Datanode 怎么与 Namenode 通信?
在分析DataNode时, 因为DataNode上保存的是数据块, 因此DataNode主要是对数据块进行操作.
A. DataNode的主要工作流程
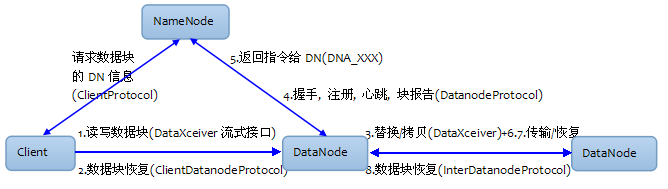
- 客户端和DataNode的通信: 客户端向DataNode的
数据块读写, 采用TCP/IP流接口(DataXceiver)进行数据传输 - 客户端在检测到DataNode异常, 主动发起的
数据块恢复, 客户端会通过ClientDatanodeProtocol接口采用RPC调用的方式和DataNode通信. 数据块替换和拷贝, 由负载均衡器Balancer发起的, 是发生在DataNode之间. 也是通过DataXceiver进行数据传输- DataNode在启动后会向NameNode分别完成:
握手, 注册, 心跳, 块报告. - NameNode根据DataNode的块报告和心跳, 会返回给DataNode
指令. 通过这种方式NameNode间接地和DataNode进行通信.
实际上NameNode作为Server端, 是不会主动去联系DataNode的, 只有作为客户端的DataNode才会去联系NameNode.
DataNode在接收到NameNode的指令信息, 被要求去做: 重新向NameNode注册, 数据块传输, 恢复等. - NameNode检测到数据块的副本个数不足. 要求DN执行
数据块传输(DNA_TRANSFERBLOCK), DataNode使用DataTransfer也是基于DataXceiver流接口. - NameNode发起的数据块恢复(DNA_RECOVERBLOCK), 是检测到客户端/租约错误, 恢复策略是选取参与到恢复过程中的数据块的最小长度.
- 不管是客户端错误会被NN返回数据块恢复命令给DN执行恢复操作, 还是DN错误由客户端主动触发的数据块恢复操作. 都会使用到
InterdatanodeProtocol的两个数据块恢复方法(startBlockRecovery和updateBlock).
因为数据块恢复实际上是在DN之间根据恢复策略恢复到数据块正常的状态. 而且恢复时不像写数据没有数据来源. 所以是在DN之间进行通信.
B. 从DataNode的功能来看:
- DataNode实现的两个接口ClientDatanodeProtocol和InterDatanodeProtocol都用于数据块恢复.
- 数据块的其他操作使用TCP/IP流式接口来完成: DataXceiver(读写, 替换, 复制)和DataTransfer(传输).
C. 从DataNode的通信来看:
- 客户端可以向DataNode发起读写数据块请求, 主动发起数据块恢复.
- DataNode向NameNode握手, 注册, 心跳, 块报告. 并接收NameNode的指令.
原文出处:https://www.cnblogs.com/30go/
Datanode 怎么与 Namenode 通信?的更多相关文章
- rpc,客户端与NameNode通信的过程
远程过程:java进程.即一个java进程调用另外一个java进程中对象的方法. 调用方称作客户端(client),被调用方称作服务端(server).rpc的通信在java中表现为客户端去调用服务端 ...
- NameNode与DataNode的工作原理剖析
NameNode与DataNode的工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS写数据流程 >.客户端通过Distributed FileSyst ...
- Secondary NameNode:的作用?
前言 最近刚接触Hadoop, 一直没有弄明白NameNode和Secondary NameNode的区别和关系.很多人都认为,Secondary NameNode是NameNode的备份,是为了防止 ...
- 一探究竟:Namenode、SecondaryNamenode、NamenodeHA关系
NameNode与Secondary NameNode 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止NameNode的单点失败的,其实并不是在这样.文章Sec ...
- 解读Secondary NameNode的功能
1.概述 最近有朋友问我Secondary NameNode的作用,是不是NameNode的备份?是不是为了防止NameNode的单点问题?确实,刚接触Hadoop,从字面上看,很容易会把Second ...
- Secondary NameNode 的作用
https://blog.csdn.net/xh16319/article/details/31375197 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止Na ...
- (转)Secondary NameNode的作用
在Hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一.从它的名字上看,它给人的感觉就像是NameNode的备份.但它实际上却不是.很多Hadoop的初学者都很疑惑,S ...
- 【Hadoop】Hadoop DataNode节点超时时间设置
hadoop datanode节点超时时间设置 datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间 ...
- hadoop datanode节点超时时间设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长. HDFS默认的超时时长为10分 ...
随机推荐
- SpringBoot之整合Quartz调度框架-基于Spring Boot2.0.2版本
1.项目基础 项目是基于Spring Boot2.x版本的 2.添加依赖 <!-- quartz依赖 --> <dependency> <groupId>org.s ...
- MacOS SVN简单入门
背景:MacOS内置了SVN的客户端和服务器端的软件,下边所使用到的目录需要结合自己电脑的具体情况进行设置,并不是很困难. MacOS SVN简单入门 第一部分,创建本地的SVN测试仓库,并修改相应的 ...
- 配置mongoDB的错误
1,将启动配置到服务的时候没有反应,后来发现没有用管理员模式打开shell命令,所以没有反应. 2,用管理员模式的时候报错 格式问题,将由空格的路径用“”包住即可 3.启动的时候报错windows不能 ...
- Python pass语句
Python pass语句:空语句,主要用于保持程序结构的完整性 或者 函数想要添加某种功能,但是还没有想好具体应该怎么写. 在 for 循环中使用 pass: lst = [7,8,9,4] for ...
- Python os.fstatvfs() 方法
概述 os.fstatvfs() 方法用于返回包含文件描述符fd的文件的文件系统的信息,类似 statvfs().高佣联盟 www.cgewang.com Unix上可用. fstatvfs 方法返回 ...
- PHP exit() 函数
实例 输出一条消息,并退出当前脚本: <?php$site = "http://www.w3cschool.cc/";fopen($site,"r")or ...
- PHP strripos() 函数
实例 查找 "php" 在字符串中最后一次出现的位置: <?php高佣联盟 www.cgewang.comecho strripos("I love php, I ...
- 关于双线性插值中重叠像素与空白像素掩膜函数的一种迭代batch的写法
from __future__ import division import matplotlib.pyplot as plt import numpy as np import tensorflow ...
- 025_go语言中的通道同步
代码演示 package main import "fmt" import "time" func worker(done chan bool) { fmt.P ...
- “随手记”开发记录day03
今天完成了进入页面 还有记账页面 出现的问题,在登录页面中由于布局采用的错误 后边的view把前面的view遮住,看不出来,我们查找方法,找到了设置权重的办法解决 明天打算完成加号里面的内容