Datanode 怎么与 Namenode 通信?
在分析DataNode时, 因为DataNode上保存的是数据块, 因此DataNode主要是对数据块进行操作.
A. DataNode的主要工作流程
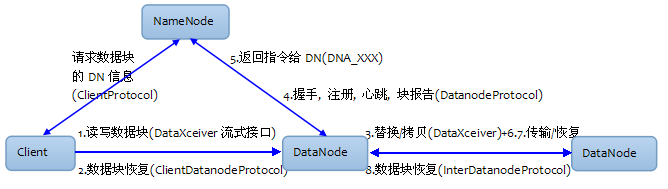
- 客户端和DataNode的通信: 客户端向DataNode的
数据块读写, 采用TCP/IP流接口(DataXceiver)进行数据传输 - 客户端在检测到DataNode异常, 主动发起的
数据块恢复, 客户端会通过ClientDatanodeProtocol接口采用RPC调用的方式和DataNode通信. 数据块替换和拷贝, 由负载均衡器Balancer发起的, 是发生在DataNode之间. 也是通过DataXceiver进行数据传输- DataNode在启动后会向NameNode分别完成:
握手, 注册, 心跳, 块报告. - NameNode根据DataNode的块报告和心跳, 会返回给DataNode
指令. 通过这种方式NameNode间接地和DataNode进行通信.
实际上NameNode作为Server端, 是不会主动去联系DataNode的, 只有作为客户端的DataNode才会去联系NameNode.
DataNode在接收到NameNode的指令信息, 被要求去做: 重新向NameNode注册, 数据块传输, 恢复等. - NameNode检测到数据块的副本个数不足. 要求DN执行
数据块传输(DNA_TRANSFERBLOCK), DataNode使用DataTransfer也是基于DataXceiver流接口. - NameNode发起的数据块恢复(DNA_RECOVERBLOCK), 是检测到客户端/租约错误, 恢复策略是选取参与到恢复过程中的数据块的最小长度.
- 不管是客户端错误会被NN返回数据块恢复命令给DN执行恢复操作, 还是DN错误由客户端主动触发的数据块恢复操作. 都会使用到
InterdatanodeProtocol的两个数据块恢复方法(startBlockRecovery和updateBlock).
因为数据块恢复实际上是在DN之间根据恢复策略恢复到数据块正常的状态. 而且恢复时不像写数据没有数据来源. 所以是在DN之间进行通信.
B. 从DataNode的功能来看:
- DataNode实现的两个接口ClientDatanodeProtocol和InterDatanodeProtocol都用于数据块恢复.
- 数据块的其他操作使用TCP/IP流式接口来完成: DataXceiver(读写, 替换, 复制)和DataTransfer(传输).
C. 从DataNode的通信来看:
- 客户端可以向DataNode发起读写数据块请求, 主动发起数据块恢复.
- DataNode向NameNode握手, 注册, 心跳, 块报告. 并接收NameNode的指令.
原文出处:https://www.cnblogs.com/30go/
Datanode 怎么与 Namenode 通信?的更多相关文章
- rpc,客户端与NameNode通信的过程
远程过程:java进程.即一个java进程调用另外一个java进程中对象的方法. 调用方称作客户端(client),被调用方称作服务端(server).rpc的通信在java中表现为客户端去调用服务端 ...
- NameNode与DataNode的工作原理剖析
NameNode与DataNode的工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS写数据流程 >.客户端通过Distributed FileSyst ...
- Secondary NameNode:的作用?
前言 最近刚接触Hadoop, 一直没有弄明白NameNode和Secondary NameNode的区别和关系.很多人都认为,Secondary NameNode是NameNode的备份,是为了防止 ...
- 一探究竟:Namenode、SecondaryNamenode、NamenodeHA关系
NameNode与Secondary NameNode 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止NameNode的单点失败的,其实并不是在这样.文章Sec ...
- 解读Secondary NameNode的功能
1.概述 最近有朋友问我Secondary NameNode的作用,是不是NameNode的备份?是不是为了防止NameNode的单点问题?确实,刚接触Hadoop,从字面上看,很容易会把Second ...
- Secondary NameNode 的作用
https://blog.csdn.net/xh16319/article/details/31375197 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止Na ...
- (转)Secondary NameNode的作用
在Hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一.从它的名字上看,它给人的感觉就像是NameNode的备份.但它实际上却不是.很多Hadoop的初学者都很疑惑,S ...
- 【Hadoop】Hadoop DataNode节点超时时间设置
hadoop datanode节点超时时间设置 datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间 ...
- hadoop datanode节点超时时间设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长. HDFS默认的超时时长为10分 ...
随机推荐
- 微服务迁移记(五):WEB层搭建(3)-FreeMarker集成
一.redis搭建 二.WEB层主要依赖包 三.FeignClient通用接口 以上三项,参考<微服务迁移记(五):WEB层搭建(1)> 四.SpringSecurity集成 参考:< ...
- 11-Pandas之排序(df.sort_index()、df.sort_values()、随机重排、随机采样)
排序是一种索引机制的一种常见的操作方法,也是Pandas重要的内置运算,主要包括以下3种方法: 排序方法 说明 sort_values() 根据某一列的值进行排序 sort_index() 根据索引进 ...
- PHP date_default_timezone_get() 函数
------------恢复内容开始------------ 实例 返回默认时区: <?phpecho date_default_timezone_get();?> 运行实例 » 定义和用 ...
- PHP password_verify() 函数
password_verify() 函数用于验证密码是否和散列值匹配. PHP 版本要求: PHP 5 >= 5.5.0, PHP 7高佣联盟 www.cgewang.com 语法 bool p ...
- luogu P5043 【模板】树同构 hash 最小表示法
LINK:模板 树同构 题目说的很迷 给了一棵有根树 但是重新标号 言外之意还是一棵无根树 然后要求判断是否重构. 由于时无根的 所以一个比较显然的想法暴力枚举根. 然后做树hash或者树的最小表示法 ...
- 服务没有报告任何错误。 请键入 NET HELPMSG 3534 以获得更多的帮助。
解决: 删除data文件夹 然后按顺序执行: sc delete mysql mysqld --initialize-insecure mysqld -install mysql net start ...
- Use SQL to Query Data from CDS and Dynamics 365 CE
from : https://powerobjects.com/2020/05/20/use-sql-to-query-data-from-cds-and-dynamics-365-ce/ Have ...
- MR程序的几种提交运行模式
本地模式运行 1-在windows的eclipse里面直接运行main方法 将会将job提交给本地执行器localjobrunner 输入输出数据可以放在本地路径下 输入输出数据放在HDFS中:(hd ...
- Centos xrdp 远程连接后突然闪退
问题描述: 可以进入登录页面,但是输入用户名,密码后,直接闪退. 查看 该用户名 ~/.xsession-errors imsettings-check: ): IMSettings-WARNING ...
- HTML学习笔记(一)——基础标签及常用编辑器技巧
HTML 初识html 什么是html? html是超文本标记语言(hyper text markup language) html5的基本结构 <!DOCTYPE html> <! ...