.NET】VS2010报错--“.Net Framework Data Provider。可能没有安装。”
前言 公司行业是金融软件,之前用的都是Oracle数据库.Oracle数据库用一个词来形容:大而全.MySQL的话,可能是因为开源.便宜,现在越来越主流. 我们也支持MySQL数据库,不过平时不用.最 ...
- VS Code C++ 项目快速配置模板
两个月前我写过一篇博客 Windows VS Code 配置 C/C++ 开发环境 ,主要介绍了在 VS Code 里跑简单 C 程序的一些方法.不过那篇文章里介绍的方法仅适用于单文件程序,所以稍微大 ...
- 04_ Broadcast Receiver
Broadcast是广播,和Android内的事件一样,它可以发出一个广播(事件),注册了该广播接收器(事件监听器)的所有组件都会接收到该广播,从而调用自己的响应方法(事件响应处理). 下面将详细的阐 ...
- Appium之测试微信小程序
坚持原创输出,点击蓝字关注我吧 作者:清菡 博客:Oschina.云+社区.知乎等各大平台都有. 目录 一.往期回顾 二.测试微信小程序 1.准备工作 2.操作步骤 3.注意 4.强制设置安卓的进程 ...
- crash安装使用
cash作为Linux内核调试的工具是必不可少少的一部分,但是他的下载并不是 yum install一下这么简单的,本文就来讲一下如何安装crash进行调试. 首先就是了解Linux的内核版本.这 ...
- linux scp 命令使用
1.scp命令使用 linux 把文件复制到另一台服务器上 复制文件 scp file_name user_name@remote_ip:file_path 复制文件夹 scp -r file_nam ...