Spark优化之小文件是否需要合并?
我们知道,大部分Spark计算都是在内存中完成的,所以Spark的瓶颈一般来自于集群(standalone, yarn, mesos, k8s)的资源紧张,CPU,网络带宽,内存。Spark的性能,想要它快,就得充分利用好系统资源,尤其是内存和CPU。有时候我们也需要做一些优化调整来减少内存占用,例如将小文件进行合并的操作。
一、问题现象
我们有一个15万条总数据量133MB的表,使用SELECT * FROM bi.dwd_tbl_conf_info全表查询耗时3min,另外一个500万条总数据量6.3G的表ods_tbl_conf_detail,查询耗时23秒。两张表均为列式存储的表。
大表查询快,而小表反而查询慢了,为什么会产生如此奇怪的现象呢?
二、问题探询
数据量6.3G的表查询耗时23秒,反而数据量133MB的小表查询耗时3min,这非常奇怪。我们收集了对应的建表语句,发现两者没有太大的差异,大部分为String,两表的列数也相差不大。
CREATE TABLE IF NOT EXISTS `bi`.`dwd_tbl_conf_info` (
`corp_id` STRING COMMENT '',
`dept_uuid` STRING COMMENT '',
`user_id` STRING COMMENT '',
`user_name` STRING COMMENT '',
`uuid` STRING COMMENT '',
`dtime` DATE COMMENT '',
`slice_number` INT COMMENT '',
`attendee_count` INT COMMENT '',
`mr_id` STRING COMMENT '',
`mr_pkg_id` STRING COMMENT '',
`mr_parties` INT COMMENT '',
`is_mr` TINYINT COMMENT 'R',
`is_live_conf` TINYINT COMMENT ''
)
CREATE TABLE IF NOT EXISTS `bi`.`ods_tbl_conf_detail` (
`id` string,
`conf_uuid` string,
`conf_id` string,
`name` string,
`number` string,
`device_type` string,
`j_time` bigint,
`l_time` bigint,
`media_type` string,
`dept_name` string,
`UPDATETIME` bigint,
`CREATETIME` bigint,
`user_id` string,
`USERAGENT` string,
`corp_id` string,
`account` string
)
因为两张表均为很简单的SELECT查询操作,无任何复杂的聚合join操作,也无UDF相关的操作,所以基本确认查询慢的应该发生的读表的时候,我们将怀疑的点放到了读表操作上。通过查询两个查询语句的DAG和任务分布,我们发现了不一样的地方。
查询快的表,查询时总共有68个任务,任务分配比如均匀,平均7~9s左右,而查询慢的表,查询时总共1160个任务,平均也是9s左右。如下图所示:
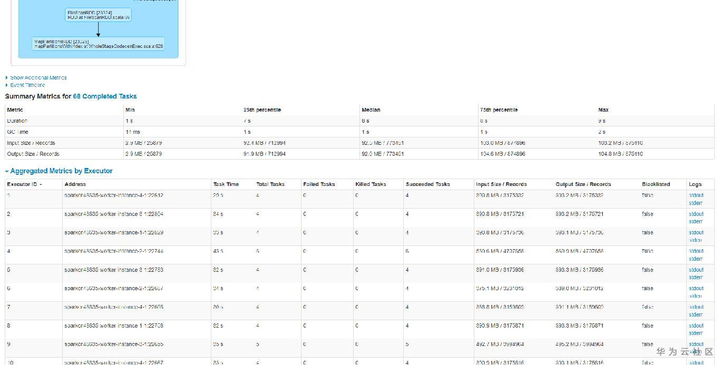
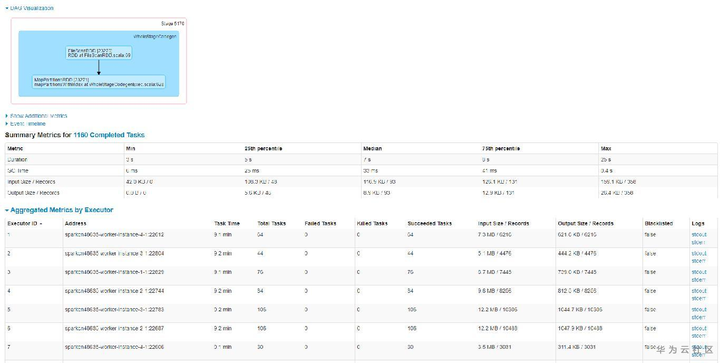
至此,我们基本发现了猫腻所在。大表6.3G但文件个数小,只有68个,所以很快跑完了。而小表虽然只有133MB,但文件个数特别多,导致产生的任务特别多,而由于单个任务本身比较快,大部分时间花费在任务调度上,导致任务耗时较长。
那如何才能解决小表查询慢的问题呢?
三、业务调优
那现在摆在我们面前就存在现在问题:
1、为什么小表会产生这么小文件
2、已经产生的这么小文件如何合并
带着这两个问题,我们和业务的开发人员聊了一个发现小表是业务开发人员从原始数据表中,按照不同的时间切片查询并做数据清洗后插入到小表中的,而由于时间切片切的比较小,导致这样的插入次数特别多,从而产生了大量的小文件。
那么我们需要解决的问题就是2个,如何才能把这些历史的小文件进行合并以及如何才能保证后续的业务流程中不再产生小文件,我们指导业务开发人员做了以下优化:
1)使用INSERT OVERWRITE bi.dwd_tbl_conf_info SELECT * FROM bi.dwd_tbl_conf_info合并下历史的数据。由于DLI做了数据一致性保护,OVERWRITE期间不影响原有数据的读取和查询,OVERWRITE之后就会使用新的合并后的数据。合并后全表查询由原来的3min缩短到9s内完成。
2)原有表修改为分区表,插入时不同时间放入到不同分区,查询时只查询需要的时间段内的分区数据,进一步减小读取数据量。
Spark优化之小文件是否需要合并?的更多相关文章
- hive优化之小文件合并
文件数目过多,会给HDFS带来压力,并且会影响处理效率,可以通过合并Map和Reduce的结果文件来消除这样的影响: set hive.merge.mapfiles = true ##在 map on ...
- spark sql/hive小文件问题
针对hive on mapreduce 1:我们可以通过一些配置项来使Hive在执行结束后对结果文件进行合并: 参数详细内容可参考官网:https://cwiki.apache.org/conflue ...
- CEPH RGW 设置 user default_placement为ssd-placement,优化100KB-200KB小文件性能,使用户创建的bucket对象放置到 SSD设备的Pool上。
sudo radosgw-admin metadata get user:tuanzi > user.md.json vi user.md.json #to add ssd-placement ...
- hive小文件合并设置参数
Hive的后端存储是HDFS,它对大文件的处理是非常高效的,如果合理配置文件系统的块大小,NameNode可以支持很大的数据量.但是在数据仓库中,越是上层的表其汇总程度就越高,数据量也就越小.而且这些 ...
- 合并hive/hdfs小文件
磁盘: heads/sectors/cylinders,分别就是磁头/扇区/柱面,每个扇区512byte(现在新的硬盘每个扇区有4K) 文件系统: 文件系统不是一个扇区一个扇区的来读数据,太慢了,所以 ...
- Hive merge(小文件合并)
当Hive的输入由非常多个小文件组成时.假设不涉及文件合并的话.那么每一个小文件都会启动一个map task. 假设文件过小.以至于map任务启动和初始化的时间大于逻辑处理的时间,会造成资源浪费.甚至 ...
- 海量小文件存储与Ceph实践
海量小文件存储(简称LOSF,lots of small files)出现后,就一直是业界的难题,众多博文(如[1])对此问题进行了阐述与分析,许多互联网公司也针对自己的具体场景研发了自己的存储方案( ...
- Hadoop案例(六)小文件处理(自定义InputFormat)
小文件处理(自定义InputFormat) 1.需求分析 无论hdfs还是mapreduce,对于小文件都有损效率,实践中,又难免面临处理大量小文件的场景,此时,就需要有相应解决方案.将多个小文件合并 ...
- 解决HDFS小文件带来的计算问题
hive优化 一.小文件简述 1.1. HDFS上什么是小文件? HDFS存储文件时的最小单元叫做Block,Hadoop1.x时期Block大小为64MB,Hadoop2.x时期Block大小为12 ...
随机推荐
- 浏览器如何执行JS
作为JS系列的第一篇,内容当然是浏览器如何执行一段JS啦. 首先通过浏览器篇我们可以得知,JS是在渲染进程里的JS引擎线程执行的.在此之后还要了解几个概念,编译器(Compiler).解释器(Inte ...
- 题解 CF585F 【Digits of Number Pi】
考虑用数位 \(DP\) 来统计数字串个数,用 \(SAM\) 来实现子串的匹配. 设状态 \(f(pos,cur,lenth,lim,flag)\),表示数位的位数,在 \(SAM\) 上的节点,匹 ...
- Java 并发队列 BlockingQueue
BlockingQueue 开篇先介绍下 BlockingQueue 这个接口的规则,后面再看其实现. 首先,最基本的来说, BlockingQueue 是一个先进先出的队列(Queue),为什么说是 ...
- EOJ Monthly 2019.11 A(进制转换)
"欢迎您乘坐东方航空公司航班 MU5692 由银川前往上海......" "我们的飞机很快就要起飞了,请收起小桌板,摘下耳机......" 收起了小桌板,摘下了 ...
- I 2 C、 SPI、 USB驱动架构
根据图12.4, Linux倾向于将主机端的驱动与外设端的驱动分离, 而通过一个核心层将某种总线的协议进行抽象, 外设端的驱动调用核心层API间接过渡到对主机驱动传输函数的调用. 对于I 2 C. S ...
- xctf-pwn level3
这道题研究了很久,总算是理解了got表和plt表的关系和作用 checksec看防护 main函数里提示了vunlnerable函数 查看一下vulnerable函数 可以利用read函数栈溢出,但是 ...
- 日志分析-利用grep,awk等文本处理工具完成(2019-4-9)
0x00 基础日志分析命令 1. tail - 监控末尾日志的变化 $tail -n 10 error2019.log #显示最后10行日志内容 $tail -n +5 nginx2019.log # ...
- python Scrapy 从零开始学习笔记(二)
在之前的文章中我们简单了解了一下Scrapy 框架和安装及目录的介绍,本章我们将根据 scrapy 框架实现博客园首页博客的爬取及数据处理. 我们先在自定义的目录中通过命令行来构建一个 scrapy ...
- 02_Linux实操篇
第五章 VI和VIM编辑器 5.1. VI和VIM基本介绍 Vi编辑器是所有Unix及Linux系统下标准的编辑器,它的强大不逊色于任何最新的文本编辑器.由于对Unix及Linux系统的任何版本,Vi ...
- PHP array_uintersect_uassoc() 函数
实例 比较两个数组的键名和键值(使用用户自定义函数进行比较),并返回交集: <?phpfunction myfunction_key($a,$b){if ($a===$b){return 0;} ...